
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Segmentation
- pytorch
- MySQL
- 스택
- TEAM-EDA
- DFS
- hackerrank
- 큐
- 코딩테스트
- 3줄 논문
- 추천시스템
- 엘리스
- 한빛미디어
- DilatedNet
- Recsys-KR
- 나는 리뷰어다
- Image Segmentation
- 튜토리얼
- 알고리즘
- 입문
- 프로그래머스
- 나는리뷰어다
- Machine Learning Advanced
- TEAM EDA
- Semantic Segmentation
- eda
- 협업필터링
- Python
- Object Detection
- 파이썬
- Today
- Total
목록전체 글 보기 (287)
TEAM EDA
 Introductory Guide – Factorization Machines & their application on huge datasets (with codes in Python)
Introductory Guide – Factorization Machines & their application on huge datasets (with codes in Python)
참고 : https://www.analyticsvidhya.com/blog/2018/01/factorization-machines/ 링크의 글을 번역한 글입니다. Introduction 나는 아직도 클릭 예측 문제로 처음 만났던 순간을 기억합니다. 이전에는 나는 데이터 과학을 배우고 있었고 나의 진전에 대해 기분이 좋았습니다. ML hackathons에 대한 자신감을 갖기 시작했고 나는 몇 가지의 도전을 하기로 결심했습니다. 더 잘하기 위해서, 나는 16GB RAM과 i7 프로세서를 갖춘 기계를 조달했습니다. 그러나 데이터 세트를 처음 보았을 때 불안감이 있었습니다. 압축을 풀 때의 데이터는 50GB 이상이었습니다. 그런 데이터 세트의 클릭을 예측하는 방법을 알지 못했습니다. 고맙게도 Factorizat..
 [Kaggle] Google Analytics Customer Revenue Prediction
[Kaggle] Google Analytics Customer Revenue Prediction
Google Analytics Customer Revenue PredictionPredict how much GStore customers will spend 대회 목적 80/20 규칙은 많은 비즈니스에서 입증되었습니다. 적은 수의 고객 만이 대부분의 수익을 창출합니다. 따라서 마케팅 팀은 홍보 전략에 대한 적절한 투자를 유도해야합니다. RStudio는 팀을 위해 작업을 확장하고 공유 할 수있는 R 및 기업용 제품을위한 무료 및 개방형 도구 개발자로, Google Cloud 및 Kaggle과 파트너 관계를 맺어 철저한 데이터 분석에서 얻을 수있는 비즈니스 영향을 보여줍니다. 이 경쟁에서 고객 당 수익을 예측하기 위해 Google Merchandise Store (Google 판매원이 판매되는 GStore..
 Day 18 : The Bootstrap
Day 18 : The Bootstrap
*가볍게 시작하는 통계학습 3주차 Day 4*교재 5.2입니다. (영문: 187p~190p, 국문:214p~217p)The Bootstrap (11:29)https://www.youtube.com/watch?v=p4BYWX7PTBM&list=PL5-da3qGB5IA6E6ZNXu7dp89_uv8yocmf 1. 부트스트랩 Example 위의 내용을 요약하면 아래와 같습니다. 두가지 재정자산 A와 B에 투자를 했을 때, A는 X라는 return을 B는 Y라는 return을 내놓습니다. 그래서 A에는 얼마를 B에는 얼마를 투자할지 수익을 최대화하는 비율(알파)를 정해야 합니다. 여기에서는 그러한 방법을 Bootstrap이라는 방법을 도입하여 해결합니다. Bootstrap은 복원샘플입니다. 여기에서는 전체 dat..
*가볍게 시작하는 통계학습 3주차 Day 3*교재 5.1.4, 5.1.5입니다. (영문: 183p~187p, 국문:210p~214p)Cross-Validation: The Right and Wrong Ways (10:07)https://www.youtube.com/watch?v=S06JpVoNaA0&list=PL5-da3qGB5IA6E6ZNXu7dp89_uv8yocmf 개인적으로 이 부분은 필요없어 보입니다.
 Day 16 : K-fold Cross-Validation
Day 16 : K-fold Cross-Validation
가볍게 시작하는 통계학습 3주차 Day 2 교재 5.1.2, 5.1.3을 공부하시면 됩니다. (영문: 178p~182p, 국문:205p~210p)K-fold Cross-Validation(13:33)https://www.youtube.com/watch?v=nZAM5OXrktY&list=PL5-da3qGB5IA6E6ZNXu7dp89_uv8yocmf K-fold Cross-Validation K-Fold Cross Validation은 Validation 과정을 총 K번 하는것을 의미합니다. 가운데 KFOLD 이미지는 4-Fold의 경우입니다. 트레인 / Validation을 4개로 나누어서 모든 데이터를 학습에 참여시키려는 목적을 가지고 있습니다. 만일 K가 데이터의 사이즈와 똑같은 경우에는 마지막 그림인..
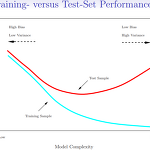 Day15 : Resampling Methods
Day15 : Resampling Methods
Ch5: Resampling Methods *슬라이드*https://lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/cv_boot.pdf 교재 5.1.1을 공부하시면 됩니다. (영문: 176p~178p, 국문:202p~205p) *강의*Estimating Prediction Error and Validation Set Approach (14:01)https://www.youtube.com/watch?v=_2ij6eaaSl0&list=PL5-da3qGB5IA6E6ZNXu7dp89_uv8yocmf Training - versus Test set Training Sample에 대해 에러를 구하는 것은 Training Error이고 Test Sam..
 [Kaggle] House Prices: Advanced Regression Techniques
[Kaggle] House Prices: Advanced Regression Techniques
이번 EDA 2기 첫 프로젝트로 진행했던 kaggle의 House Prices: Advanced Regression Techniques(https://www.kaggle.com/c/house-prices-advanced-regression-techniques)에 대한 분석 보고서입니다. 추가적으로 해당 내용에 대해 결측치 처리와 모델의 변수 중요도에 대한 해석이 들어간 자료는 [Kaggle] House Prices: Advanced Regression Techniques(2)를 참고하시기 바랍니다. 집의 가격을 예측하는 문제로 사용한 모델은 ridge,lasso, Elastic Net, LightGBM, Xgboost입니다. 최종적으로 성적을 올리기위해 다른 사람들의 결과물을 반영해 추가적으로 앙생블을 ..
 Day13 : 2주차 질의응답
Day13 : 2주차 질의응답
1. 회귀를 사용하기 적절하지 않은 경우는 어떤 경우이며 회귀와 분류의 차이는 무엇인가? 반응변수가 Categorical한 경우에 회귀를 사용하기 힘듭니다. 그 이유는 프린트에 나와있듯이 클래스별 차이를 인식하기 때문입니다. 추가로 0~1사이를 예측할 경우 0이하 or 1이상도 예측가능하기 때문입니다. 분류는 회귀와는 다르게 어떠한 class에 속할지 categorical하게 예측하는 것입니다. 2. 로지스틱 모델에서 사용되는 odds는 무엇인가? odds는 https://t1.daumcdn.net/cfile/tistory/9988AA395BF85AF10C의 링크의 식과 같습니다. 3. 신용카드 대금을 연체할 공산(odds)이 0.28인 사람 중 평균 몇 퍼센트가 실제로 연체할 것인가? 위의 식이 0.2..
 Day12 : QDA and Naive Bayes
Day12 : QDA and Naive Bayes
이번주 슬라이드: https://lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/classification.pdf 교재 4.4 중 4.4.4와 4.5를 공부하시면 됩니다. (영문: 149~153p, 국문: 172 ~ 178p)*Quadratic Discriminant Analysis and Naive Bayes (10:07)*https://www.youtube.com/watch?v=6FiNGTYAOAA&list=PL5-da3qGB5IC4vaDba5ClatUmFppXLAhE 1. Quadratic Discriminant Analysis ... 2. Naive Bayes 3. LDA 4. Summary 로지스틱 회귀 분석은 특히 K = 2인 경..
 Day11 : Multivariate Linear Discriminant Analysis and ROC Curves
Day11 : Multivariate Linear Discriminant Analysis and ROC Curves
이번주 슬라이드: https://lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/classification.pdf 교재 4.4 중 4.4.3을 공부하시면 됩니다. (영문: 142~148p, 국문: 164 ~ 172p)*Multivariate Linear Discriminant Analysis and ROC Curves (17:42)-4.4.3 (Fri)*https://www.youtube.com/watch?v=X4VDZDp2vqw&list=PL5-da3qGB5IC4vaDba5ClatUmFppXLAhE 1. From δk(x) to probabilities 2. Error의 종류 여기서 error의 종류가 여러개가 나오는데 아래의 표의 값들만..