
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- TEAM-EDA
- eda
- MySQL
- 프로그래머스
- 스택
- 입문
- 튜토리얼
- 나는 리뷰어다
- 3줄 논문
- hackerrank
- 한빛미디어
- 파이썬
- pytorch
- Segmentation
- 추천시스템
- 나는리뷰어다
- Recsys-KR
- 엘리스
- 협업필터링
- Semantic Segmentation
- 코딩테스트
- DilatedNet
- Image Segmentation
- 큐
- 알고리즘
- Machine Learning Advanced
- TEAM EDA
- DFS
- Object Detection
- Python
- Today
- Total
TEAM EDA
[Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (선형 모델) 본문
[Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (선형 모델)
김현우 2023. 8. 11. 20:51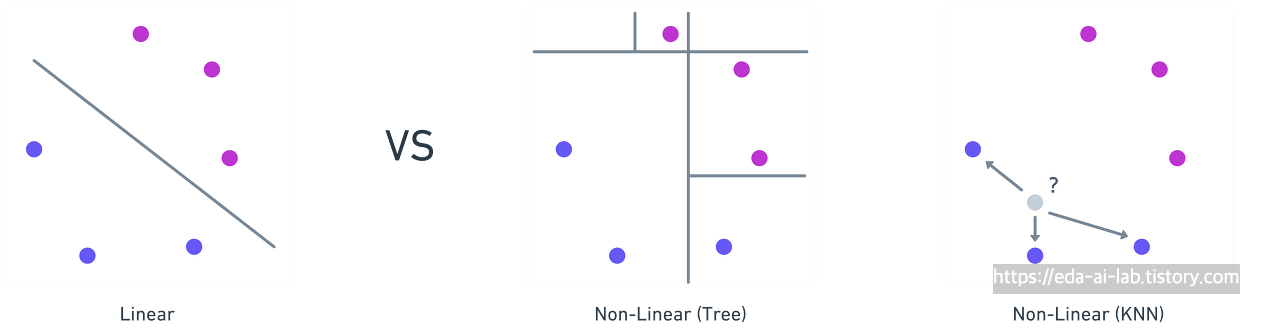
이번 강의에서는 머신러닝 모델 중에서도 특히, 선형 모델인 선형 회귀 (Linear Regression)에 대해 살펴보도록 하겠습니다. 선형 회귀가 어떤 것인지 개념에 대해 살펴본 후, 해당 모델의 장점, 주의해야할 점, 단점에 대해 살펴본 후 해당 모델의 한계를 개선할 모델인 Ridge, Lasso, ElasticNet에 대해 살펴보겠습니다.
선형 회귀란 무엇이고 왜 해야하는 것일까요?

선형 회귀는 x라는 독립변수(independent variable)에 대해서 y라는 종속변수(dependent variable)의 관계를 선형으로 학습하는 방법을 의미합니다. 여기서 독립변수 x가 한개인 경우 (ex. y = b0 + b1*x1)를 단순 선형 회귀라고 하고, x가 여러개인 경우를 다중 선형 회귀라고 부릅니다. 선형 회귀는 간단하고 해석하기 쉬우며, 일부 경우에는 충분한 성능을 제공할 수 있기에 해석력이 중요한 업무나 회사에서 아직도 많이 사용합니다.
선형 회귀란 어떻게 할 수 있을까요?
선형 회귀는 x와 y의 관계를 선형으로 잘 나타내는 가중치를 찾는 방식으로는 주로 최소자승법(Ordinary Least Square, OLS)을 사용합니다. 또한, 머신러닝에서는 경사 하강법(Gradient Descent)을 사용하여 손실 함수(로스 함수)를 최소화하여 가중치를 추정하기도 합니다.
1. 최소자승법 (OLS)
최소자승법은 종속 변수와 예측 값의 차이(잔차 = Residual)의 제곱 합 (Sum of Squared Residuals, SSE)을 최소화하는 가중치를 찾는 방법입니다.

선형 회귀에서 예측값 위와 같이 나타낼 수 있고, 여기서 w는 가중치 벡터를 X는 설계 행렬 (design matrix) 입니다. 이때, 잔차는 실제값과 예측값을 뺀 값으로

으로 표현할 수 있습니다. 잔차의 제곱합(Sum of Squared Residuals, SSE)는 잔차를 모두 더한 값이고

위와 같이 표현할 수 있습니다. (참고로, 잔차의 행렬을 내적한 것은 각 요소를 잔차 벡터의 성분을 제곱하여 더했다는 의미로 잔차의 제곱합과 동일합니다)
위의 수식에서 우리는 L을 최소화하는 w (= x와 y의 관계를 선형으로 잘 나타내는 가중치)을 얻기를 원합니다. 고등학교때 이런 경우 미분을 해서 0이 되는 지점이 최소값을 가지는 w임을 배웠고,

미분을 한 위의 수식이 0이 되는 w 값을 아래와 같이 얻을 수 있습니다.

2. 경사하강법 (Gradient Descent)
최소자승법이 아닌 딥러닝에서 주로 사용하는 경사 하강법을 이용하여 w를 계산할 수도 있습니다. 경사 하강법은 손실 함수(위에서는 잔차의 제곱합)의 그래디언트(미분 값)을 사용하여 함수 값을 최소화하는 방향으로 가중치를 반복적으로 조정하는 방법입니다. 초기 가중치를 임의로 선택한 후, 손실 함수의 그래디언트를 계산하고, 이 그래디언트의 반대 방향으로 가중치를 조금씩 업데이트합니다.

위와 같이 새로운 가중치를 기존의 가중치에서 α (학습률)의 크기만큼 업데이트 시키는 작업을 반복해서, 그래디언트가 충분히 작아질 때까지 혹은 일정한 횟수를 반복할때까지 진행합니다.
최소자승법 (OLS) vs 경사하강법 (Gradient Descent)
보통 OLS의 경우 데이터의 크기가 작거나 중간 크기일 때, 특히 행렬 연산이 가능한 경우에 OLS가 효과적입니다. OLS는 분석적 해답을 제공하기 때문에 반복 없이 직접 해를 찾을 수 있습니다. 그러나 데이터의 크기가 매우 클 때나, 공선성과 같은 문제가 있을 경우 민감한 반응을 보일 수 있습니다. 그런 경우 Gradient Descent을 사용할 수 있습니다. Gradient Descent는 대량의 데이터나 실시간으로 데이터가 업데이트 되는 상황, 또는 OLS의 분석적 해가 계산하기 어려운 경우에 사용됩니다. 경사 하강법은 반복적인 방법을 사용하여 손실 함수를 최소화하므로, 매우 큰 데이터셋에서도 확장성 있게 작동하는 장점이 있습니다.
선형 회귀의 결과 해석
선형 회귀의 해석은 보통 회귀계수와 결정계수를 통해서 이루어집니다. 먼저, 아래와 같은 예시 데이터에 대해 선형 회귀 모델을 만들면 위의 식을 만들 수 있습니다.
import pandas as pd
data = {'집_크기': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
'집_가격': [3.5, 6.8, 10.1, 13.5, 16.8, 20.2, 23.7, 27.1, 30.5, 33.9]}
data = pd.DataFrame(data)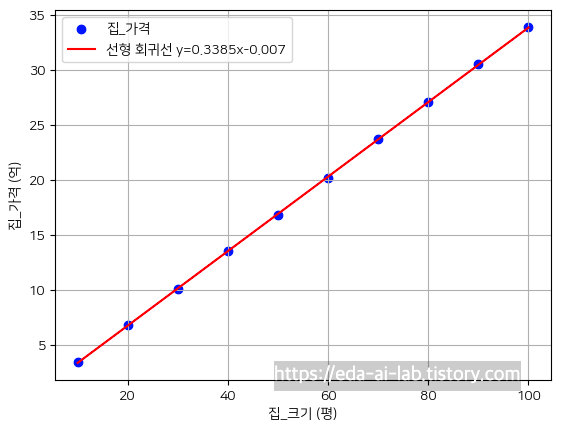
from statsmodels.formula.api import ols
model = ols('집_가격 ~ 집_크기', data=data).fit()
model.summary()
이때, 모델의 해석은 x라는 집_크기가 1씩 상승할때마다 집_가격은 0.3385 (회귀계수)만큼 상승한다는 의미입니다. 참고로, P>|t|의 부분이 p-value를 의미하고 해당 값이 0에 가까울 수록 해당 값이 의미가 있습니다. 그리고, 이때 결정계수(R-squared)는 회귀 모형 내에서 독립변수들(X)이 설명할 수 있는 종속변수(Y)의 변동성을 의미하며, 회귀 모델이 얼마나 얼마나 데이터에 적합한지를 의미합니다. 이러한 결정계수는 아래와 같이 계산할 수 있습니다.

1. SST (Total Sum of Squares): 독립 변수의 변동성을 측정합니다.

2. SSR (Regression Sum of Squares): 회귀선이 데이터의 중심(평균) 대신 데이터 포인트를 지나갈 때 설명된 변동입니다.

3. SSE (Error Sum of Squares): 예측값과 실제 값 간의 차이(잔차)로 인한 변동입니다.

결정계수의 값은 0에서 1사이이며, 값이 1에 가까울수록 모델이 데이터를 잘 설명하고 있음을 의미합니다. 반면, 결정계수의 값이 0에 가까우면, 모델이 데이터를 잘 설명하지 못하고 있다는 것을 의미합니다. 위의 예시에서 결정계수는 0.99로 모델이 데이터를 굉장히 잘 설명하고 있다고 볼 수 있습니다. 참고로, 다른 자료나 모델의 결과를 보면 수정된 결정계수를 사용하는 부분이 많습니다. 수정된 결정계수는 회귀 모델의 독립 변수의 수를 고려하여 결정계수를 수정한 값입니다. 기본적인 결정계수는 독립 변수를 추가하면 일반적으로 증가합니다. 즉, 불필요한 변수를 추가하더라도 결정계수의 값이 더 높아질 가능성이 있고 이는 모델이 실제로 더 나아졌다는 의미가 아닙니다.

그렇기에, 위와 같이 변수의 개수 p를 고려해서 결정계수를 표현하기도 합니다.
선형 회귀를 돌릴때 주의해야할 점은 무엇일까요?
하지만, 이런 선형 회귀는 사용할때 주의해야할 점이 있습니다. 첫번째로 이상치에 주의해야합니다. 아래의 그래프는 이상치의 유무에 따른 선형회귀 결과식입니다. 눈에 보이듯이 이상치가 있는 경우 이상치를 모델이 잘 설명하기위해 (패턴을 학습하기 위해) 선이 과도하게 올라가고 모든 데이터 포인트들을 설명하지 못하는 문제가 발생합니다. 반대로, 이상치가 없으면 대체적으로 모든 포인트들을 잘 설명하는 것을 오른쪽 그래프에서 볼 수 있습니다.

그렇기에, [Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (이상치)에서 언급한 방법들로 이상치를 삭제하거나 대체하거나, 변환해야 제대로된 회귀 모형을 얻을 수 있습니다.
두번째로 주의해야할 점은 몇가지 가설을 만족해야 정확한 모델을 학습하고 결과를 해석할 수 있다는 점입니다. 이러한 가정들은 총 4가지가 있습니다.
- 선형성
- 독립성
- 정규성
- 등분산성
1. 선형성
첫번째로 선형성에 대한 가정입니다. 선형 회귀 모델은 x와 y의 관계를 선형적인 관계를 모델링 하는 것이기에 해당 조건이 반드시 만족해야합니다.

이러한 가설은 보통 시각화를 통해서 확인을 합니다. 하지만 실제 데이터는 이렇게 선형이 아닐 수 있습니다.

예를들어, 위의 왼쪽 그래프처럼 x와 y의 관계가 선형이 아닌 지수형태의 느낌처럼 상승하는 그림입니다. 이러한 경우 관계를 잘 파악해서 로그 변환, 제곱근 변환 등을 통해 비선형성을 줄이거나 해당 변수를 제거하는 방법이 존재합니다.
2. 독립성
독립 변수들 간에 상관관계가 존재하지 않는다고 가정합니다. 상관관계 (Correlation)는 변수들간에 얼마나 관계가 있는지 판단하는 값으로 X, Y가 있을때 둘이 얼마나 같이 상승하는지 같이 하락하는지를 통해서 얼마나 상관있는지를 측정하는 지표입니다.

다중 공선성은 독립 변수들 간에 상관관계가 강한 경우를 의미합니다. 이게 문제가 되는 이유는 회귀 계수의 해석이나 일부 독립 변수의 영향을 제대로 파악하기 어렵기 때문입니다. 한번 예시를 통해서 해당 가설이 끼치는 영향에 대해 살펴보겠습니다. 먼저, 아래와 같은 예시가 있다고 생각해보겠습니다.
# Sample data
data = {'집_크기': [120, 150, 180, 200, 220],
'방_개수': [3, 4, 5, 6, 7],
'집_가격': [200, 250, 280, 300, 320]}
data = pd.DataFrame(data)
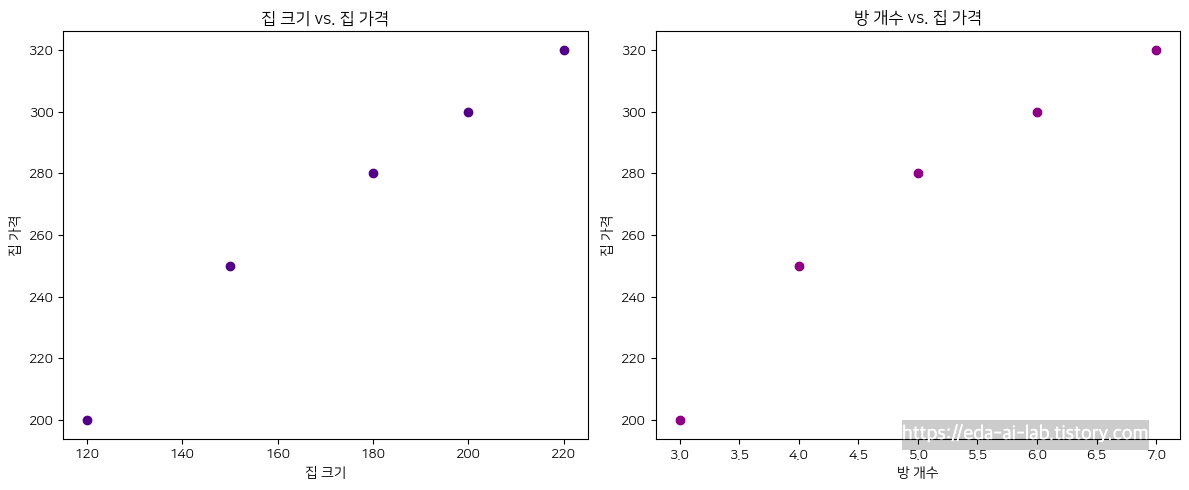
위의 예시만 보면 집 크기와 집 가격 사이에는 선형성이 있고, 방 개수와 집 가격 사이에도 선형성이 있습니다. (당연하지만 집 크기와 방 개수가 크면 클수록 가격도 늘어날 것입니다.) 실제 상관관계를 그려봐도 0.99로 매우 높습니다.
data.corr()
하지만, 이를 가지고 Python코드를 통해 선형 모델을 만들어보면 아래와 같은 모델이 만들어집니다.

집 가격 = 2.14 * 집 크기 -24.57 * 방개수 + 20
방개수가 많아질수록 집의 가격은 떨어진다는 결론이 나오게 됩니다. 이는 방 개수와 집 크기간의 강력한 상관성이 있기 때문에 발생한 현상입니다. 집이 크면 클수록 보통 방이 더 들어올 수 있으니깐 둘을 상관있을 수 밖에 없습니다. 그렇기에, 모델의 설명력관점에서 다중 공선성을 없애는 것은 중요하며 보통은 아래의 과정을 통해 다중 공선성을 파악하고 해결을 시도합니다.
1. 상관 관계 분석 혹은 VIF(분산 팽창 요인)을 확인하여 다중 공선성의 문제를 확인
2. 변수 제거/결합, PCA 등
VIF는 다중공선성을 확인해주는 척도 중에 하나로 1 / (1-R^2)으로 계산할 수 있으며 보통 10이 넘으면 문제가 있다라고 얘기합니다.
from patsy import dmatrices
y, X = dmatrices('집_가격 ~ 집_크기 + 방_개수', data, return_type = 'dataframe')
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
vif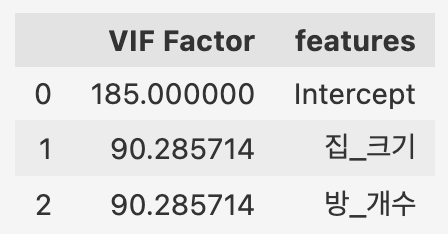
실제 집_크기, 방_개수 모두 VIF값이 높으며 이중 하나를 제거하거나 다른 방안을 생각해야합니다. 실제, 방_개수를 제거하고 집_크기만으로 선형 모델을 만들면 아래와 같이 깔끔한 식이 만들어지긴합니다.

3. 정규성 가설
정규성 가설은 선형 회귀 분석에서 오차(잔차)의 분포가 평균이 0인 정규분포를 따른다는 가정입니다. 정규성 가설이 만족된다면, 회귀 분석 결과의 신뢰성을 높일 수 있습니다. 만약, 정규성 가설이 어긋나는 경우 아래와 같은 문제가 발생할 수 있습니다.
신뢰 구간 및 가설 검정의 부정확성: 잔차가 정규분포를 따르지 않을 경우, 회귀 모델의 계수들에 대한 신뢰 구간과 가설 검정 결과가 부정확해지고 이로 인해 잘못된 해석이 이루어질 수 있습니다.
예측의 부정확성: 잔차의 분포가 비정규적일 경우, 새로운 데이터에 대한 예측의 정확성이 떨어질 수 있습니다. 이는 모델의 예측 능력을 저하시킬 수 있습니다.
그렇기에, 보통은 잔차가 정규성 가설을 만족하는지 Shapiro-Wilk Test 혹은 Q-Q (quantile-quantile) 그래프을 통해 확인합니다. 해당 그래프는 잔차를 오름차순으로 나열 했을때의 분위수와 이론적인 잔차의 분위수 값을 비교해서 정규성을 확인합니다. 아래의 그래프에서는 파란색 점이 빨간색 선에 멀어질 수록 정규성이 떨어진다고 판단할 수 있습니다.
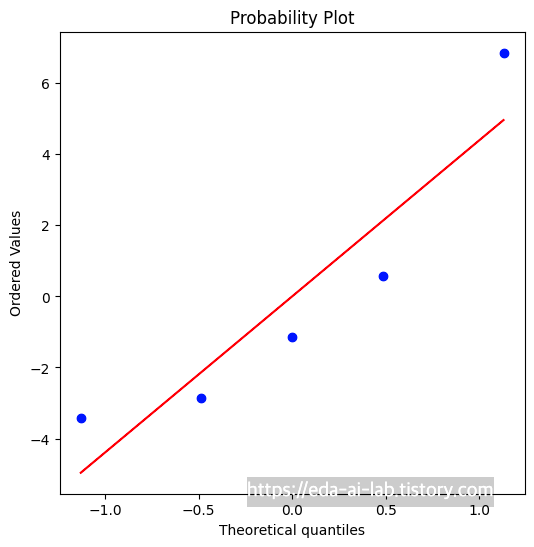
만약, 정규성 가정이 어긋날 경우 로그나 루트를 취하거나 더 많은 데이터 수집 (데이터의 크기가 충분하다면 중심극한정리에 의해 잔차의 분포가 정규분포에 가까워질 수 있습니다.) 등의 방법을 생각해볼 수 있습니다.
4. 등분산성
등분산성, 또는 동분산성이라 불리는 이 가설은 선형 회귀 분석에서 모든 예측값에 대한 오차(잔차)의 분산이 동일하다는 가정입니다. 이러한 등분산성은 잔차와 예측값의 산점도를 그려서 확인할 수 있습니다. 잔차가 예측값에 따라 패턴을 보이거나 분산이 일정하지 않으면 등분산성 가정이 어긋나는 것으로 판단할 수 있습니다.

실제 3번째 그림처럼 잔차의 분산이 일정해야하는데 1, 2번 처럼 잔차의 분산이 일정하지 않은 경우 등분산성 가정이 어긋난 것입니다. 이런 경우, 로그나 루트를 취하거나 제곱항등을 추가하는 방식으로 해결을 시도해볼 수 있습니다.
요약해서 한 페이지로 위의 가정들을 살펴보면 아래와 같습니다.

선형 회귀의 장점과 단점
장점
1. 학습 및 예측 속도가 빠른편
2. 모델의 해석력이 뛰어남
3. 베이스라인으로 삼기 좋은 모델
단점
1. 여러가지 가정을 만족해야하기에, 쉽게 사용하기 어려움
2. 이상치에 민감한 모습을 보임
선형 회귀의 확장한 모델에는 무엇이 있을까요?
그 외에도 선형 회귀를 수행하는 모델들은 많습니다. 대표적으로 Ridge, Lasso부터 시작해서 아래의 NC Soft 기술블로그 글에 따르면 엄청나게 많은 형태의 회귀 모델들이 존재합니다.

대표적인 케이스인 Ridge, Lasso, ElasticNet 에 대해 살펴보겠습니다. 해당 모델들은 회귀 계수에 규제(regularization)를 추가한 모델입니다. 선형 회귀 모델에서 변수가 많거나 다중공선성(multicollinearity) 문제가 존재할 경우 훈련 데이터에 지나치게 최적화되는 과적합(Overfitting)문제가 발생할 수 있습니다. 이를 해결하기 위한 방법이 Ridge, Lasso, ElasticNet인데 해당 방법들은 간단합니다.

3가지 방법 모두 회귀 계수의 크기를 로스에 추가하는 방식입니다. 다만, Lasso는 절대값을 통해서 Ridge는 제곱을 통해서 ElasticNet은 둘을 모두 활용하는게 차이입니다.

이게 어떤 의미인지는 위의 그림에서 잘 설명되어 있는데, L1 (Lasso)와 같은 경우는 의미없는 가중치를 아예 0으로 보내는 식으로 규제를 합니다. 반면, L2의 경우는 값은 살리는 형태로 규제를 하게됩니다. (Elastic Net은 그 중간이라고 보면 될 것 같습니다). Ridge 회귀는 모든 특성을 유지하면서도 계수의 크기를 줄이려고 하기에 데이터에 노이즈가 있을 때 특히 유용합니다. 반대로, Lasso 회귀는 일부 특성의 계수를 완전히 0으로 만들어버립니다. 이렇게 되면 일종의 변수 선택 기능을 수행하게 되어 불필요한 특성을 아예 제거하게 됩니다.
[추가해야할 부분]
1. 독립성 vs 다중 공선성(비상관성) 뭐가 맞는 표현인지 체크
[참고자료]
https://aws.amazon.com/ko/what-is/linear-regression/
https://danbi-ncsoft.github.io/study/2018/05/04/study-regression_model_summary.html
https://heung-bae-lee.github.io/2020/01/15/machine_learning_04/
http://www.datamarket.kr/xe/index.php?mid=board_mXVL91&document_srl=7144&listStyle=viewer
'EDA Study > Machine Learning Advanced' 카테고리의 다른 글
| [Machine Learning Advanced] 3강. 머신러닝 강의 - 파생 변수 만들기 (4) | 2023.08.14 |
|---|---|
| [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (의사결정 나무) (5) | 2023.08.12 |
| [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (개요) (1) | 2023.08.09 |
| [Machine Learning Advanced] 7강. 머신러닝 강의 - 데이터 셋 분할 (1) | 2023.08.08 |
| [Machine Learning Advanced] 6강. 머신러닝 강의 - 변수 선택 (4) | 2023.08.07 |



