
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- DFS
- Semantic Segmentation
- Python
- 튜토리얼
- 엘리스
- 나는 리뷰어다
- 큐
- TEAM-EDA
- 스택
- 프로그래머스
- Machine Learning Advanced
- 나는리뷰어다
- 추천시스템
- Object Detection
- pytorch
- TEAM EDA
- eda
- 파이썬
- 알고리즘
- Recsys-KR
- MySQL
- hackerrank
- Image Segmentation
- 코딩테스트
- 한빛미디어
- 협업필터링
- 입문
- Segmentation
- 3줄 논문
- DilatedNet
- Today
- Total
목록EDA Study/머신러닝 (10)
TEAM EDA
정형 데이터에서 범주형 변수를 처리하는 방법은 되게 까다롭습니다. 이번 포스팅에서는 제가 알고 있는 범주형 변수들에 대해서 설명하고 어떤 의미를 가지고있는지에 대해 작성해보도록 하겠습니다. 먼저 범주형 변수란 일종의 카테고리를 가지는 변수를 의미합니다. 예를들어 식물의 종도 일종의 카테고리가 되고 음식점의 종류 등 어떠한 집단을 의미하는 변수들을 의미합니다. 이러한 변수들은 컴퓨터가 인식할 수 없기에 인식할 수 있도록 인코딩을 해주는 작업이 필요합니다. 대표적으로 많이 알려진 인코딩 기법으로는 One-Hot Encoding, Label Encoding, Frequency Encoding, Target Encoding 등이 있습니다. 먼저, One-Hot Encoding은 일종의 변수를 1과 0으로 나누는..
 Dataprep.eda : Accelerate your EDA (EDA 자동화 패키지)
Dataprep.eda : Accelerate your EDA (EDA 자동화 패키지)
원문 아티클 : https://towardsdatascience.com/dataprep-eda-accelerate-your-eda-eb845a4088bc 해당 글은 Slavvy Coelho의 Dataprep.eda: Accelerate your EDA을 번역한 글입니다. 이미지 출처 : MicroStockHub, via: Getty Images/iStockphoto Authors: Slavvy Coelho, Ruchita Rozario Mentor: Dr. Jiannan Wang, Director, SFU’s Professional Master’s Programs (Big Data and Cybersecurity and Visual Computing) "숫자는 중요한 이야기를 가집니다. 또한 당신에게 명..
 임베딩 기법(Embedding)
임베딩 기법(Embedding)
본 글은 자연어 처리에서 주로 사용하는 임베딩 기법들에 대해 정리해놓은 자료입니다. One-hot Encoding, TF-IDF, LSA, Word2Vec, Glove, FastText에 대해 정리할 것이고 ratsgo님의 블로그을 많이 참고하였습니다. 목차 One Hot Encoding TF-IDF LSA Word2Vec Glove FastText One Hot Encoding 개념 : 각 단어에 Index를 부여하는 방식으로 표현하는 단어의 Index에 1을 넣고 그렇지 않은 곳 에는 0을 넣는 방법 장점 : 사용하기 매우 쉬움. pandas의 get_dummies함수나 sklearn의 preprocessing.OneHotEncoder을 사용하면 됨 단점 : 단어의 의미를 전혀 이해하지 못함. 단어의..
 교호작용
교호작용
본 글은 피처 엔지니어링 및 선택 : 예측 모델에 대한 실용적인 접근 방식 (https://bookdown.org/max/FES/detecting-interaction-effects.html) 에서 있는 교호작용 효과 감지라는 내용을 기반으로 다른 자료들을 추가해 정리한 자료입니다. 1. 상호 작용 파생시 고려 사항 교호작용이란 A의 효과가 B의 서로 다른 수준 B1과 B2에서 일관성 있게 나타난다면 두 인자 A, B 간에는 교호작용이 없다고 하고, 만일 B가 ‘B1수준에 있을 때 A의 효과’와 ‘B2수준에 있을 때 A의 효과’간에 차이가 있을 때, A, B 간에 교호작용이 존재한다고 입니다. Neter et al.(1996)은 "가능할 때마다 반응 변수에 중요한 방식으로 영향을 줄 수 있는 상호 작용을..
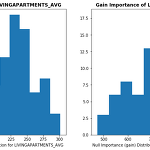 Feature selection using target permutation (Null Importance)
Feature selection using target permutation (Null Importance)
Feature selection using target permutation (Null Importance) 아래의 글은 Olivier의 feature selection with null importances를 번역한 글입니다. 논문 https://academic.oup.com/bioinformatics/article/26/10/1340/193348 원문 링크 https://www.kaggle.com/ogrellier/feature-selection-with-null-importances 이 Notebook 파일은 다음의 논문 를 토대로 만든 자료입니다. kaggle의 Home Credit Default Risk 라는 대회에서 변수 제거를 하기 위해 만들어진 커널 입니다. Null Importance F..
원문 아티클 : Attn: Illustrated Attention Attn: Illustrated Attention GIFs를 활용한 기계번역(ex. 구글번역기)에서의 Attention 신경망을 활용한 기계 번역모델(NMT)이 나오기 전 수십 년 동안, 통계기반 기계 번역(Statistical Machine Translation)이 지배적인 모델이었습니다[9]. NMT는 거대한 단일 신경망을 구축하고 훈련합니다. 이러한 방식은 입력 텍스트를 읽고 번역을 출력하는 기계번역의 새로운 접근법입니다. [1]. 기계 번역모델의 선구 연구들은 Kalchbrenner and Blunsom (2013), Sutskever et. al (2014) 와 Cho. et. al (2014b)입니다. 여기서 더 익숙한 구조는 ..
 ADSP 3과목 정리내용 - 5장: 정형 데이터 마이닝
ADSP 3과목 정리내용 - 5장: 정형 데이터 마이닝
교재 : 데이터 분석 준 전문가 Adsp 2017 데이터 분석 1장. 데이터 분석 개요 2장. R프로그래밍 기초 3장. 데이터 마트 4장. 통계 분석 5장 정형 데이터 마이닝 4장. 통계 분석 - PCA 주성분 분석 : 기존의 상관성이 높은 변수들을 요약, 축소하여 선형결합으로 만드는 방법!!! = 차원을 축소하는 방법. Proportion of Variance : 변수가 설명하는 정도. 주성분1은 95.5%를 설명함. Cumulative Proportion : 위의 Proportion of Variance의 누적값. 위와는 다른 예시지만 Component Number의 수에 따라 변동성을 보여 줌. 위의 테이블은 2개의 변수 long과 diag가 주성분1과 2에 기여하는 가중치를 보여주는 부분. Com..
 Analysis of Variance (분산 분석)
Analysis of Variance (분산 분석)
참고 : 이 내용은 Sheldon_Ross의 Introduction to probability and statistics의 ch10을 번역, 정리한 내용입니다. ONE-WAY-ANALYSIS OF VARIANCE TWO-FACTOR ANALYSIS OF VARIANCE TWO-WAY ANALYSIS OF VARIANCE WITH INTERACTION 예제 1번 A college administrator claims that there is no difference in first-year grade point averages for students entering the college from any of three different city high schools. The following data g..
 Introductory Guide – Factorization Machines & their application on huge datasets (with codes in Python)
Introductory Guide – Factorization Machines & their application on huge datasets (with codes in Python)
참고 : https://www.analyticsvidhya.com/blog/2018/01/factorization-machines/ 링크의 글을 번역한 글입니다. Introduction 나는 아직도 클릭 예측 문제로 처음 만났던 순간을 기억합니다. 이전에는 나는 데이터 과학을 배우고 있었고 나의 진전에 대해 기분이 좋았습니다. ML hackathons에 대한 자신감을 갖기 시작했고 나는 몇 가지의 도전을 하기로 결심했습니다. 더 잘하기 위해서, 나는 16GB RAM과 i7 프로세서를 갖춘 기계를 조달했습니다. 그러나 데이터 세트를 처음 보았을 때 불안감이 있었습니다. 압축을 풀 때의 데이터는 50GB 이상이었습니다. 그런 데이터 세트의 클릭을 예측하는 방법을 알지 못했습니다. 고맙게도 Factorizat..
 Convolutional Neural Network (AlexNet)
Convolutional Neural Network (AlexNet)
Note : 본 자료는 edwith 최성준강사님의 논문으로 짚어보는 딥러닝 맥을 정리한 자료입니다. CNN의 구조 CNN의 구조는 위의 사진과 같습니다. Input이라는 이미지가 들어오면 Convolutions작업을 통해서 feature maps를 만들어 내고 Subsampling을 통해서 그 사이즈를 줄입니다. 마찬가지로 Convolutions - Subsampling 작업을 반복하다가 마지막에 Full Connection이라는 작업을 통해서 Output(Fully Connected layer)을 산출합니다. 위의 과정을 더 자세하게 설명 하겠습니다. 우리는 사진이 들어오면 Output으로 이 사진이 무슨 사물을 가르키는지를 알아보는 Neural Network를 만들것입니다. 먼저 Image로 보트사진..