
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Semantic Segmentation
- 프로그래머스
- pytorch
- Segmentation
- 엘리스
- 큐
- eda
- Machine Learning Advanced
- Python
- 협업필터링
- 스택
- MySQL
- 한빛미디어
- Recsys-KR
- DFS
- DilatedNet
- 알고리즘
- 나는 리뷰어다
- TEAM EDA
- 튜토리얼
- 파이썬
- 추천시스템
- 입문
- 코딩테스트
- hackerrank
- 3줄 논문
- TEAM-EDA
- Image Segmentation
- Object Detection
- 나는리뷰어다
- Today
- Total
TEAM EDA
Dataprep.eda : Accelerate your EDA (EDA 자동화 패키지) 본문
원문 아티클 : https://towardsdatascience.com/dataprep-eda-accelerate-your-eda-eb845a4088bc
해당 글은 Slavvy Coelho의 Dataprep.eda: Accelerate your EDA을 번역한 글입니다.
이미지 출처 : MicroStockHub, via: Getty Images/iStockphoto
Authors: Slavvy Coelho, Ruchita Rozario
Mentor: Dr. Jiannan Wang, Director, SFU’s Professional Master’s Programs (Big Data and Cybersecurity and Visual Computing)
"숫자는 중요한 이야기를 가집니다.
또한 당신에게 명확한 의미를 제공합니다." by Stephen Few
오늘날 대부분 산업은 데이터를 가치 있는 자산으로 인식합니다. 하지만 데이터 그 자체는 중요하지 않습니다. 실제로 중요한 것은 데이터로 무엇을 해야 할 지, 어떻게 활용해야 할 지입니다. 추가 이익을 얻거나 새로운 발견을 통한 혁신은 위의 과정을 통해서 나오기 때문입니다.
처음 작업하는 데이터에 대해서는 추세와 패턴을 파악하기 어렵습니다. 이때, EDA를 통해 데이터를 분석하는 것이 도움됩니다. EDA는 데이터가 어떻게 진행되고 있는지에 대한 전체적인 흐름을 파악하게 해줍니다. 또한, 숨겨진 관계와 패턴을 파악하는 데 도움을 줍니다. 이렇게 파악한 직관이 분석 및 학습 모델을 구축하는 데 중요하게 작용합니다.
일반적인 EDA의 절차는 아래와 같습니다.
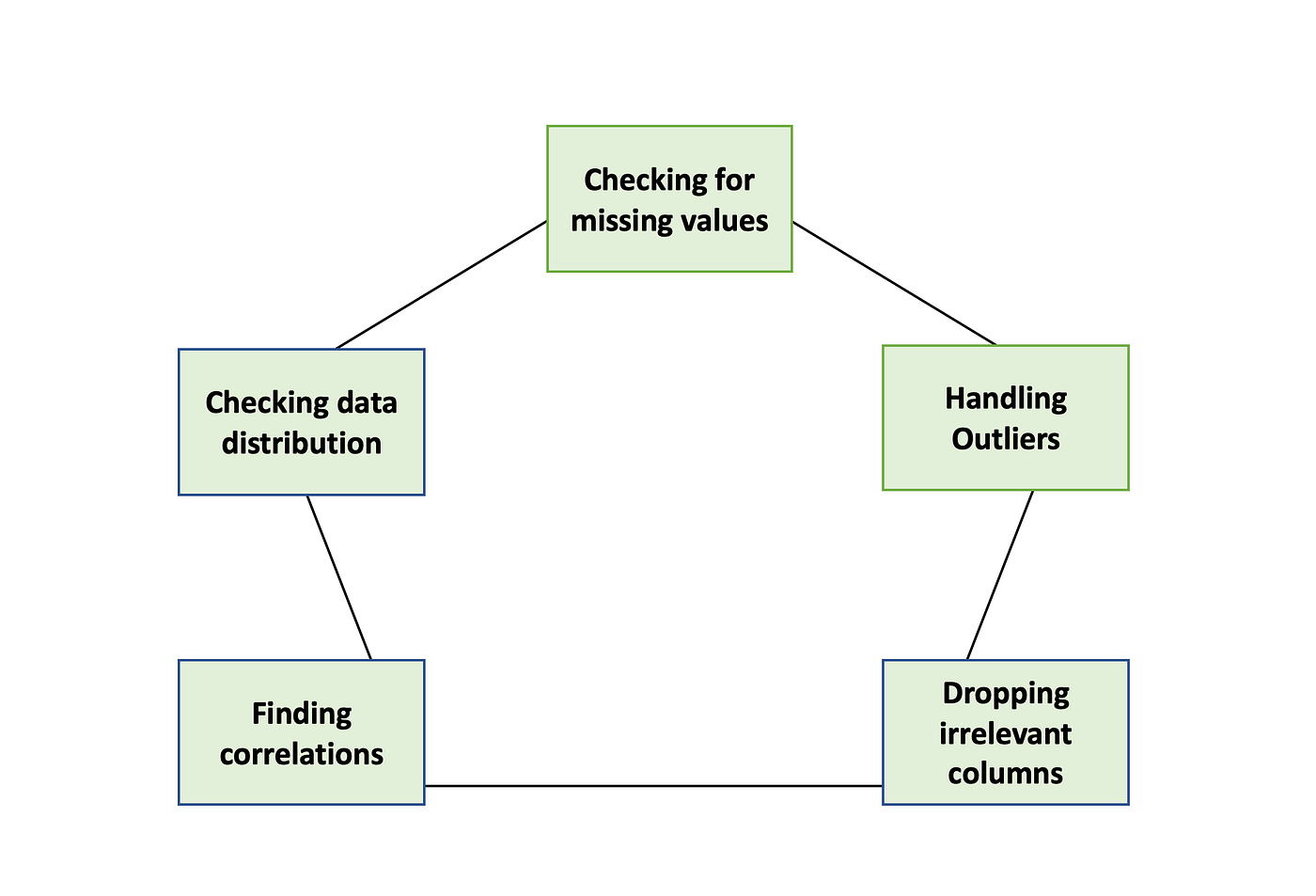
Dataprepare는 SFU Data Science Research Group의 직관적인 도구로 데이터 과학의 속도를 높입니다. Dataprep.eda는 최소한의 코드로 전체 EDA 프로세스를 단순화하는 패키지입니다. 우리는 EDA가 데이터 과학 파이프라인에서 매우 중요하고 시간이 많이 소모되는 것을 알고 있습니다. 그렇기에 이를 효과적으로 도와줄 도구를 갖추는 것이 좋습니다.
이 글은 dataprepare.eda로 할 수 있는 모든 것에 대해 손쉽고 실용적인 경험을 제공합니다. 그럼 이제 dataprepare.eda에 대해 알아보겠습니다.
#installing dataprep.eda
#open your terminal
pip install dataprep이를 배우기 위해. 사기 탐지 데이터 세트 에 dataprep.eda를 적용했습니다. 데이터에는 amount, original balance, origin account, destination account와 같은 변수들과 이 거래가 실제로 사기 거래인지 여부를 나타내는 타겟 라벨(isFraud)이 있습니다.
#importing all the libraries
import pandas as pd
from dataprep.eda import plot, plot_correlation, plot_missing
#importing data and dropping missing values
df = pd.read_csv("capdata.csv")데이터는 다음과 같습니다.

dataprep.eda 패키지에는 4개의 하위 모듈이 있고 각각을 설명할 것입니다 :
1. dataprep.eda.basic package
사용자가 데이터 세트의 기본 특성을 분석할 수 있도록 API 플롯을 제공합니다. 각 변수에 대한 분포 또는 bar chart를 표시하여 사용자에게 데이터 집합에 대한 기본적인 의미를 부여합니다.
#API Plot
plot(df) 
사용자가 하나 또는 두 개의 특정 변수에 관심이 있는 경우 해당 변수 이름을 매개 변수로 전달하여 특정 변수에 대한 자세한 플롯을 제공합니다.
plot(df, "newbalanceDest", bins=20)
x에 범주형 변수가 포함 된 경우 bar chart와 pie chart가 표시됩니다.
plot(df,"type")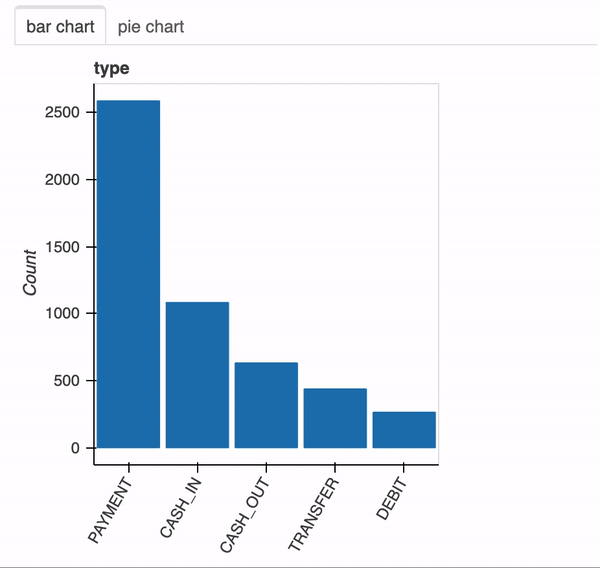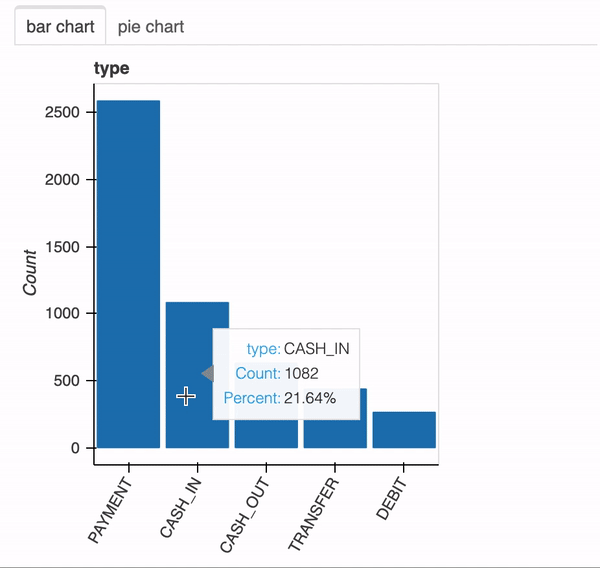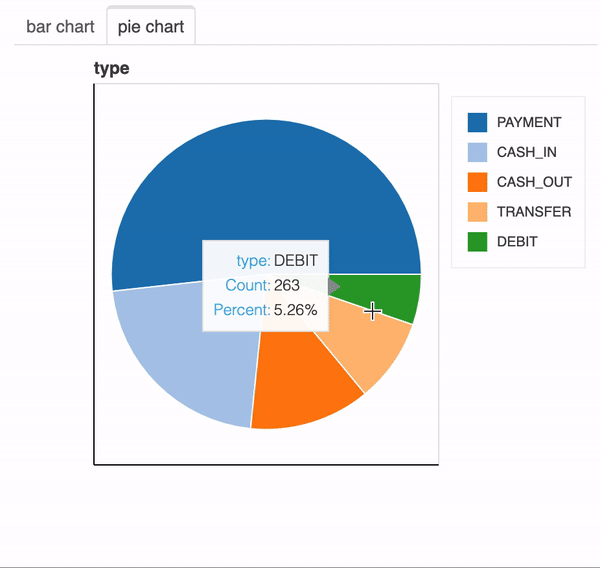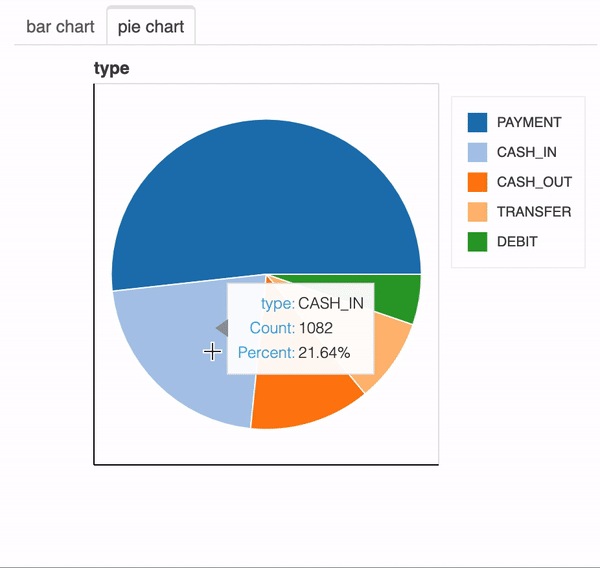
x에 숫자형 변수가 포함 된 경우 histogram, kernel density estimate plot, box plot, 및 qq plot 이 그려집니다.
plot(df, "newbalanceDest", "oldbalanceDest")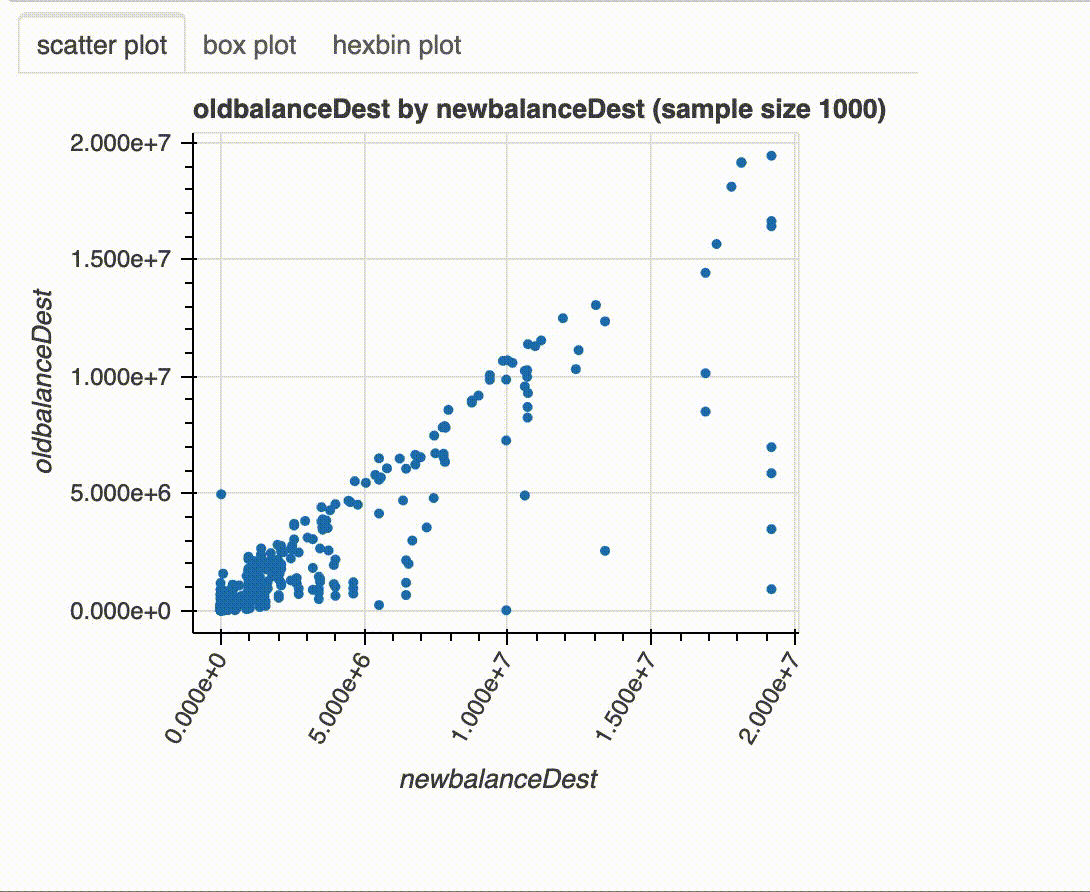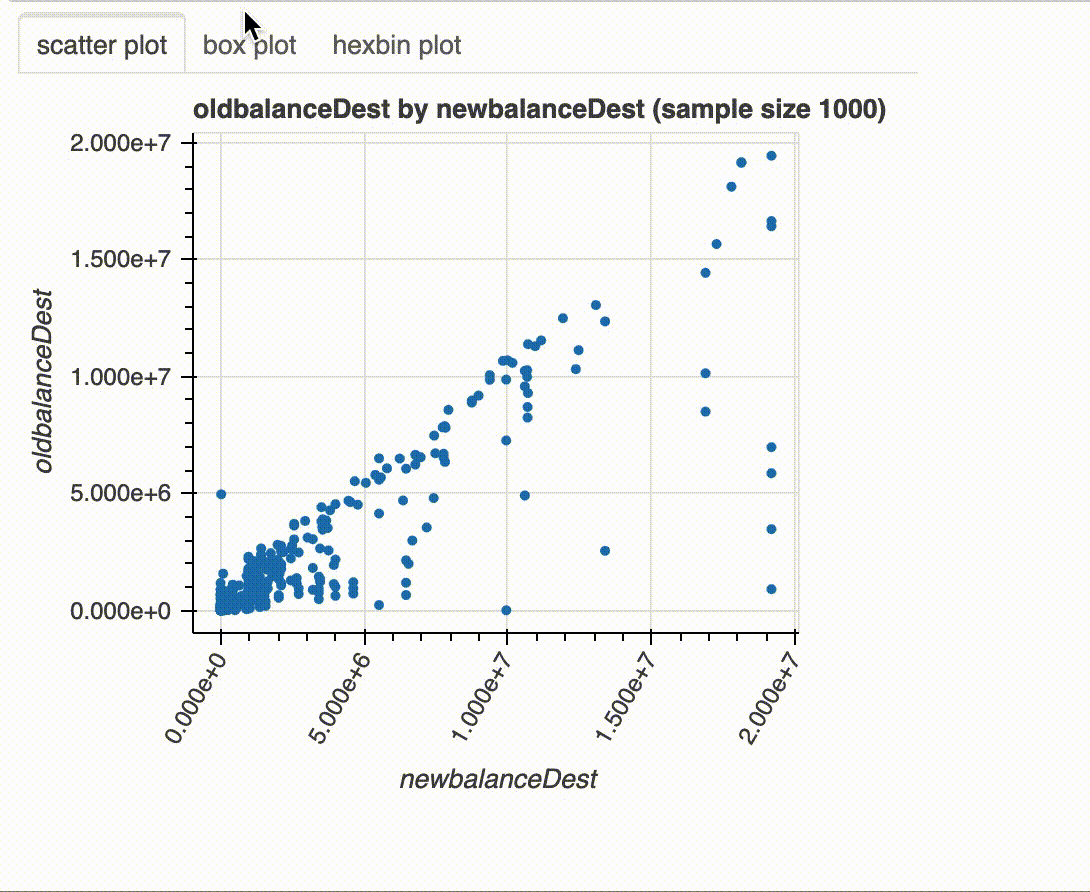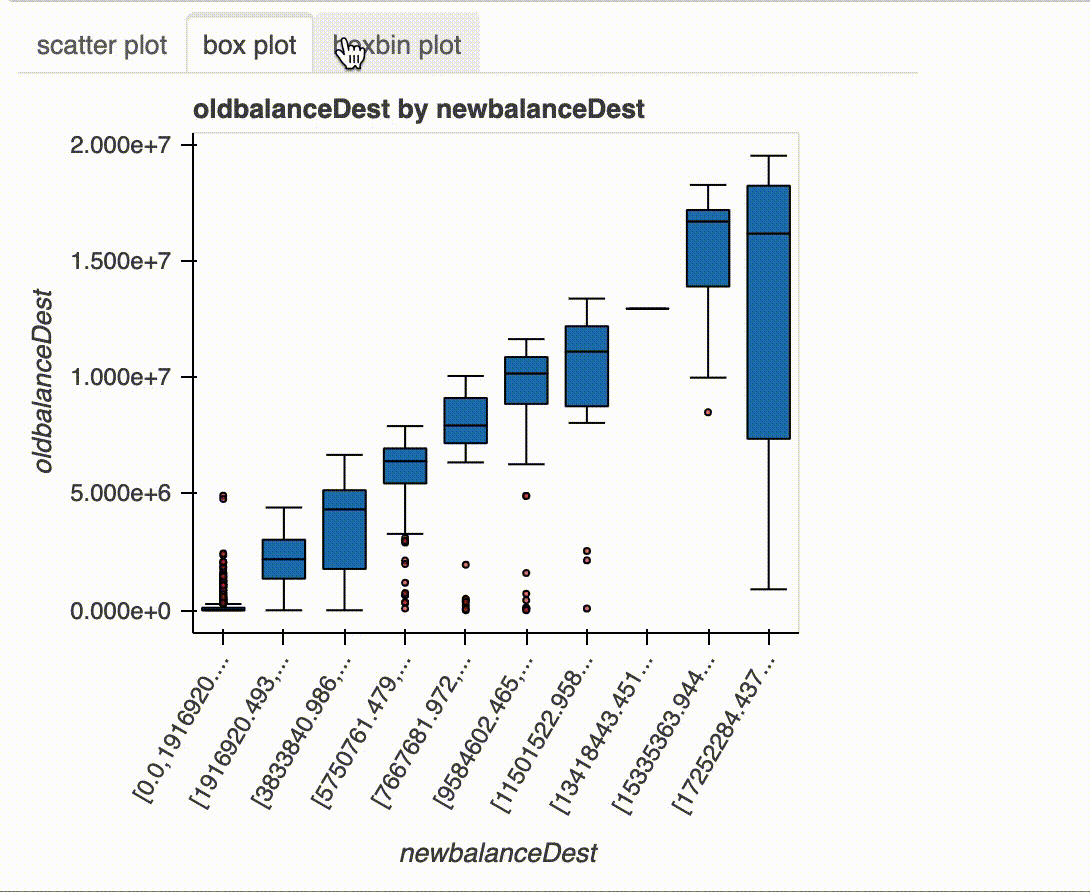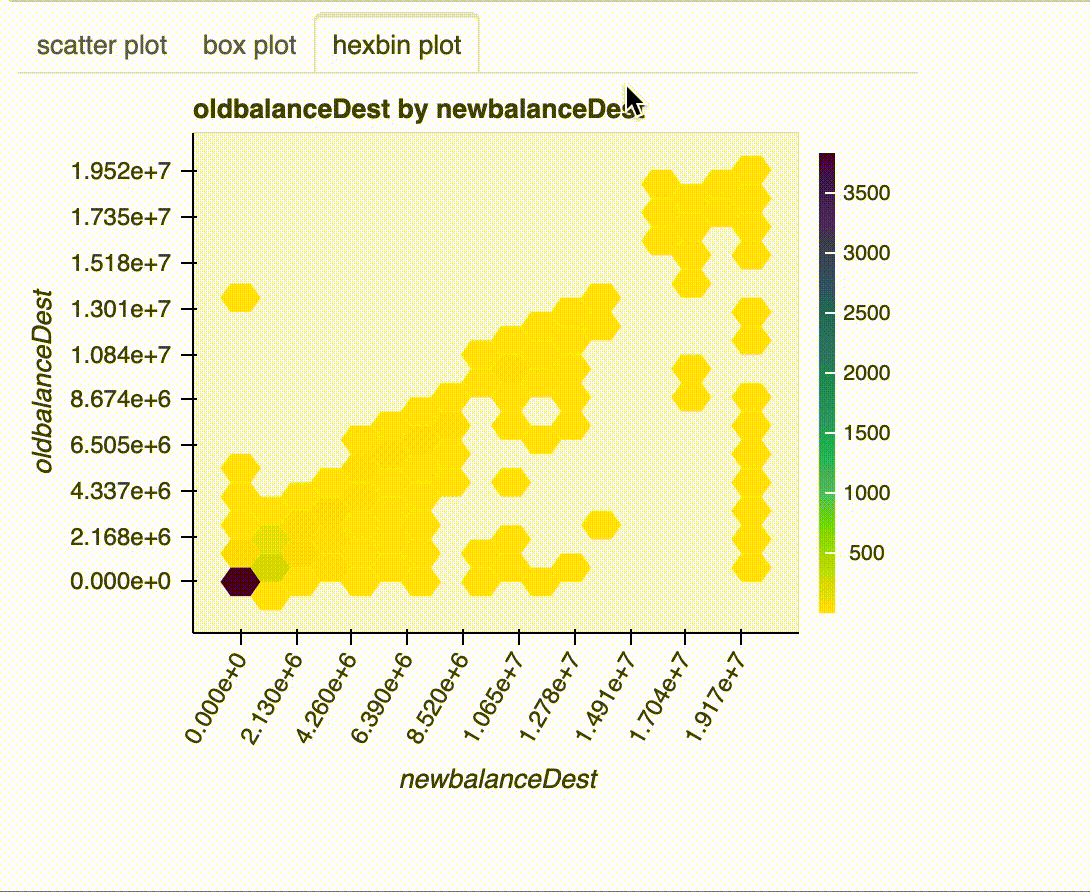
x와 y에 숫자형 변수가 포함되어 있으면 scatter plot, hexbin plot 및 binned box plot이 그려집니다. x와 y 중 하나에 범주형 변수가 포함되고 다른 하나에 숫자형 변수가 포함 된 경우 box plot과 multi-line histogram 이 표시됩니다. x와 y에 범주형 변수가 포함 된 경우 nested bar chart, stacked bar chart 및 heat map이 플롯됩니다.
2. dataprep.eda.correlation package
변수 간의 상관관계를 분석하기 위해 API plot_correlation을 제공합니다. 이는 변수 사이의 상관 행렬을 그립니다. 사용자가 특정 변수와 상관있는 변수들에 관심이 있는 경우 (예 : 가장 상관관계가 높은 변수를 A변수에), API는 A 변수를 매개 변수로 받아서 자세한 분석을 제공합니다.
#API Correlation
plot_correlation(df)
# k값을 가지는 상관 관계 히트 맵 (여기서 k = 1)
plot_correlation(df, k=1)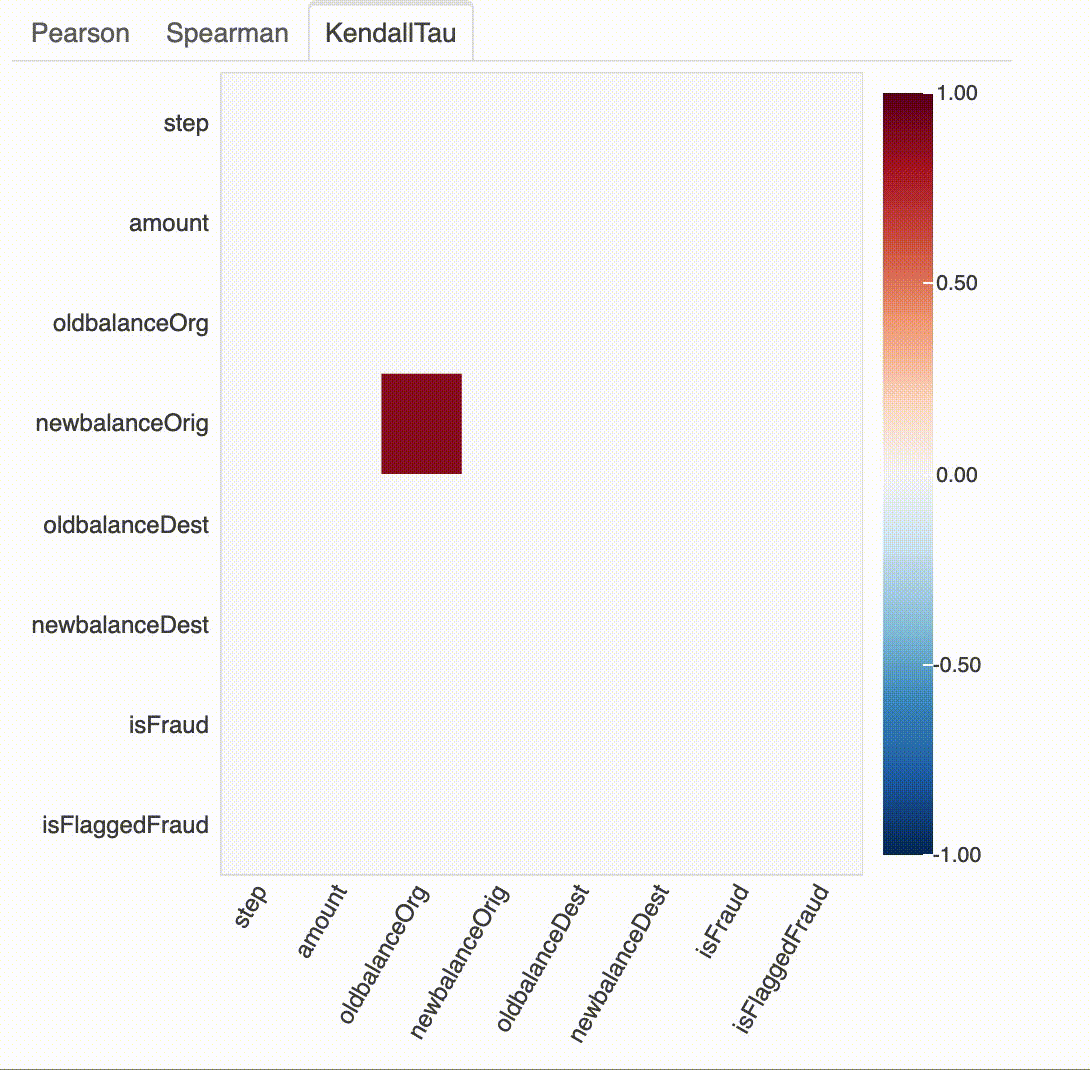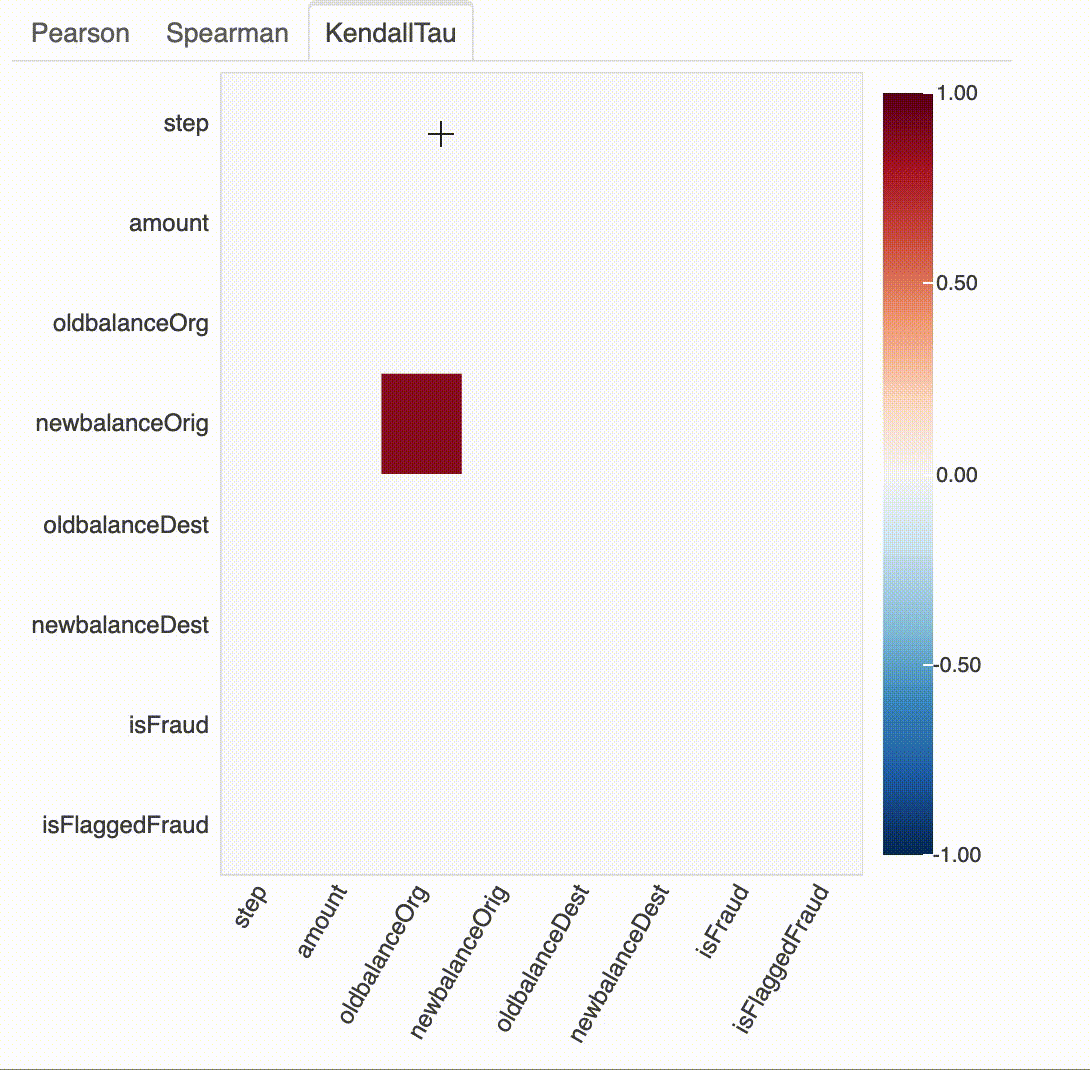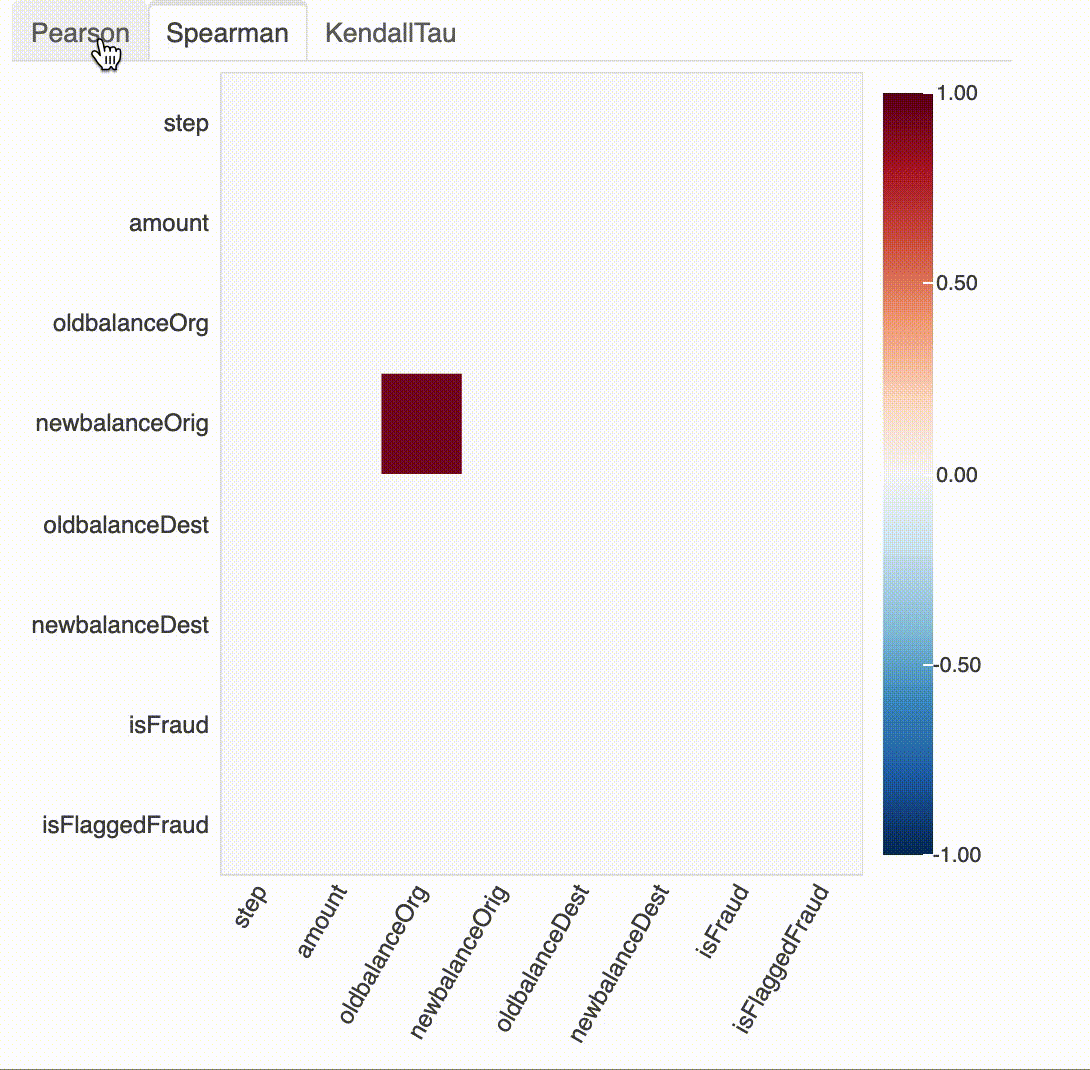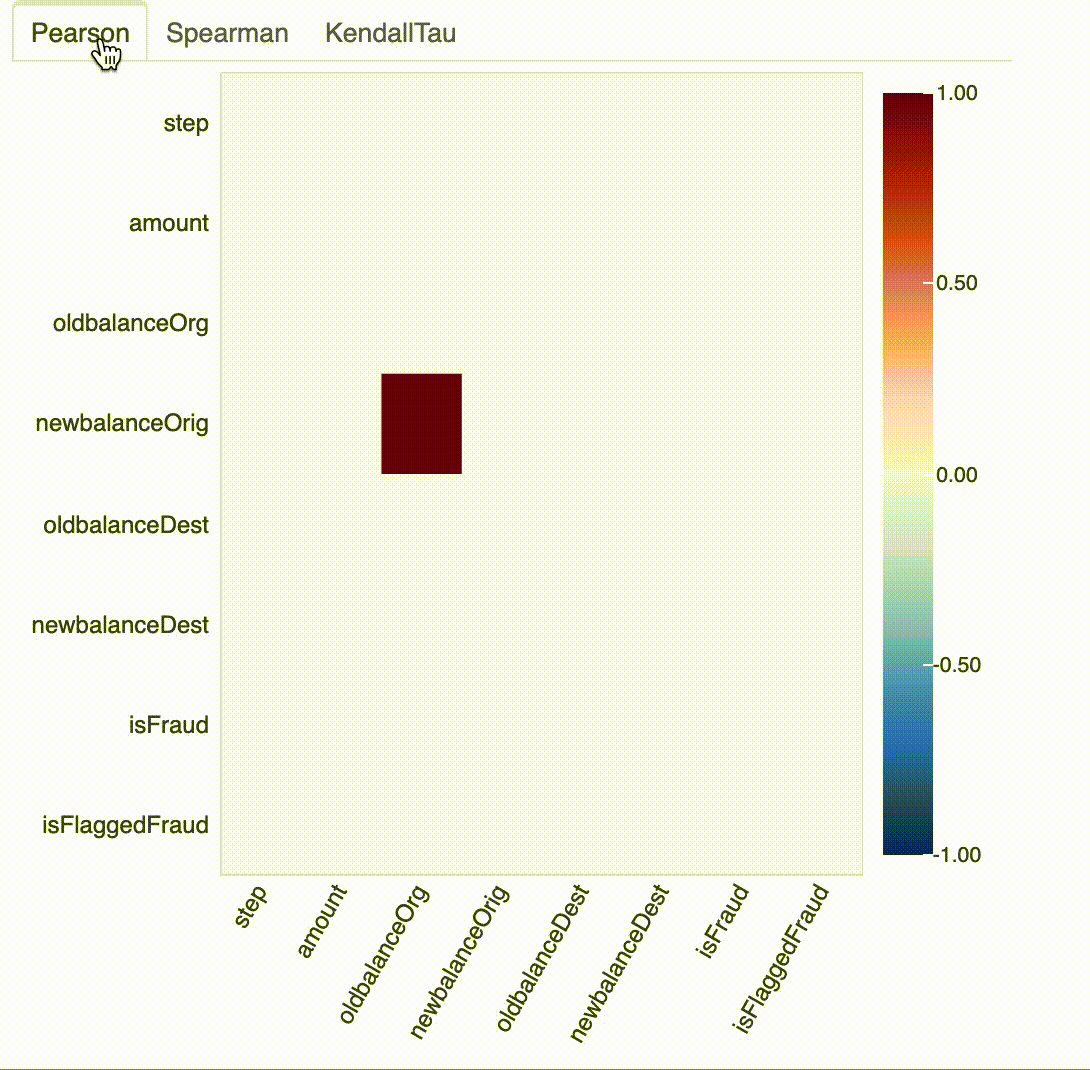
# 지정된 요소와 다른 모든 속성의 상관관계 (즉, newbalanceOrig 과 다른 변수들 간의 상관관계)
plot_correlation(df, "newbalanceOrig") 
# 지정된 변수와 다른 모든 변수의 상관관계 (단, 범위가 -1부터 0.3까지 정해져 있음)
plot_correlation(df, "newbalanceOrig", value_range=[-1, 0.3])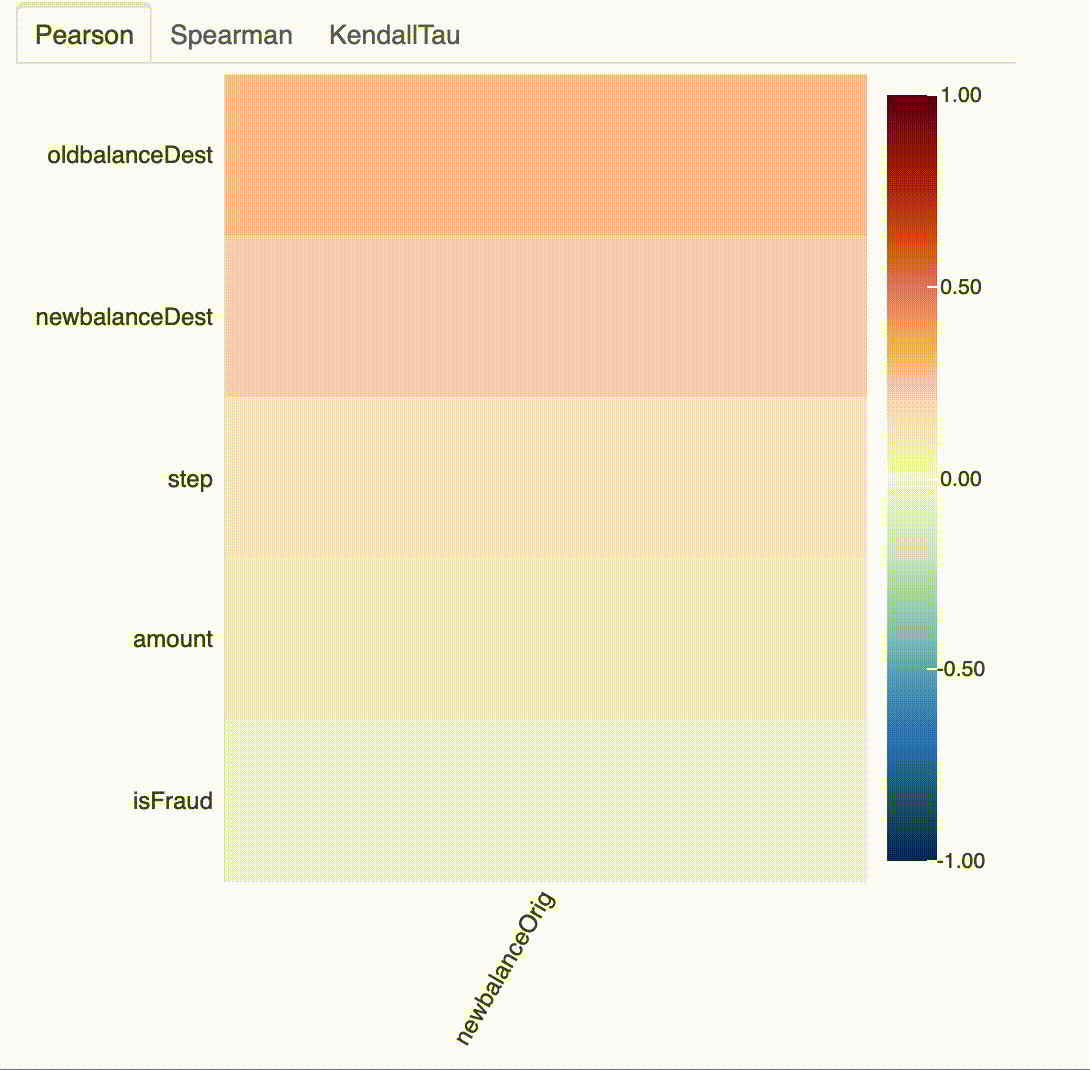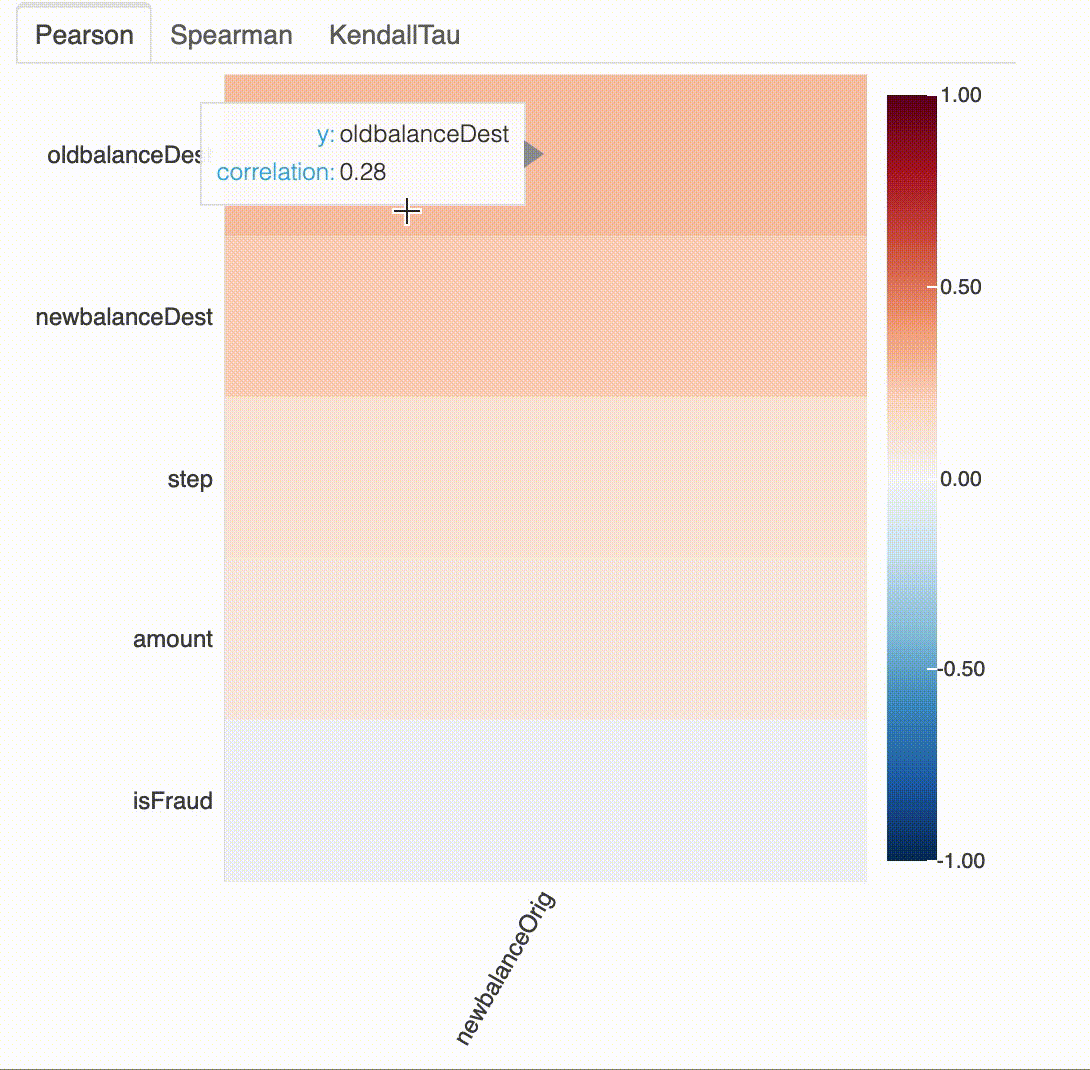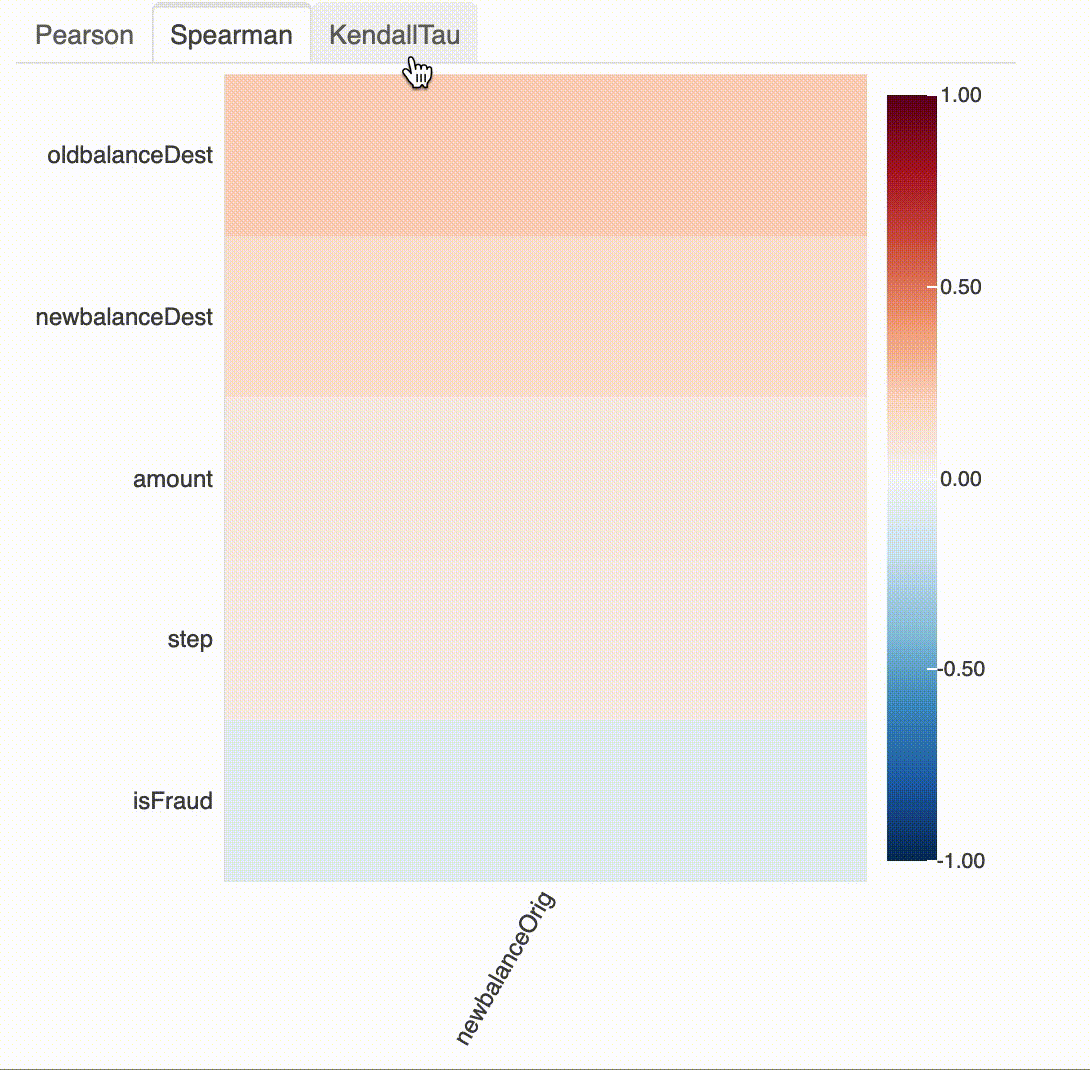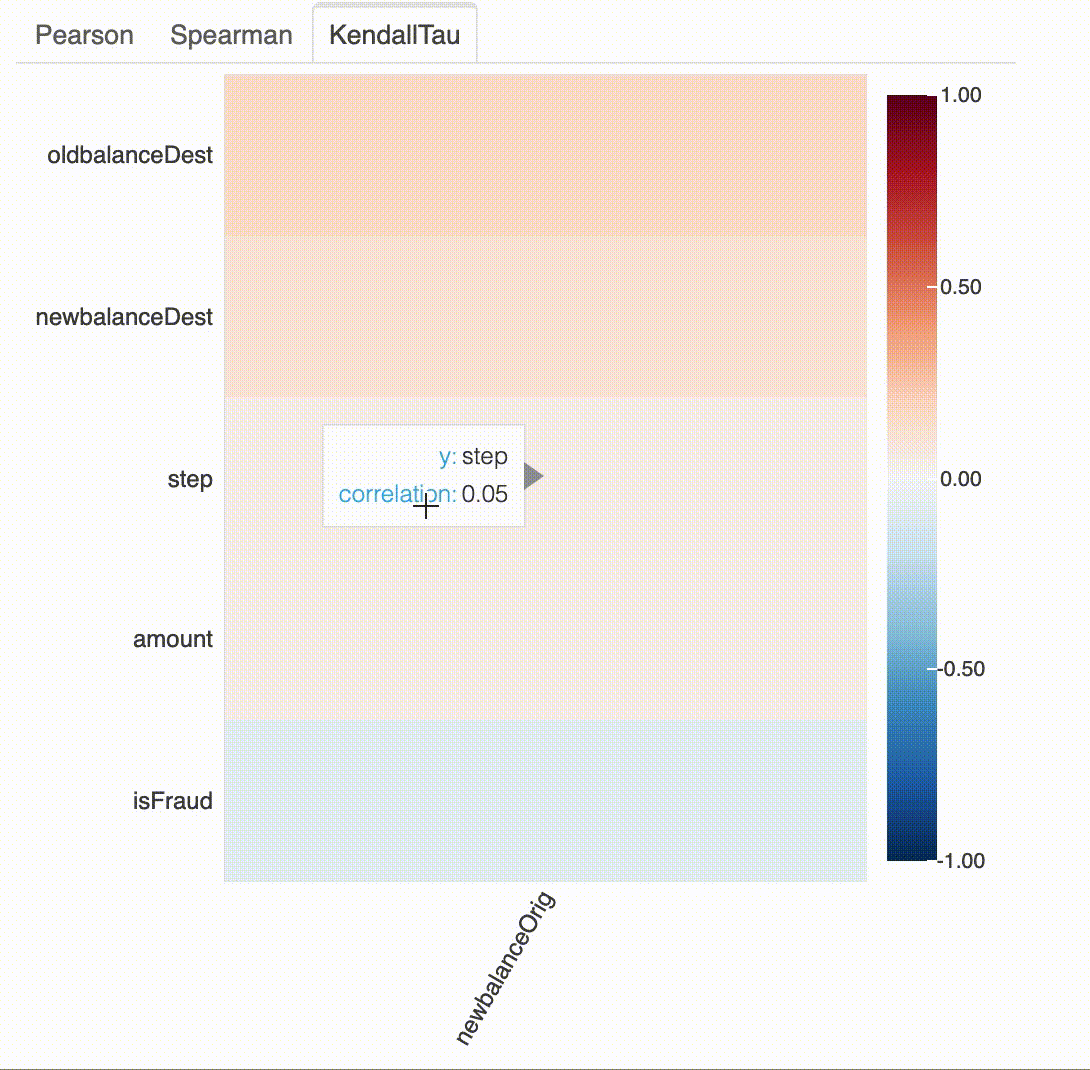
# 가장 적합한 선과 가장 영향력을 끼치는 k개의 점(+, -으로 중요한 k개의 점)
plot_correlation(df, x="newbalanceDest", y="oldbalanceDest", k=5)
3. dataprep.eda.missing package
결측값의 패턴과 영향을 분석하기 위해 API plot_missing을 제공합니다. 한눈에 결측값 위치를 표시하여 사용자가 각 변수의 데이터 품질을 인식하고 패턴을 찾을 수 있습니다.
#API Missing Value
plot_missing(df) 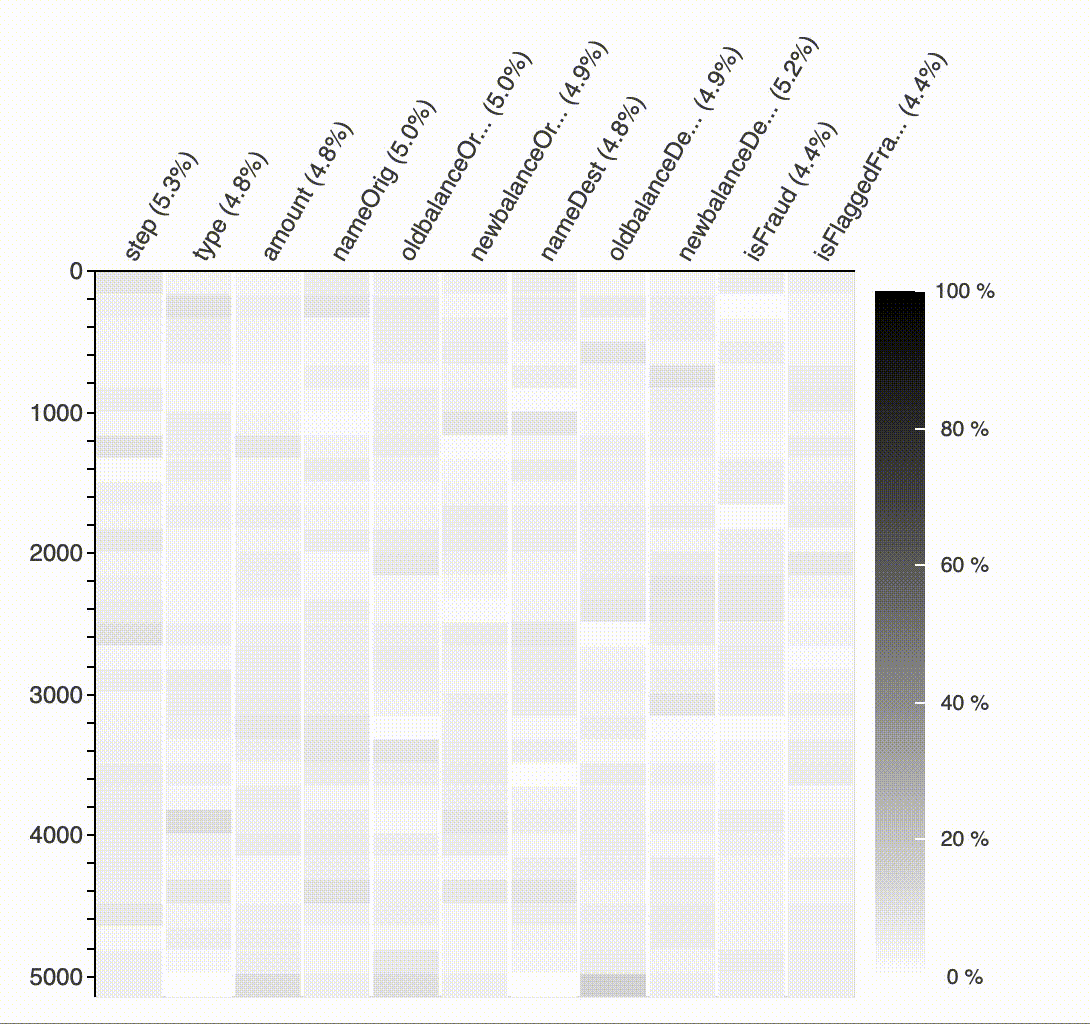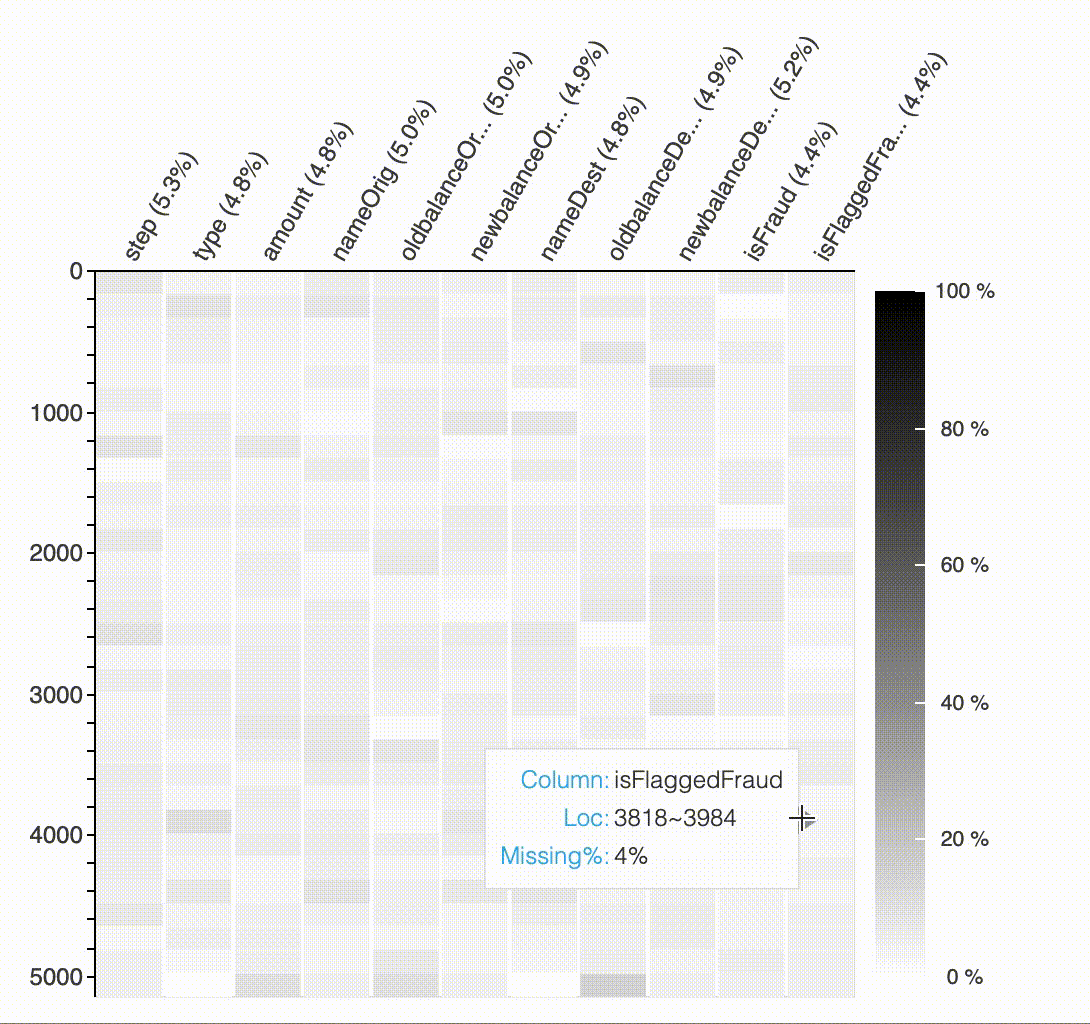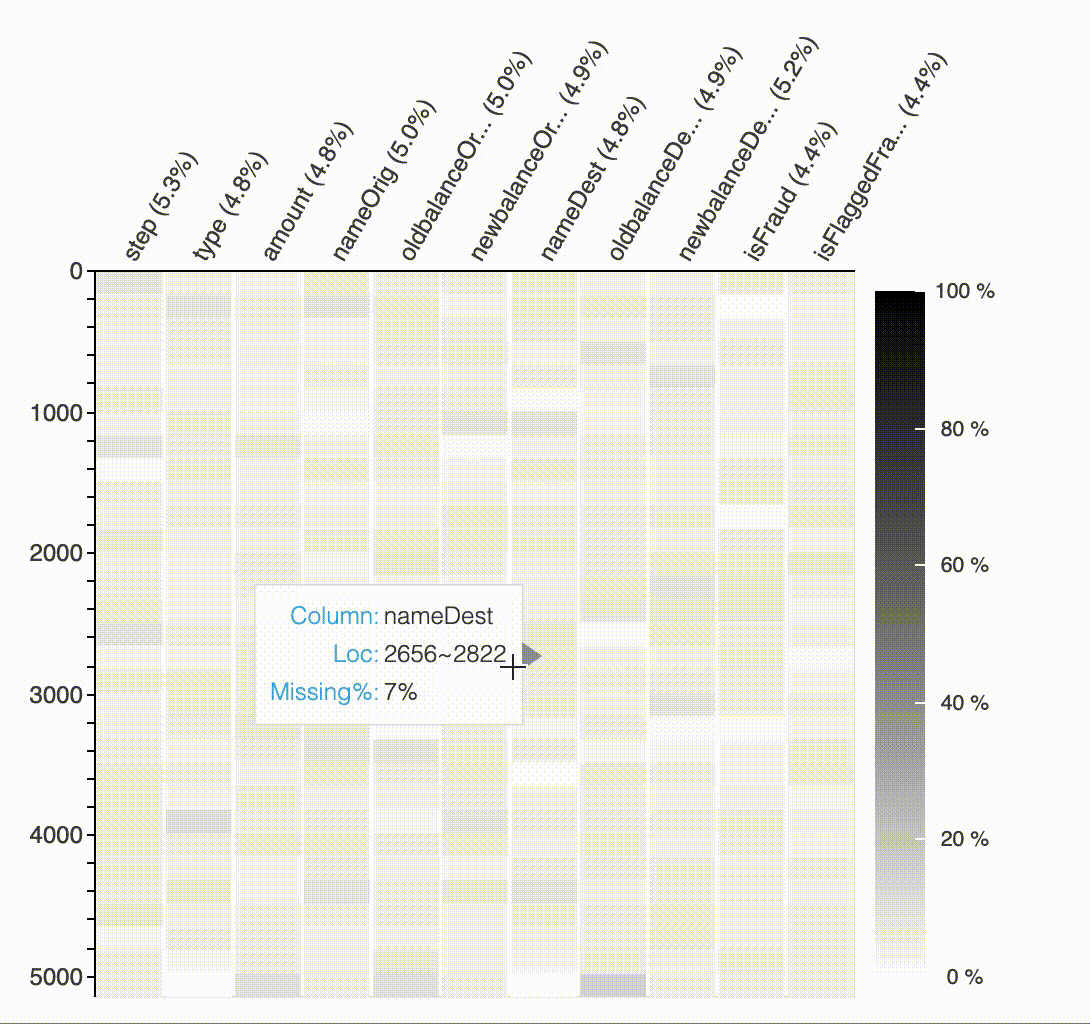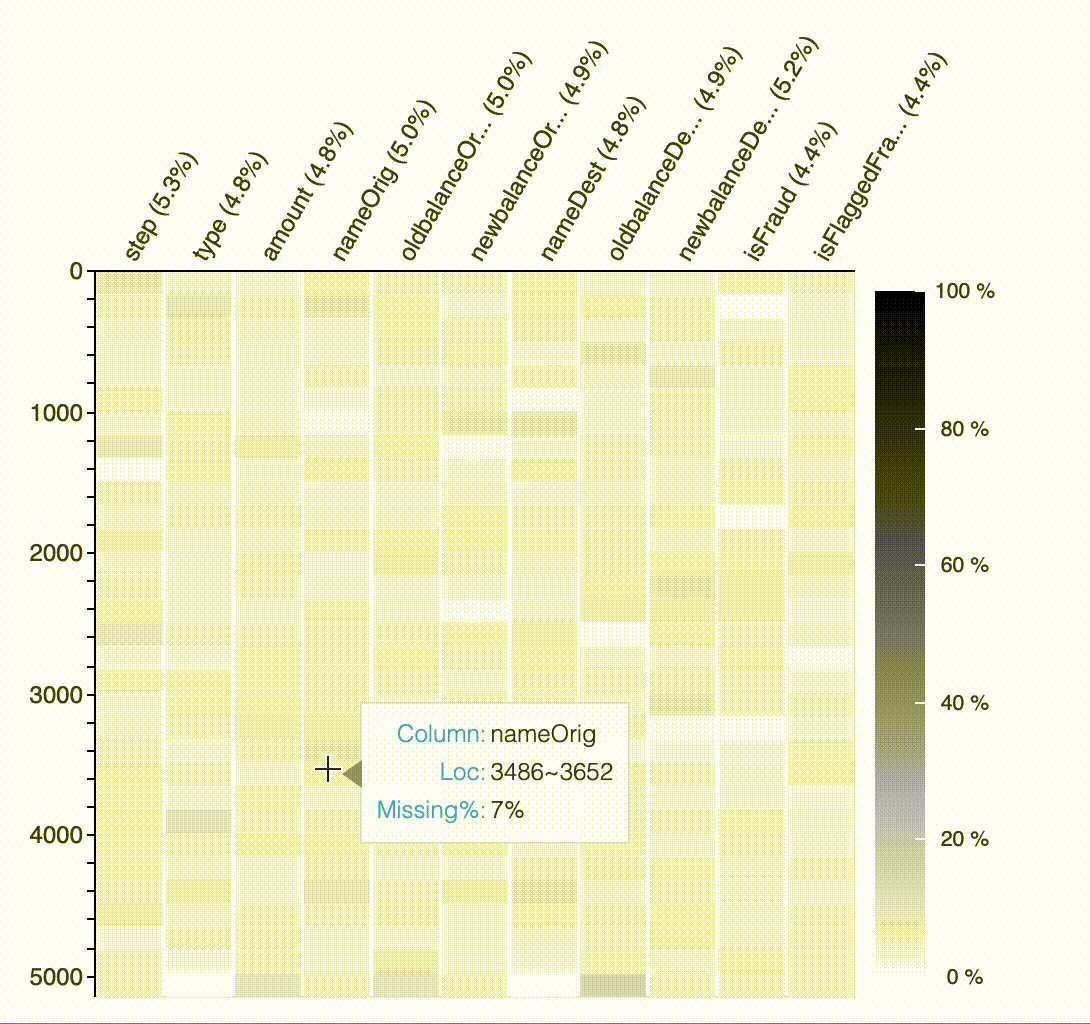
특정 변수에서 결측값이 미치는 영향을 이해하기 위해 이 변수를 매개 변수로 전달할 수 있습니다. 사용자가 결측값의 영향을 이해할 수 있도록 결측값의 유무에 따른 변수의 분포를 제공합니다.
plot_missing(df, "isFraud", "type") #count of rows with and without dropping the missing values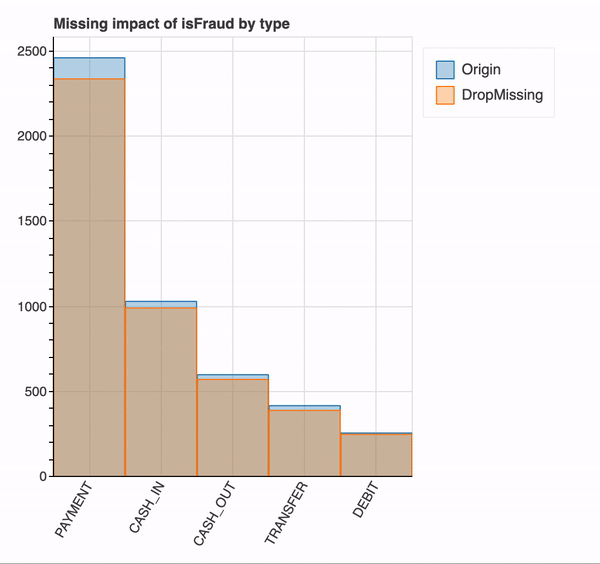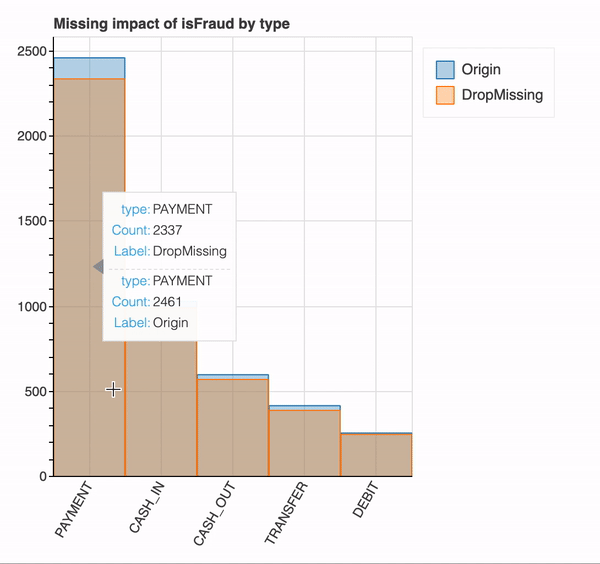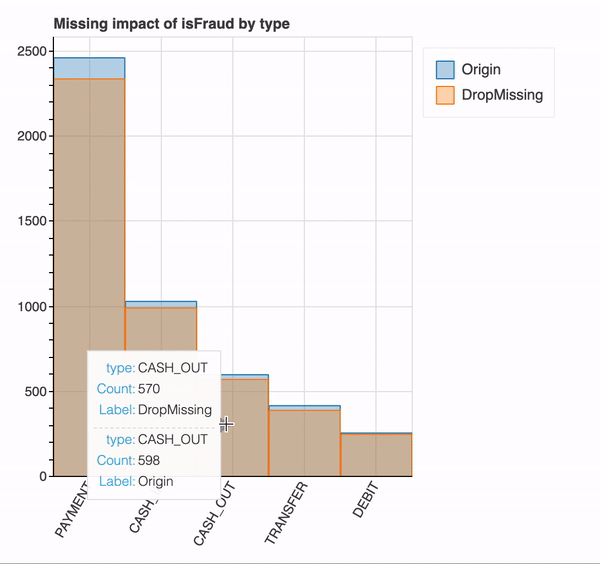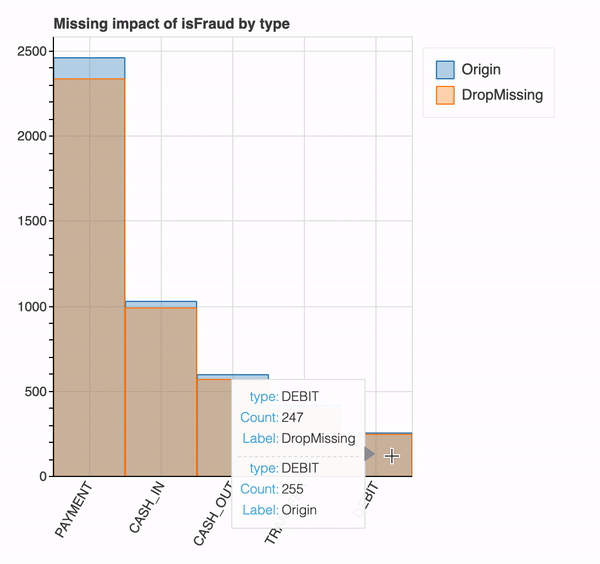
Dataprepare vs Traditional ways
위의 3 가지 API를 함께 사용하면 EDA 프로세스가 쉬워집니다.
이에 대한 효과를 검증하기 위해 dataprep.eda와 기존 python EDA 구현을 비교하는 설문 조사를 수행했습니다. 우리는 10명 (실제 데이터 과학자와 데이터 과학을 공부하는 대학생의 집합)에 대해 설문을 진행했습니다. 설문 조사는 3가지 핵심 성과 지표를 기반으로 합니다.
- Need : 데이터 전문가가 프로젝트당 EDA에 소요하는 시간(단위:분)을 분석했습니다.
여기서 볼 수 있듯이, 대부분의 사람들은 평균적으로 EDA에 약 1시간 30분을 소비합니다. 이 결과는 EDA 프로세스 속도를 높이기 위한 도구가 필요하다는 사실을 입증합니다.
- Readability : 여기에서는 두 가지 접근 방식을 비교하여 가독성의 여부를 확인했습니다.
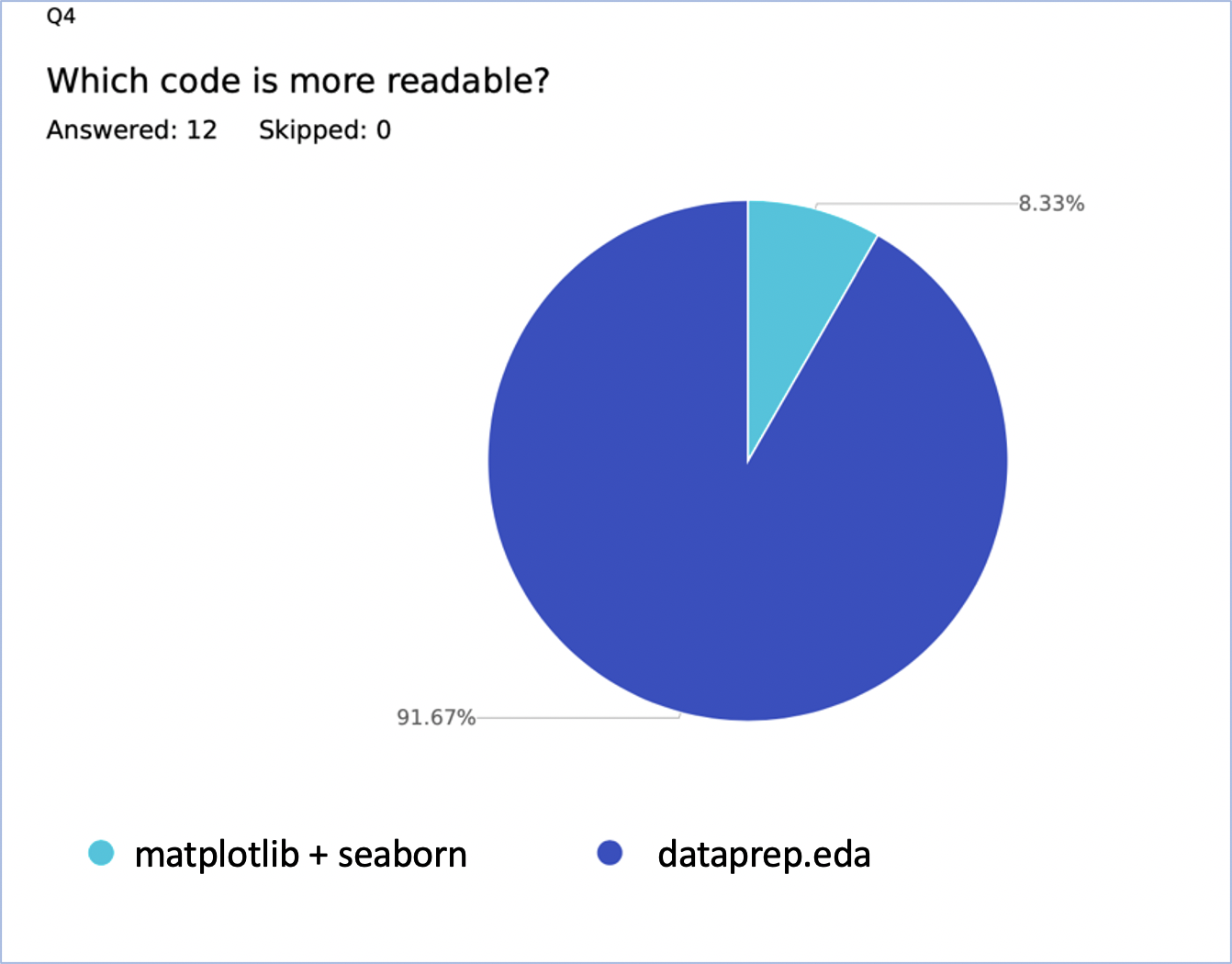
분명히 dataprepare.eda는 보다 명료하고 읽기 쉬운 코드를 제공합니다.
- Lines of code: dataprep.eda는 실제로 코드 길이를 줄입니까?
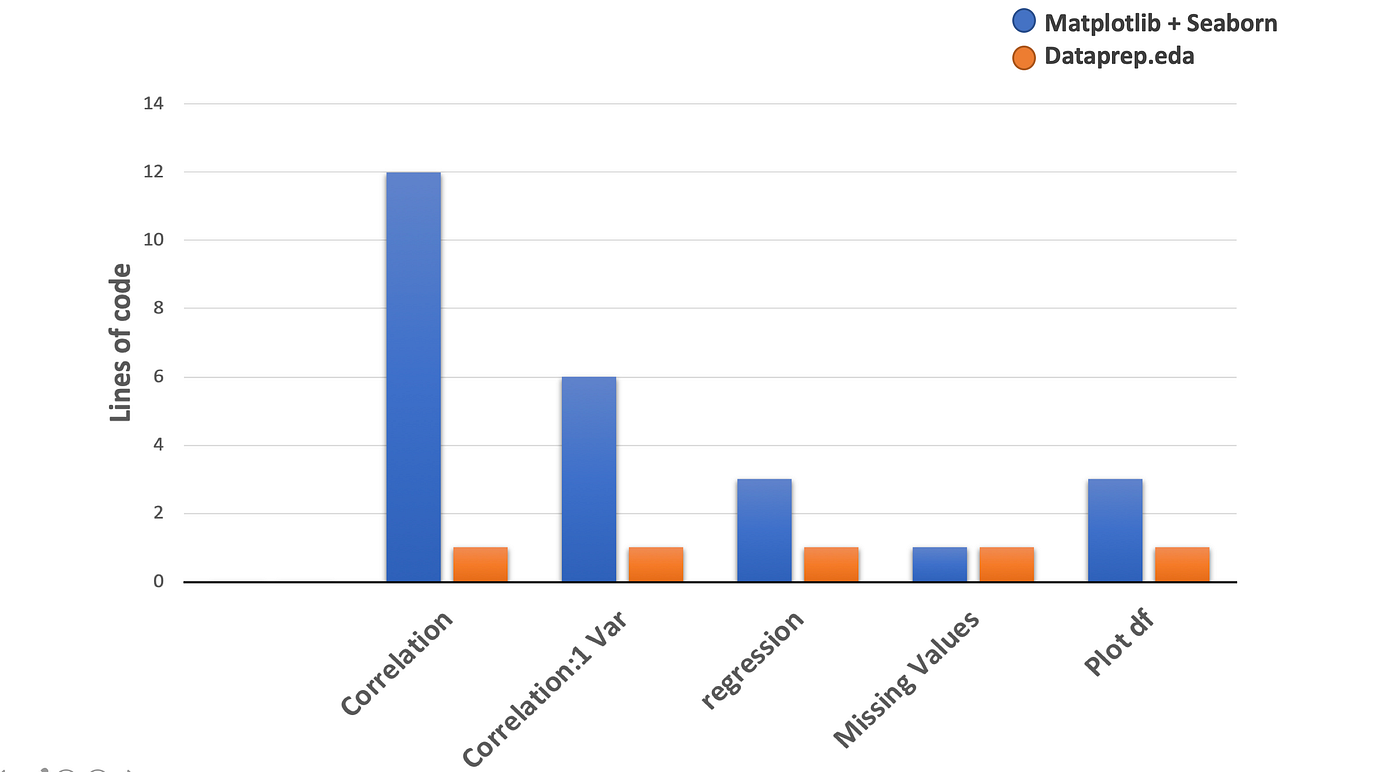
위의 핵심 성능 지표 외에도 dataprep.eda는 기존과 비교하여 여러 측면에서 나은 것으로 입증되었습니다. 이 세 가지 접근 방식이 서로 경쟁 할 때 어떻게 수행되는지 살펴 보겠습니다.
- 다른 두 가지 접근 방식과 Dataprep.eda의 효율성을 비교하면 Dataprep.eda가 더 효과적입니다.

- Dataprepare.eda는 다른 두가지에 비해 메모리를 효과적으로 다룹니다. 이는 오늘날 빅 데이터 시대에 매우 유용합니다.

- dataprep.eda에 의해 생성된 그래프는 모두 동적 그래프입니다. 하지만 matplotlib 및 seaborn은 정적인 그래프만 생성합니다. 이것은 더 깊은 이해를 도와줍니다.
여러 업계 전문가와 대학생에게 이 도구에 대한 의견을 보내달라고 요청했습니다.
그들 중 일부는 다음과 같이 말합니다.
“이 라이브러리는 정말 좋아 보인다. 작업을 쉽게 합니다. 벤처를 위한 최고의 제품입니다.”— Amazon 소프트웨어 개발자 Dhruva Gaidhani
“결측값 찾기가 효율적입니다. 나는 보통 EDA에 많은 시간을 보냅니다. 이 라이브러리는 몇 가지 기능을 확실히 완화 시켰습니다.” — SFU의 동창인 Manan Parasher
Conclusion
데이터 과학은 매초 변하고 있습니다. 그렇기에 dataprep.eda와 같은 도구를 사용하면 작업을 보다 효율적으로 수행할 수 있습니다.
Dataprepare.eda는 일반적으로 데이터 분포, 상관 관계, 결측값 및 EDA 프로세스 확인과 같은 작업에 탁월합니다. 코딩 및 가독성이 뛰어나 초보자도 쉽게 사용할 수 있습니다. 대체로 Dataprepare.eda는 모든 예비 분석 작업을 수행하는 원-스톱 라이브러리 역할을합니다.
'EDA Study > 머신러닝' 카테고리의 다른 글
| 범주형 변수의 인코딩 방법 (0) | 2021.03.15 |
|---|---|
| 임베딩 기법(Embedding) (0) | 2020.03.28 |
| 교호작용 (0) | 2020.03.22 |
| Feature selection using target permutation (Null Importance) (0) | 2019.09.11 |
| Attn: Illustrated Attention (0) | 2019.09.11 |


