
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Semantic Segmentation
- pytorch
- 협업필터링
- MySQL
- Python
- Object Detection
- 나는 리뷰어다
- 알고리즘
- TEAM-EDA
- hackerrank
- Recsys-KR
- Image Segmentation
- 파이썬
- DFS
- 튜토리얼
- TEAM EDA
- Machine Learning Advanced
- eda
- Segmentation
- DilatedNet
- 프로그래머스
- 3줄 논문
- 큐
- 입문
- 추천시스템
- 코딩테스트
- 나는리뷰어다
- 스택
- 한빛미디어
- 엘리스
- Today
- Total
TEAM EDA
EDA (Exploratory Data Analysis) 탐색적 데이터 분석 본문
EDA (Exploratory Data Analysis) 탐색적 데이터 분석
김현우 2018. 11. 12. 15:361.EDA란?
1) 정의
수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정입니다. 한마디로 데이터를 분석하기 전에 그래프나 통계적인 방법으로 자료를 직관적으로 바라보는 과정입니다.
2) 필요한 이유
-
데이터의 분포 및 값을 검토함으로써 데이터가 표현하는 현상을 더 잘 이해하고, 데이터에 대한 잠재적인 문제를 발견할 수 있습니다. 이를 통해, 본격적인 분석에 들어가기에 앞서 데이터의 수집을 결정할 수 있습니다.
-
다양한 각도에서 살펴보는 과정을 통해 문제 정의 단계에서 미쳐 발생하지 못했을 다양한 패턴을 발견하고, 이를 바탕으로 기존의 가설을 수정하거나 새로운 가설을 세울 수 있습니다.
3) 과정
기본적인 출발점은 문제 정의 단계에서 세웠던 연구 질문과 가설을 바탕으로 분석 계획을 세우는 것입니다. 분석 계획에는 어떤 속성 및 속성 간의 관계를 집중적으로 관찰해야 할지, 이를 위한 최적의 방법은 무엇인지가 포함되어야 합니다.
-
분석의 목적과 변수가 무엇이 있는지 확인. 개별 변수의 이름이나 설명을 가지는지 확인
-
데이터를 전체적으로 살펴보기 : 데이터에 문제가 없는지 확인. head나 tail부분을 확인, 추가적으로 다양한 탐색(이상치, 결측치 등을 확인하는 과정)
-
데이터의 개별 속성값을 관찰 : 각 속성 값이 예측한 범위와 분포를 갖는지 확인. 만약 그렇지 않다면, 이유가 무엇인지를 확인.
-
속성 간의 관계에 초점을 맞추어, 개별 속성 관찰에서 찾아내지 못했던 패턴을 발견 (상관관계, 시각화 등)
2. 이상값을 찾아내는 부분
데이터에 이상치가 있으면, 이상치가 왜 발생했는지 의미를 파악하는 것이 중요합니다. 그리고 그러한 의미를 파악했으면 어떻게 대처해야 할지(제거, 대체, 유지 등)를 판단해야 합니다. 이상치를 발견하는 기법은 여러 가지가 있고 대표적으로 아래와 같은 방법들이 있습니다.
1. 개별 데이터 관찰
데이터값을 눈으로 쭉 훑어보면서 전체적인 추세와 특이사항을 관찰할 수 있습니다. 데이터가 많다고 앞부분만 보면 안 되고, 인덱스에 따른 패턴이 나타날 수도 있으므로 앞, 뒤 or 무작위로 표본을 추출해서 관찰해야 합니다. 단, 이상치들은 작은 크기의 표본에 나타나지 않을 수 있습니다.
2. 통계 값 활용
적절한 요약 통계 지표(summary statistics)를 사용할 수 있습니다. 데이터의 중심을 알기 위해서는 평균(mean), 중앙값(median), 최빈값(mode)을 사용할 수 있고 데이터의 분산을 알기 위해 범위(range), 분산(variance)을 사용할 수 있습니다. 통계 지표를 이용할 때는 데이터의 특성에 주의해야 합니다. 예를 들어, 평균에는 집합 내 모든 데이터 값이 반영되기 때문에, 이상치가 있으면 값이 영향을 받지만, 중앙값에는 가운데 위치한 값 하나가 사용되기 때문에 이상치의 존재에도 대표성이 있는 결과를 얻을 수 있습니다. 회사 직원들의 연봉에 대해서 평균을 구하면, 대개 중간값보다 훨씬 높게 나오는데, 그것은 몇몇 고액 연봉자가 평균을 끌어올렸기 때문입니다.
3. 시각화 활용
일단은 시각적으로 표현이 되어있는 것을 보면, 분석에 도움이 많이 됩니다. 시각화를 통해 주어진 데이터의 개별 속성에 어떤 통계 지표가 적절한지 결정할 수 있습니다. 시각화 방법에는 확률밀도 함수, 히스토그램, 점 플롯(dotplot), 워드 클라우드, 시계열 차트, 지도 등이 있습니다.
4. 머신러닝 기법 활용
대표적인 머신러닝 기법으로 K-means를 통해 이상치를 확인 할 수 있습니다.
5. 그 외의 이상치 발견 기법들
| 이상치 찾는 기법 | 예시 |
| Statistical-based Detection | Distribution-based, depth-based |
| Deviation-based Method | Sequential exception, OLAP data cube |
| Distance-based Detection | Index-based, nested-loop, cell-based, local-outliers |
[표1] 그 외의 다양한 이상치 발견 기법들
3. 속성 간의 관계 분석하기
이 과정의 목표는 서로 의미 있는 상관관계를 갖는 속성의 조합을 찾아내는 것입니다. 여기서부터 사실상 본격적인 탐색적 분석이 시작됩니다. 분석의 대상이 되는 속성의 종류에 따라, 방법도 달라져야 합니다. 아래의 [표 2]은 데이터의 종류를 보여줍니다.
|
Categorical Variable (Qualitative) |
Nominal Data
|
원칙적으로 숫자로 표시할 수 없으나, 편의상 숫자화. (순위의 개념이 없음) 예시) 남자-0, 여자-1 |
|
Ordinal Data
|
원칙적으로 숫자로 표시할 수 없으나, 편의상 숫자화. (순위의 개념이 있음) 예시) 소득분위 10분위 > 9 분위 > 8 분위 |
|
|
Numeric Variable (Quantitative)
|
Continuous Data |
데이터가 연속량으로서 셀 수 있는 형태. 예시) 키 - 166.1cm |
|
Discrete Data |
데이터가 비연 속량으로서 셀 수 있는 형태 예시) 자식 수 5명 |
[표 2] Qualitative Data vs Quantitative Data
|
데이터 조합 |
요약 통계 |
시각화 |
|
Categorical - Categorical |
교차 테이블 |
모자이크 플롯 |
|
Numeric - Categorical |
카테고리별 통계 값 |
박스 플롯 |
|
Numeric - Numeric |
상관계수 |
산점도 |
[표 3] 데이터 조합 별 통계 및 시각화 방법
1. Categorical - Categorical
교차 테이블, 모자이크 플롯을 이용해 각 속성 값의 쌍에 해당하는 값 개수를 표시할 수 있습니다.
2. Numeric - Categorical
각 카테고리별 통계 값(평균, 중간값 등)을 관찰할 수 있다. 이를 박스 플롯을 통해 시각적으로 표현할 수 있습니다.
3. Numeric - Numeric
상관계수를 통해 두 속성 간의 연관성을 나타낼 수 있습니다. -1은 두 속성이 반대 방향으로 변하는 음의 상관관계를 나타냅니다. 0은 상관관계없음을 나타내고 1은 두 속성이 항상 같은 방향으로 변하는 양의 상관관계를 나타냅니다. 상관계수를 갖는 두 속성의 관계도 다양한 양상을 띨 수 있는데, 스케터 플롯을 이용하여 이를 시각적으로 표현할 수 있습니다.
또, 분석을 하다 보면, 2개 이상의 속성 간의 관계를 보고 싶을 때가 있습니다. 그럴 땐 위에서 나타낸 그래프를 3차원으로 표현하거나, 그래프 위에 표현된 점을 색상을 이용하거나 모양을 달리하여 더 많은 속성을 나타낼 수 있습니다. 혹은 각 점을 텍스트로 표현할 수도 있을 것입니다.
4. 실습
실습은 Kaggle에 올라와 있는 Titanic데이터(https://www.kaggle.com/c/titanic)를 가지고 진행한다. 모든 소스코드는 Titanic Tutorial with Python이라는 커널에 올라와있습니다.
먼저 분석의 목적과 데이터가 어떤 식으로 구성되었는지 살펴봐야 합니다.
Objective : 승객의 정보를 보고 타이타닉에서 생존했을지 아닐지를 분류
Variable Description
|
변수 이름 |
설명 |
|
Survived |
1 : 생존, 0 : 사망 |
|
Pclass |
1 : 1등석, 2 : 2등석, 3 : 3등석 |
|
Name |
승객 이름 |
|
Sex |
승객의 성별 |
|
Age |
승객의 나이 |
|
Sibsp |
함께 탑승한 형제 또는 배우자의 수 |
|
Parch |
함께 탑승한 부모 또는 자녀의 수 |
|
Ticket |
티켓 번호 |
|
Fare |
티켓 요금 |
|
Cabin |
선실 번호 |
|
Embarked |
탑승한 항구 |
[표 3] 데이터 조합 별 통계 및 시각화 방법
위의 분석의 목적은 어떤 정보를 가진 승객이 타이타닉에서 생존했을지 분류하는 것입니다. 즉, Survived라는 변수를 1과 0으로 잘 분류하는 것이고, 이를 위해서 우리는 고객의 개인정보(이름, 성별, 나이 등)와 그 외 정보(티켓 번호, 요금, 선실 번호 등)들을 통해서 생존과 연관이 있는 주요한 정보들을 찾아내야 합니다.
먼저 데이터의 head()와 tail()을 살펴보면서, 데이터가 어떤 식으로 구성되었는지 확인합니다.


이런 간단한 방법으로 데이터에 대해서 여러 가지 분석 방향을 정할 수 있습니다.
- Fare의 경우 사람들마다 값의 차이가 큰데, 어떤 식으로 구성된 것일까?
-
Name의 경우 정해진 형식이 없이 누구는 괄호가 있고, 누구는 ""이 있는 것을 확인할 수 있습니다.
-
Sex의 경우 문자형태로 데이터가 제공되어서 컴퓨터가 인식하기 위해서는 Encoding이 필요합니다.
-
Ticket의 경우 숫자로만 이루어진 값과 알파벳이 섞인 것이 있습니다. (특별한 의미가 있는지 확인이 필요)
-
Cabin과 Age에서 결측치(NaN)가 보입니다.
-
Embarked의 값이 S, C, Q, 가 보이는데 각각이 어떤 의미인지를 확인해야 합니다.
이런 점을 기억해놓고, 시각화 및 이상치, 결측치에 대해서 자세히 탐색을 시작해야 합니다. 위의 점들을 확인 한 다음에는 본격적으로 이상치와 결측치, 시각화에 대해서 분석해야 한다. 결측치의 처리와 관련해서는 결측치 처리(Missing Value)에서 자세히 다루었으니 이번 자료에서는 이상치와 시각화에 대해서만 보겠습니다.
위에서 살펴본 Fare에 대해서 어떤 속성 값을 가지고 있는지 살펴보겠습니다. 파이썬에서는 describe()라는 함수를 통해서 해당 변수가 가지고 있는 통계 값을 볼 수 있습니다. 값을 보면, 평균적으로 32를 지불하는 반면에 0과 512를 지불한 사람도 있습니다. 비행기를 생각해보면 어린아이의 경우 돈을 받지 않고, 이코노미 클래스보다는 비즈니스 클래스가 가격이 비슷한 것을 생각해볼 수 있습니다. 그리고 각 승객들이 탑승한 항구가 다르니 거리에 따라서 비용이 다르게 측정되었을 수도 있습니다. 이런 가설들을 가지고 실제 위의 가설이 맞는지 확인해보도록 하겠습니다.

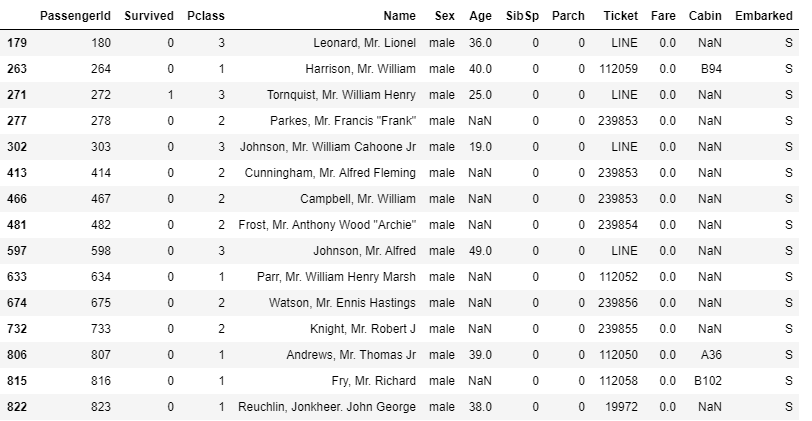

먼저 탑승 요금이 500이 넘는 승객부터 살펴보면 1등급 클래스를 타고 있는 것을 확인할 수 있습니다. 그리고 Ticket의 표기가 같고 나이대가 비슷한데, 친구들끼리 티켓을 한 번에 결제해서 512.3292라는 동일한 값이 나오지 않았을까 하는 생각도 얻을 수 있습니다.
탑승 요금이 0인 승객을 살펴보면, 기존의 예상과는 다르게 나이가 20살 이상인 사람들이 많고 나이가 결측치인 사람이 많습니다. 그리고 실제 5살 미만인 승객들에 대해서도 Fare이 있는 경우가 많기에 위의 가설이 틀렸다는 것을 확인할 수 있습니다.

그렇다면, 왜 요금이 0인 승객이 있을까요? 위의 그림 5를 다시 보면 Embarked가 모두 S인 것을 볼 수 있고 몇몇은 티켓이 LINE인 것을 볼 수 있습니다. 추측하건대 그들은 승객이 아니라 승무원들이거나 승무원들의 가족일 수 있습니다. 아니면 이벤트성으로 티켓을 초대받았을 가능성도 있습니다. 그렇기에 LINE 티켓을 가진 사람은 모두 Pclass가 3으로 배정받은 것일 수 있습니다.
위와 같이 통계적인 기법과 간단한 분석으로 이상치를 확인한 후에 다른 변수들 간의 관계를 보겠습니다. 그 이유는 통계적인 이상치의 단점은 단변량 분석을 하기 때문에 다른 변수들간의 관계에 따라서 파악하기 어렵습니다. 그래서 위에서 언급한 Fare와 밀접한 연관이 있을만한 변수인 탑승장소(Embarked)를 같이 시각화해서 보겠습니다.
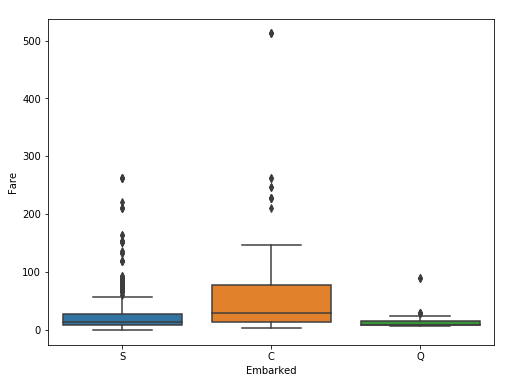
위의 그림을 보면 각각의 탑승 항구에 따라서 이상치가 나타나는 것을 확인할 수 있고, 특히나 C에서의 이상치는 다른 값들과는 달리 멀리 떨어져 있는 것을 확인할 수 있습니다. [그림 4]에서 본 것처럼 좋은 Pclass를 이용하고 있고, VIP석의 티켓을 사용해서로 판단됩니다. 1등급에서도 급이 나뉘는 것 같습니다. 실제로 같은 Pclass 내에서도 요금차이가 큰 것을 볼 수 있습니다.

Fare에 대한 변수 하나만을 살펴보는 데에도 많은 가설이 생겼고 다양한 방식으로 확인해볼 수 있었습니다. Titanic에 대한 분석자료는 정리하는 대로 전체 내용에 대한 코드와 분석 자료를 올리도록 하겠습니다. 다른 참고할 만한 데이터 탐색 자료로는 캐글의 House Prices에 대해서 분석한 [Kaggle] House Prices: Advanced Regression Techniques를 참고하시기 바랍니다. 그리고 EDA를 편하게 하는 도구에 관심있는 분께서는 Dataprep.eda : Accelerate your EDA (EDA 자동화 패키지)를 참고하시기 바랍니다.
참고자료
'TEAM EDA > EDA 1기 ( 2018.03.01 ~ 2018.09.16 )' 카테고리의 다른 글
| kaggle - Rossmann Store sales Prediction (1) (0) | 2019.09.10 |
|---|---|
| Decision Tree (의사결정나무) (0) | 2019.09.10 |
| linear regression (선형회귀분석) with R (0) | 2019.09.10 |
| 결측치 처리 (Missing Value) (3) | 2018.11.12 |
| TEAM-EDA 1기 활동 내역 (0) | 2018.11.12 |


