
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Semantic Segmentation
- 추천시스템
- 나는 리뷰어다
- pytorch
- 3줄 논문
- TEAM EDA
- 한빛미디어
- Object Detection
- TEAM-EDA
- 협업필터링
- 큐
- DilatedNet
- 코딩테스트
- 엘리스
- 튜토리얼
- 스택
- Recsys-KR
- Image Segmentation
- eda
- Machine Learning Advanced
- 입문
- 알고리즘
- 파이썬
- DFS
- 프로그래머스
- Segmentation
- hackerrank
- 나는리뷰어다
- MySQL
- Python
- Today
- Total
TEAM EDA
[Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (연속형 변수) 본문
[Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (연속형 변수)
김현우 2023. 8. 17. 18:12연속형 변수를 전처리해야하는 이유는 무엇이 있을까요?
첫째, 일부 머신러닝 알고리즘은 입력 변수의 스케일에 따라 영향을 받아 학습이 불안정할 수 있습니다.

예를들어, 최근접이웃모델(KNN)의 경우 스케일의 전 후에 따라서 모델의 결과가 완전히 달라집니다.
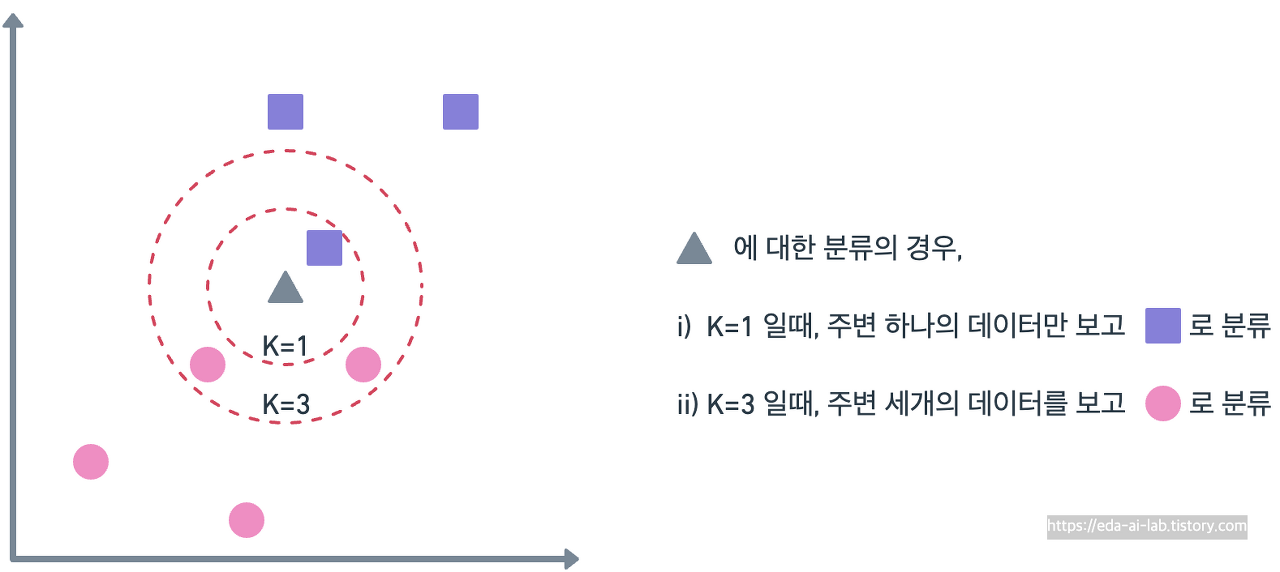
해당 모델의 경우 간단하게 설명하면 새로운 입력이 들어왔을때 자신과 거리가 가까운 K개의 다른 데이터와 거리를 통해 분류 (or 회귀)를 수행하는 방법입니다.

하지만, 하나의 변수의 스케일이 너무 클 경우 거리의 계산이 해당 변수에 의해서만 진행됩니다. 유킬리디안 거리를 통해 보면 x가 proline, y가 hue로 보면거리가 proline 부분이 (800-700)^2으로 만단위이고 hue가 (1-0)^2으로 일의 단위라서 proline 변수에 의해서 결과가 결정되는 문제가 발생하기에 스케일의 조정의 전처리를 통해 모델이 원하는 결과를 만들도록 도와줍니다.
둘째, 변환을 통해 비선형 관계를 포착할 수 있습니다.

위의 그래프를 보면 선형 회귀모델이 Data와 Target 사이의 비선형 관계를 정확히 예측하지 못하는 것을 볼 수 있습니다. 따라서, 모델이 이러한 비선형 관계를 쉽게 파악할 수 있도록 로그 변환 등의 전처리를 통해 비선형성을 포착하게 만들 수 있습니다.
셋째, 정규성 가정을 만족시킬 수 있습니다.

선형회귀와 같은 모델이나 특정 분석등은 데이터의 정규성을 가정합니다. 이런 모델들의 가정을 만족시켜주기위해서 로그 변환, 제곱근 변환, Box-Cox 변환 등을 통해 데이터의 정규성을 만족시켜 모델이 제대로 작동할 수 있습니다.
넷째, 이상치의 처리가 가능합니다.

일부 이상치가 있는 부분을 삭제해줄 수도 있고, 이상치에 덜민감해지도록 로그 변환 등의 변환 방법을 적용해줄 수 있습니다.
마지막으로, 모델의 복잡성과 데이터의 크기를 감소시킬 수 있습니다.

실제 Binning이라는 연속형 변수를 특정 구간으로 나누는 방법을 적용했을때, 의사결정나무라는 모델의 결과입니다. 왼쪽의 경우 많은 분할을 수행해서 모델이 복잡해지는 모습을 보이지만 오른쪽은 좀 더 단순해지는 모습을 보입니다. 그리고, 데이터의 입장에서도 float단위보다 Int단위가 메모리 측면에서 요구하는 양이 적어서 효과적입니다.
연속형 변수를 전처리하는 방법은 무엇이 있을까요?
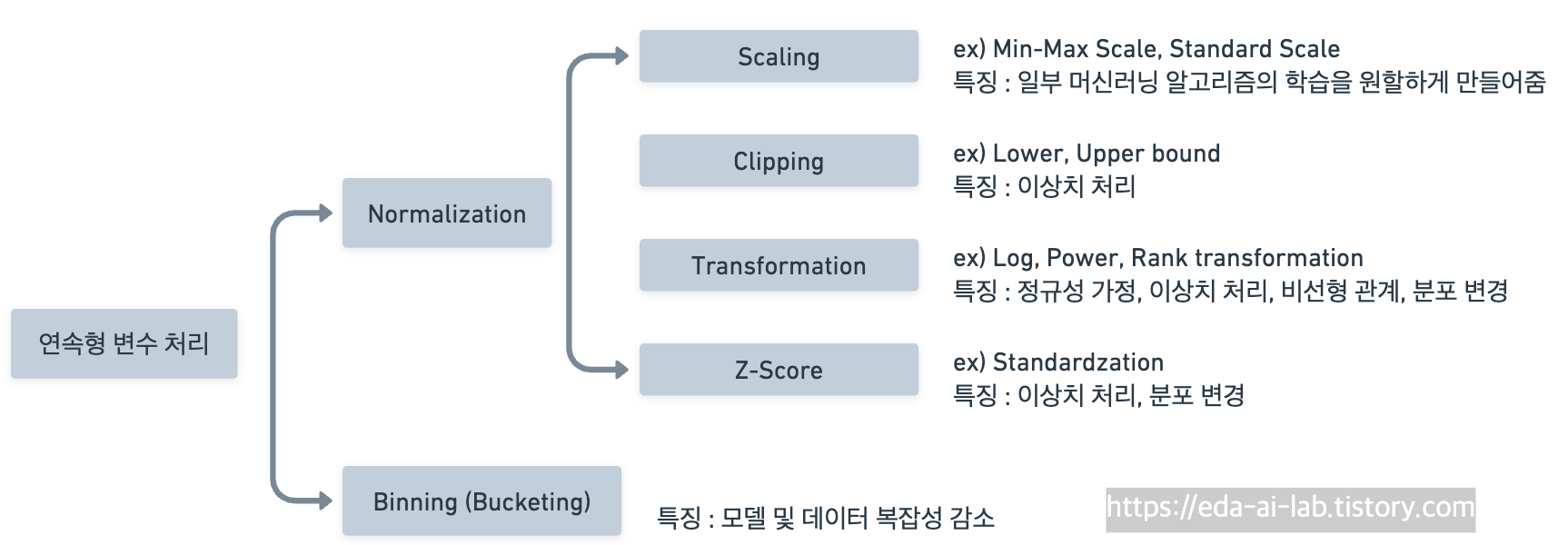
Normalization
먼저, Normalization에는 아래의 4가지 방법이 있습니다.

1. Scaling
Scaling은 입력값의 범위를 조정해주는 방법입니다.
스케일링 비교하는 부분 작성 필요
StandardScaler vs. MinMaxScaler vs. RobustScaler: Which one to use for your next ML project?
Data scaling is a method for reducing the effect of data bias on predictions which is highly used in pre-processing step in any Machine…
medium.com
대표적으로 Min-Max Scaling이라고 불리는 방법론이 있으며 딥러닝에서 입력을 전처리할때 많이 활용되며 KNN과 같은 모델의 스케일을 조정해줄때 사용할 수 있습니다. 단, Min-Max scaling은 실제 원본 데이터와 분포의 모습을 동일하게 유지하면서 범위를 조정하기에 이상치에 취약한 모습을 보이기도 합니다.
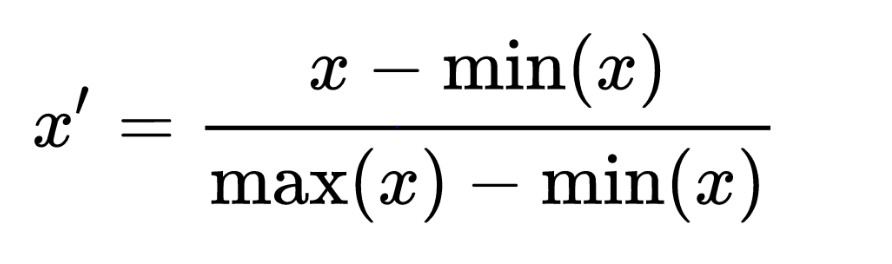
위와는 다르게 max와 min 대신에 분위수를 이용하여 이상치에 강건한 모습을 보이는 Robust Scaling이라는 기법도 존재합니다.

2. Clipping

Clipping은 특정 영역 이하 혹은 이상의 영역을 자르는 방법입니다. 데이터에 이상치가 포함되어있으면 특정 값을 기준으로 제거할 수 있습니다. 해당 방법만으로도 사용이 가능하지만, 이전 이후에 언급할 방법론들과 같이 결합해서 사용이 가능하며 이상치에 특히 취약한 방법들과 결합해서 사용하기에 좋습니다.
3. Transformation (변환)

Transformation은 로그 변환, 지수 변환, 제곱 변환 등 다양한 변환 방법으로 연속형 변수의 분포를 변환하는 방법입니다. 대표적인 로그 변환의 경우는 로그를 취해줘서 넓은 범위에서 좁은 범위로 줄여줍니다. 로그 변환의 식을 생각해보면
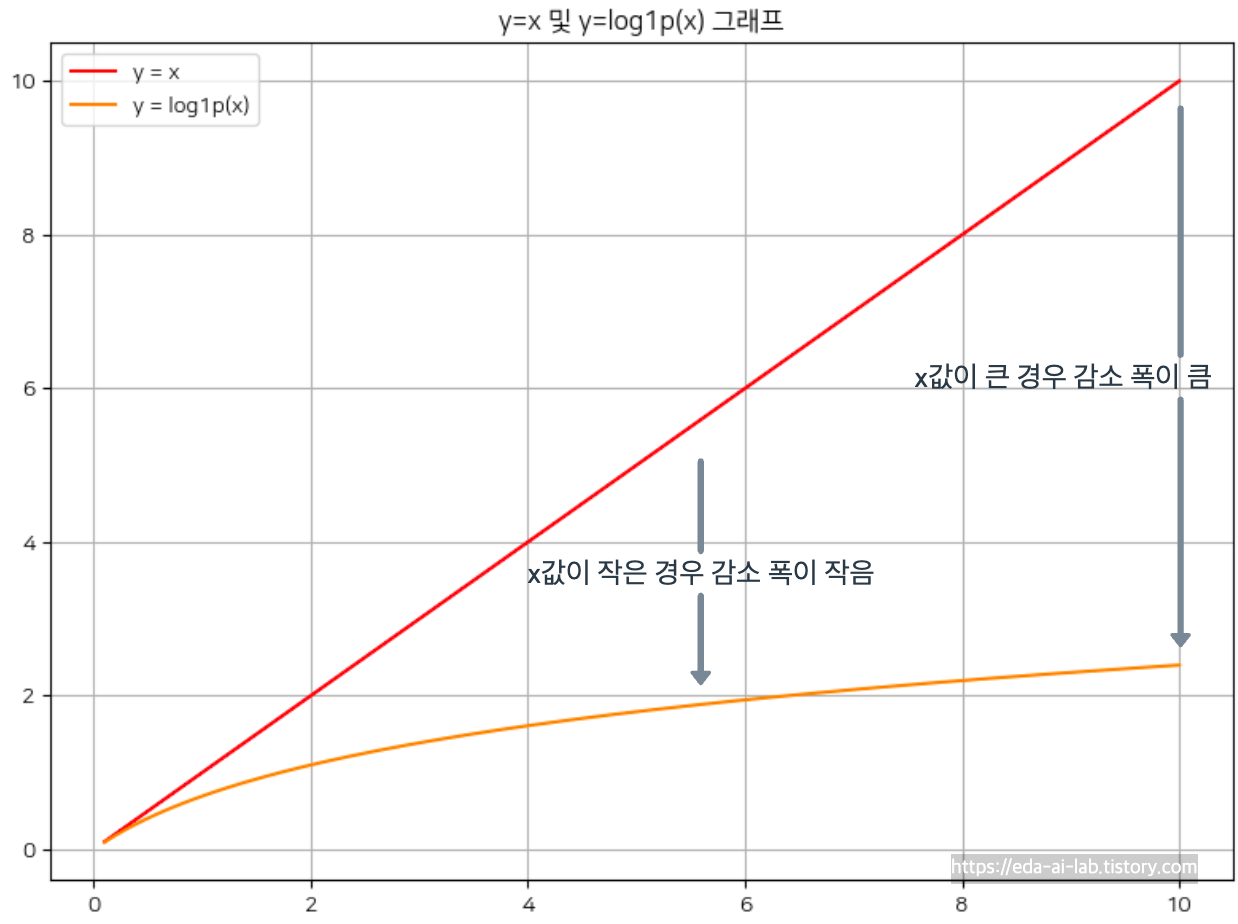

x의 크기가 커질 수록 감소 폭 또한 커지는 것을 생각할 수 있습니다. 그로인해 "상품의 가격", "집 값" 등 0부터 시작해서 우측으로 가격이 치우치는 모습을 보이는 연속형 변수에 적용했을때 좋은 모습을 보였던 경험이 있습니다. 하지만, log1p가 아닌 log를 취하게 될 경우 0~1 사이의 값은 오히려 커질 수가 있습니다. 그 외에도 Rank transformation 같은 방법도 존재하고 이상치가 있을때 MinMaxScaling보다 훨씬 좋은 모습을 보입니다.
4. Standardzation (Z-Score Normalization)

해당 방법은 평균은 0, 분산은 1이 되도록 조정해주는 방법입니다. 아웃라이어에 덜 영향을 받는다는 장점이 있으며, 변수가 정규분포나 가우시안 분포를 띌때 유용하다는 특징을 보입니다.
Binning (Bucketing)
Binning은 연속형 변수를 범주형 변수나 순서형 변수로 전환시키는 방법으로 모델의 복잡도나 데이터의 메모리를 줄여주는 장점이 있습니다. 이때, 구간의 크기를 동일하게 유지할 수도 있고 비율에 따라 유지할 수도 있습니다. 비율에 따라 유지하는 경우 극단적인 이상치가 존재해도 강건하게 대응할 수 있다는 장점이 있습니다.
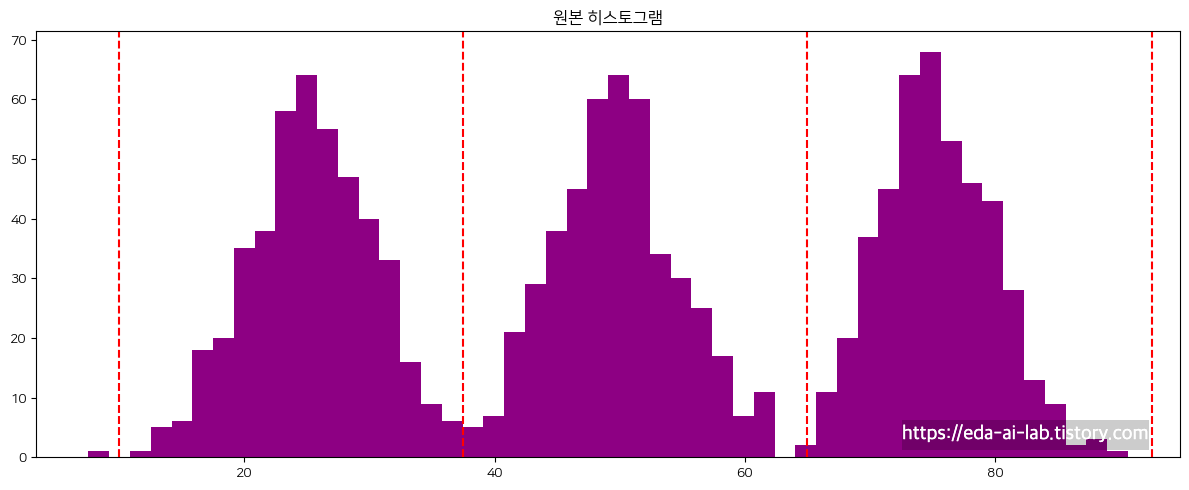
위의 그래프는 3개의 정규분포를 가지는 데이터가 합쳐진 모습입니다. 해당 그래프에 binning을 적용하면 각 분포별로 같은 분포인 것을 인식시켜줄 수 있습니다.
binning을 많이 사용하는 예시로 나이에 대한 예시가 있습니다.
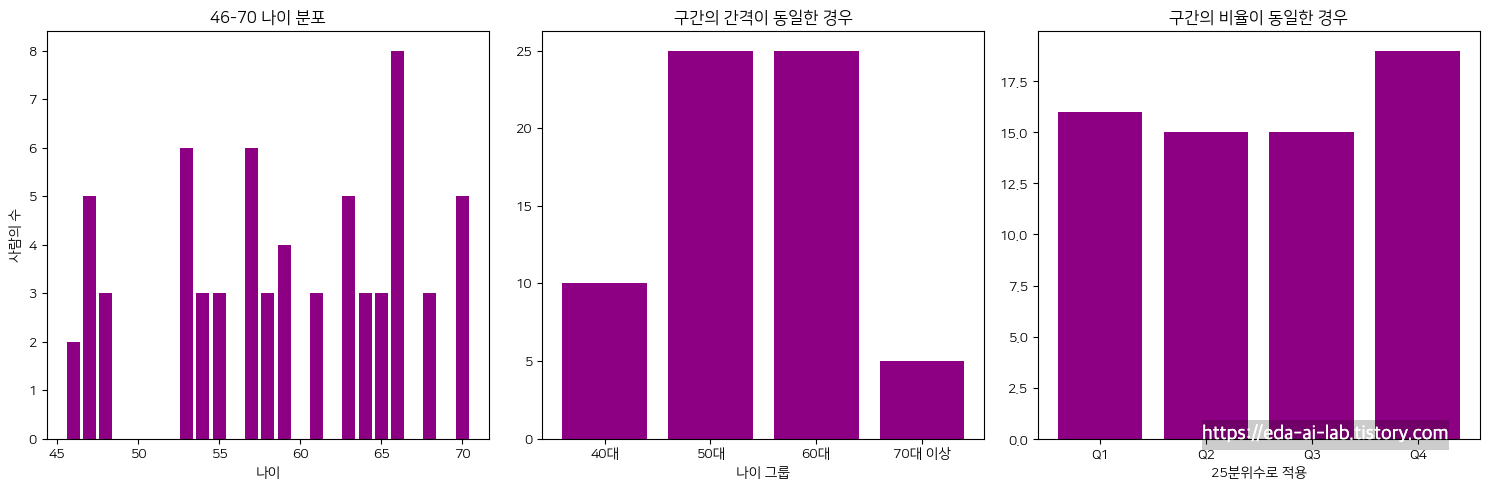
가운데처럼 구간을 정해서 구간화할 수도 있고, 마지막처럼 비율을 통해서 구간화 할 수도 있습니다.
3. 대회 및 현업 사례
해당 부분 조사 필요
참고자료
'EDA Study > Machine Learning Advanced' 카테고리의 다른 글
| [Machine Learning Advanced] 1강. 머신러닝 강의 - 강의 개요 (1) | 2023.10.01 |
|---|---|
| [Machine Learning Advanced] 8강. 머신러닝 강의 - 캐글에서 활용되는 알아두면 좋은 팁 (Tips) (5) | 2023.08.26 |
| [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (KNN) (3) | 2023.08.15 |
| [Machine Learning Advanced] 3강. 머신러닝 강의 - 파생 변수 만들기 (4) | 2023.08.14 |
| [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (의사결정 나무) (5) | 2023.08.12 |



