
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- TEAM EDA
- 3줄 논문
- 한빛미디어
- MySQL
- DFS
- 스택
- 튜토리얼
- Recsys-KR
- eda
- Object Detection
- Machine Learning Advanced
- 나는리뷰어다
- 알고리즘
- Image Segmentation
- 나는 리뷰어다
- 큐
- Semantic Segmentation
- TEAM-EDA
- pytorch
- hackerrank
- 프로그래머스
- 엘리스
- Segmentation
- 추천시스템
- 파이썬
- 협업필터링
- 코딩테스트
- 입문
- DilatedNet
- Python
Archives
- Today
- Total
TEAM EDA
임베딩 기법(Embedding) 본문
본 글은 자연어 처리에서 주로 사용하는 임베딩 기법들에 대해 정리해놓은 자료입니다. One-hot Encoding, TF-IDF, LSA, Word2Vec, Glove, FastText에 대해 정리할 것이고 ratsgo님의 블로그을 많이 참고하였습니다.
목차
- One Hot Encoding
- TF-IDF
- LSA
- Word2Vec
- Glove
- FastText
One Hot Encoding

- 개념 : 각 단어에 Index를 부여하는 방식으로 표현하는 단어의 Index에 1을 넣고 그렇지 않은 곳 에는 0을 넣는 방법
- 장점 : 사용하기 매우 쉬움. pandas의 get_dummies함수나 sklearn의 preprocessing.OneHotEncoder을 사용하면 됨
- 단점 : 단어의 의미를 전혀 이해하지 못함. 단어의 개수가 많아지면 차원의 길이가 매우 커지는 문제가 생기고 Sparse 하게 벡터가 구성됨.
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())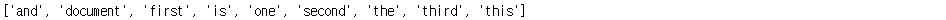
| and | document | first | is | one | second | the | third | this |
| 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
TF - IDF ( Term Frequency-Inverse Document Frequency )
- 개념 : 단어의 빈도와 역 문서의 빈도를 사용하여 단어에 가중치를 부여하는 방식
- tf(d,t) : 특정 문서 d에서의 특정 단어 t가 등장한 횟수
- df(t) : 특정 단어 t가 등장한 문서의 수
- idf(d, t) : df(t)에 반비례하는 수
- $idf(d, t) = \log(\frac{n}{1+df(t)})$
- 장점 : 어떤 단어가 중요한 단어인지 직관적인 해석이 가능.
- 단점 : 문맥에 대한 고려를 해주지 않음 (단어의 의미가 포함되지 않음)
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(vectorizer.vocabulary_)
vectorizer.transform(corpus).toarray()| and | document | first | is | one | second | the | third | this |
| 0 | 0.46979139 | 0.58028582 | 0.38408524 | 0 | 0 | 0.38408524 | 0 | 0.38408524 |
| 0 | 0.6876236 | 0 | 0.28108867 | 0 | 0.53864762 | 0.28108867 | 0 | 0.28108867 |
| 0.51184851 | 0 | 0 | 0.26710379 | 0.51184851 | 0 | 0.26710379 | 0.51184851 | 0.26710379 |
| 0 | 0.46979139 | 0.58028582 | 0.38408524 | 0 | 0 | 0.38408524 | 0 | 0.38408524 |
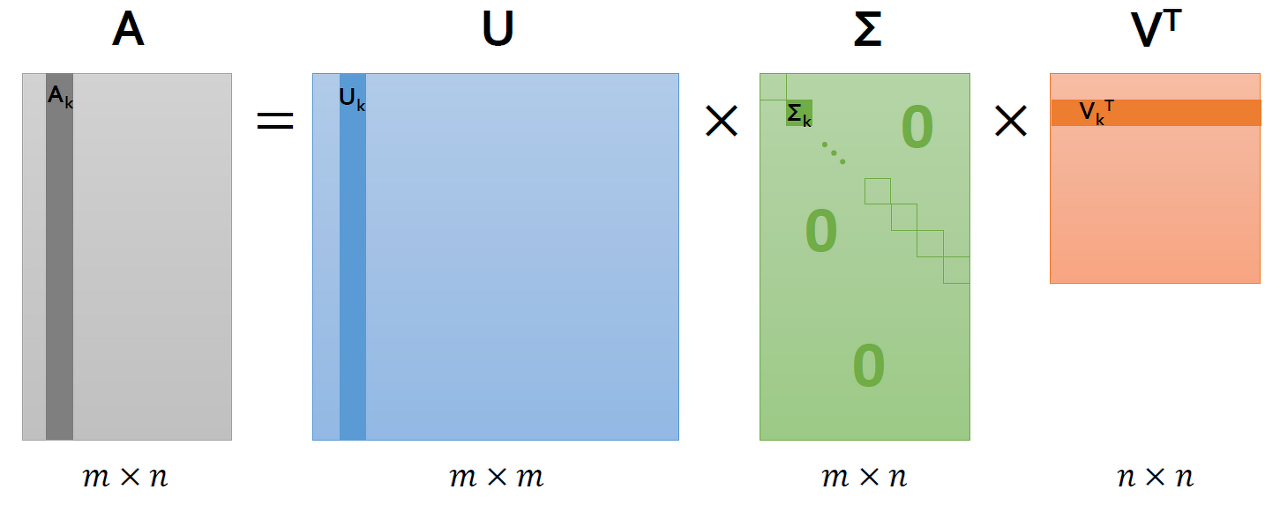
잠재 의미 분석 (Latent Semantic Analysis, LSA)
- 개념 : 기존의 원핫인코딩이나 TF-IDF의 경우 단어의 의미를 고려하지 못하는 단점을 해결한 방법
- TF-IDF 행렬에 Truncated SVD를 적용
- SVD의 Singular Value($\sum{}$)는 $AA^T$의 고유값에 제곱근을 취한 결과
- Truncated는 SVD는 $sum{}$ 행렬의 대각 원소 가운데 상위 t개만 골라낸 형태
- 장점 : 단어의 잠재적인 의미를 고려
- 단점 : 새로운 정보에 대한 업데이트가 어렵고 단어-문서 간의 유사도를 계산하기 어려움 (차원이 축소되어서 단어 간의 의미 파악이 힘듦. 후에 Glove에서 이를 지적하고 해결)
$$A = U\sum{}V^{T}$$
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
svd = TruncatedSVD(n_components=3, n_iter=7, random_state=42)
svd.fit_transform(X)| Doc1 | 0.95905678 | -0.13453834 | -0.24921784 |
| Doc2 | 0.79765181 | -0.18548718 | 0.57388684 |
| Doc3 | 0.45705072 | 0.88833467 | 0.04434133 |
| Doc4 | 0.95905678 | -0.1345384 | -0.24921784 |
Word2Vec
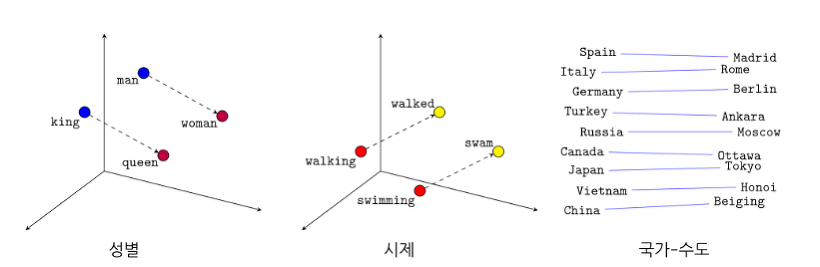
- 개념 : 기존의 원핫인코딩이나 TF-IDF의 경우 단어의 의미를 고려하지 못하는 단점을 해결한 방법으로 중심 단어와 주변 단어 간의 관계를 통해서 임베딩 하는 방법
- 방법
- CBOW : 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
- Skip-Gram : 중심의 단어로 주변에 있는 단어들을 예측하는 방법
- 장점 : 단어들의 유사도를 계산하기에 임베딩 된 벡터 자체가 단어의 의미를 포함함. (Dense Representation이기에 적은 차원으로 대상을 표현할 수 있고 일반화 능력을 갖추고 있음). 온라인 방식으로 모델에 데이터가 공급될 수 있으며 전처리가 거의 필요하지 않으므로 메모리가 거의 필요하지 않음
- 단점 : 사용자가 지정한 윈도우(주변 단어 몇 개만 볼지) 내에서만 학습/분석이 이뤄지기 때문에 말뭉치 전체의 공기 정보(co-occurrence)는 반영되기 어려움(Glove에서 지적한 단점). 데이터가 충분히 많아야 학습이 잘 됨(아래와 같이 데이터가 적은 경우 학습이 잘 안 됨). 카테고리 수가 너무 많으면(어휘가 많으면) softmax함수를 사용하면 모델을 학습하기가 매우 어려움, 이를 해결하기 위해 negative sampling 같은 방법이 도입
from gensim.models import Word2Vec
import re
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 불필요한 특수문자를 삭제
# document. document? -> document
corpus_ = []
for i in corpus:
corpus_.append(re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]', '', i))
# 문장을 단어단위로 변환
words = [sentence.split(' ') for sentence in corpus_]
words
model = Word2Vec(size=4, window=1, min_count=1, workers=4)
model.build_vocab(words)
model.train(words, total_examples=model.corpus_count, epochs=100, report_delay=1)word_vectors = model.wv
vocabs = word_vectors.vocab.keys()vocabs
word_vectors[vocabs]
word_vectors.most_similar('This')
Glove
- 개념 : LSA, Word2Vec의 문제점을 개선한 모델로 “임베딩 된 단어 벡터 간 유사도 측정을 수월하게 하면서도 말뭉치 전체의 통계 정보를 좀 더 잘 반영”
- LSA : LSA는 말뭉치 전체의 통계적인 정보를 모두 활용하지만, LSA 결과물을 가지고 단어/문서 간 유사도를 측정하기는 어려운 단점
- Word2Vec : 저 차원 벡터 공간에 임베딩 된 단어 벡터 사이의 유사도를 측정하는 데는 LSA에 비해 좋은 성능을 가지지만, 사용자가 지정한 윈도우(주변 단어 몇 개만 볼지) 내에서만 학습/분석이 이뤄지기 때문에 말뭉치 전체의 공기 정보(co-occurrence)는 반영되기 어려운 단점
- 출처 : ratsgo님 블로그 - GloVe를 이해해보자!
- 방식 : Co-occurrence 가 있는 두 단어의 단어 벡터를 이용하여 co-occurrence 값을 예측하는 regression 문제를 품
- Loss : $\sum f(x_{ij}) \times \left( w_i^t w_j + b_i + b_j - log(x_{ij}) \right)^2$
- 단어 $w_i$와 $w_j$의 벡터 곱에 각 단어의 bias인 $b_i. b_j$를 더한 값이 Co-occurrence의 log값과 비슷해지도록 $w_i, w_j, b_i, b_j$를 학습하는 방식
- 출처 : Lovit님 블로그 - GloVe, word representation
- 장점 : 벡터 공간에서 하위 선형 관계를 포착하도록 단어 벡터를 적용 보통 Word2Vec보다 성능이 좋음. 단어와 단어보다는 단어 쌍과 단어 쌍 사이의 관계를 고려하여 단어 벡터에 좀 더 실용적인 의미 추가. "the"와 같은 무의미한 stop words에 가중치를 낮게 줌
- 단점 : 계산 복잡성이 높고 메모리를 많이 필요로 함. 특히, 동시 발생 행렬과 관련된 하이퍼 파라미터를 변경하는 경우 행렬을 다시 재구성해야 하므로 시간이 많이 걸림. 반대 단어 쌍을 분리하는 방법. 예를 들어, "양호한"및 "나쁜"은 일반적으로 벡터 공간에서 서로 매우 가깝게 위치하므로 정서 분석과 같은 NLP 작업에서 단어 벡터의 성능이 제한(Word2Vec도 동일한 문제를 안고 있음)
패키지 설치
더보기
- pip install glove\_python
- 설치가 안되면, mingw-w64를 설치해야 함
- [https://sourceforge.net/projects/mingw-w64/files/Toolchains%20targetting%20Win32/Personal%20Builds/mingw-builds/installer/mingw-w64-install.exe/download](https://sourceforge.net/projects/mingw-w64/files/Toolchains%20targetting%20Win32/Personal%20Builds/mingw-builds/installer/mingw-w64-install.exe/download) 그래도 안되면, conda install libpython과 pystan을 재 설치후에 다음의 링크에 따라서 직접 설치하는 방법이 있음
- https://github.com/maciejkula/glove-python/wiki/Installation-on-Windows 그래도 안되면, https://github.com/JonathanRaiman/glove/issues/1의 이슈대로 해결하면 됨
- pip install glove==1.0.0 이걸로 결국엔 해결된 줄 알았으나 실패
FastText
- 개념 : Facebook에서 개발한 word embeddings과 text classification 용도의 라이브러리로 294개의 언어에 대해 학습된 모델을 가지고 있음. (Word2vec이 영어에만 잘되는 것에 비해 FastText는 많은 언어에 대해서도 잘된다는 장점이 있음). 기본적인 모델은 Word2vec의 확장판으로 구성 단어에 대한 벡터를 생성(포함된 문자의 하위 문자열로 구성된 벡터로 만들어짐, 이를 통해 word2Vec은 어휘가 없는 단어를 볼 경우 아무것도 모르지만, fast Text는 어느 정도 모방을 함)
- 장점 : n-grams에서도 유연함. 어휘가 없는 단어를 볼 경우 아무것도 모르지만, fast Text는 어느정도 모방을 함. 동시 등장 정보를 보존
- 단점 : Supervised learning으로 학습하는데 많은 양의 데이터가 필요.
참고자료
- Word2vec의 학습방식 :https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
- 딥러닝을 위한 자연어처리 입문 :https://wikidocs.net/24949
- Word2Vec & FastText (이론) :https://inspiringpeople.github.io/data%20analysis/word_embedding/
- GloVe, word representation :https://lovit.github.io/nlp/representation/2018/09/05/glove/
- What are the advantages and disadvantages of Word2vec and GloVe? : https://www.quora.com/What-are-the-advantages-and-disadvantages-of-Word2vec-and-GloVe
'EDA Study > 머신러닝' 카테고리의 다른 글
| 범주형 변수의 인코딩 방법 (0) | 2021.03.15 |
|---|---|
| Dataprep.eda : Accelerate your EDA (EDA 자동화 패키지) (3) | 2020.04.15 |
| 교호작용 (0) | 2020.03.22 |
| Feature selection using target permutation (Null Importance) (0) | 2019.09.11 |
| Attn: Illustrated Attention (0) | 2019.09.11 |
'EDA Study/머신러닝' Related Articles
more


