
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 한빛미디어
- 나는리뷰어다
- 3줄 논문
- 협업필터링
- DFS
- 나는 리뷰어다
- Recsys-KR
- 파이썬
- pytorch
- 입문
- MySQL
- Segmentation
- 코딩테스트
- Image Segmentation
- TEAM EDA
- 튜토리얼
- 스택
- Python
- 큐
- 엘리스
- hackerrank
- TEAM-EDA
- DilatedNet
- Object Detection
- 알고리즘
- Semantic Segmentation
- Machine Learning Advanced
- eda
- 추천시스템
- 프로그래머스
- Today
- Total
목록EDA Study/3줄 논문요약 (4)
TEAM EDA
 Object Region Mining with Adversarial Erasing: A Simple Classification toSemantic Segmentation Approach (AE-PSL)
Object Region Mining with Adversarial Erasing: A Simple Classification toSemantic Segmentation Approach (AE-PSL)
Resources Title : Object Region Mining with Adversarial Erasing: A Simple Classification toSemantic Segmentation Approach (AE-PSL) Paper : https://arxiv.org/pdf/1703.08448.pdf Motivation & Introduction 기존 Weakly-Semantic segmentation 에서 pesudo mask를 생성하기위해서 CAM을 많이 사용합니다. 하지만, 이러한 CAM은 Classification Network에 의한 결과로 Object의 일부분만을 바라보는 현상이 있고 이를 바로 pesudo mask로 적용하기에는 무리가 있습니다. 이를 해결하기위해 CAM이 바라보..
 Context Encoding for Semantic Segmentation (EncNet)
Context Encoding for Semantic Segmentation (EncNet)
Resources Title : Dual Attention Network for Scene Segmentation (DANet) Paper : https://arxiv.org/abs/1803.08904 Code :https://github.com/zhanghang1989/PyTorch-Encoding Motivation & Introduction Semantic Segmentation 에서 많은 카테고리가 존재하는 경우에는 정확하게 분류를 하기가 어렵다. 사람도 카테고리가 많으면 분류하기 어려운데, 이를 좀 더 간단하게 하기위해서 상위 카테고리를 기반으로 분류를 진행하면 더 쉽지 않을까하는 동기에서 만들어진 모델이다. 이를 Context Encoding Module 이라고 해서 class-dependen..
 Dual Attention Network for Scene Segmentation (DANet)
Dual Attention Network for Scene Segmentation (DANet)
Resources Title : Dual Attention Network for Scene Segmentation (DANet) Paper : https://arxiv.org/abs/1809.02983 Motivation & Introduction 기존의 연구는 Global한 Context 정보를 잡기위해서 Kernel Size를 넓히거나 Global Average Pooling, Dilated Convolution 등을 이용했다. 하지만, 이는 object와 stuff 사이의 관계를 제대로 파악하지 못한다. 이를 위해, DANet은 2가지의 Self-Attention인 Position Attention과 Channel Attention을 통해서 위의 문제를 해결하려고 한다. Methodology Pos..
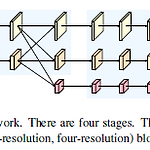 High-Resolution Representations for Labeling Pixels and Regions (HRNetV2)
High-Resolution Representations for Labeling Pixels and Regions (HRNetV2)
Resource Title : High-Resolution Representations for Labeling Pixels and Regions (HRNetV2) Paper : https://arxiv.org/pdf/1904.04514.pdf Motivation & Introduction Vision Task에서 High-Resolution representation learning은 중요한 역할을 한다. 하지만, 기존의 연구들의 대부분은 low-resolution 혹은 medium-resolution으로부터 High-Resolution을 복원하거나 dilated convolution을 통해서 medium-resolution을 계산하는게 전부이다. 비록 이렇게 resolution을 줄여야 receptiv..