
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 3줄 논문
- 파이썬
- 스택
- Semantic Segmentation
- MySQL
- Python
- Recsys-KR
- TEAM EDA
- Object Detection
- 나는리뷰어다
- TEAM-EDA
- 큐
- 협업필터링
- 한빛미디어
- 입문
- 프로그래머스
- 나는 리뷰어다
- Image Segmentation
- 코딩테스트
- hackerrank
- pytorch
- Machine Learning Advanced
- 알고리즘
- 엘리스
- DilatedNet
- DFS
- 튜토리얼
- 추천시스템
- Segmentation
- eda
- Today
- Total
TEAM EDA
[파이토치로 시작하는 딥러닝 기초] 4.2 RNN Advanced 본문
이번 글에서는 기존의 RNN Basics에 이어서 PyTorch로 RNN를 구현하는 것에 대해서 심화적으로 배워보도록 하겠습니다. 이번 글은 EDWITH에서 진행하는 파이토치로 시작하는 딥러닝 기초를 토대로 하였고 같이 스터디하는 팀원분들의 자료를 바탕으로 작성하였습니다. Cross entropy loss에 대한 이론적인 설명은 hyuwk님의 블로그와 ratsgo님의 블로그를 참고하였습니다.
목차
- 'Hihello' problem
- Data Setting
- one hot encoding
- Cross entropy loss
- Code run
- 'longseq' example
- RNN timeseries
'Hihello' problem
- 문제 : hihello라는 문자열을 예측하는 모델을 만드는 것
- 목적 : 다음에 오는 character를 예측해야 함 (h가 들어오면 i, i가 들어오면 h를 예측해야 함)
How can we represent Characters?
- 문제 : Chracters를 컴퓨터에서 표현하는 방식
- 이를 컴퓨터가 인식하는 방법을 Embedding이라 하고 대표적으로는 One-hot Encoding이 있다.
- 그 외에는 LSA, Word2Vec, GloVe, FastText이 있다.
- 참고
- LSA(Latent Semantic Analysis) : DTM(문서 - 단어 행렬)에 SVD를 적용해서 단어의 의미를 고려해주는 기법
- Word2Vec : 주변단어를 통해서 단어의 의미를 파악하는 기법
- Glove : LSA와 Word2Vec의 단점을 개선한 기법. (임베딩된 두 단어벡터의 내적이 말뭉치 전체에서의 동시 등장확률 로그값이 되도록 목적함수를 정의)
- FastText : 페이스북에서 개발한 모델로 Word2vec에 기반을 두고 부분 단어들을 Embedding하는 기법. 속도가 매우 빠름
- Embedding 기법에 대한 자세한 내용은 임베딩 기법(Embedding)을 참고하시기 바랍니다.


- 각 단어에 index를 부여하는 방식
- h의 경우 [1, 0, 0, 0, 0] 으로 자기 index의 값만 1을 가지는 방식
Cross Entropy Loss
- Categorical Output을 예측하는데 사용하는 loss
cirterion = torch.nn.CrossEntropyLoss()
criterion(모델의 Output, 실제 값) 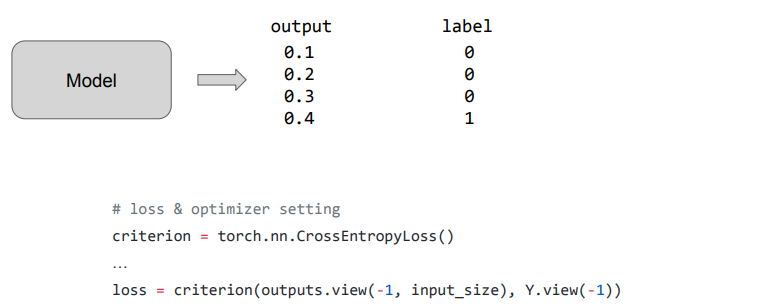
Code Run
- hidden_size는 임의로 설정
- torch.FloatTensor로 one_hot vector를 Floattensor형태로 변환

- 이전과 다르게 dictionary형태로 저장
- hidden_size는 임의로 설정
- torch.FloatTensor로 one_hot vector를 Floattensor형태로 변환
- np.eye : 대각성분은 '1'이고 나머지 성분은 '0'으로 구성된 정방행렬인 항등행렬(identity matrix) 혹은 단위행렬(unit matrix)을 만듬


'longseq' example
- 목적 : longer dataset을 사용
- 문제 : bigger chunks에서 학습을 해야함, 아주 긴 문장을 어떻게 input으로 사용할 지
sentence = "if you want to build a ship, don't drum up people together to collect wood and don't assign them tasks and work, but rather teach them to long for the endless immensity of the sea."


모델을 좀 더 크게 만들고 싶을 때, FC layer과 stacking RNN을 더 할 수 있음
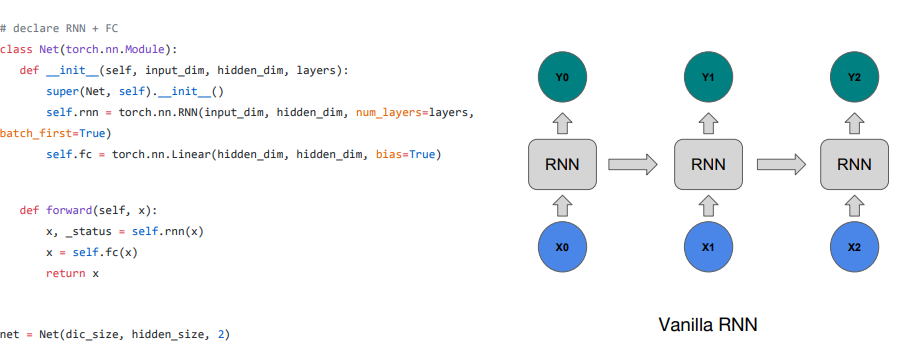
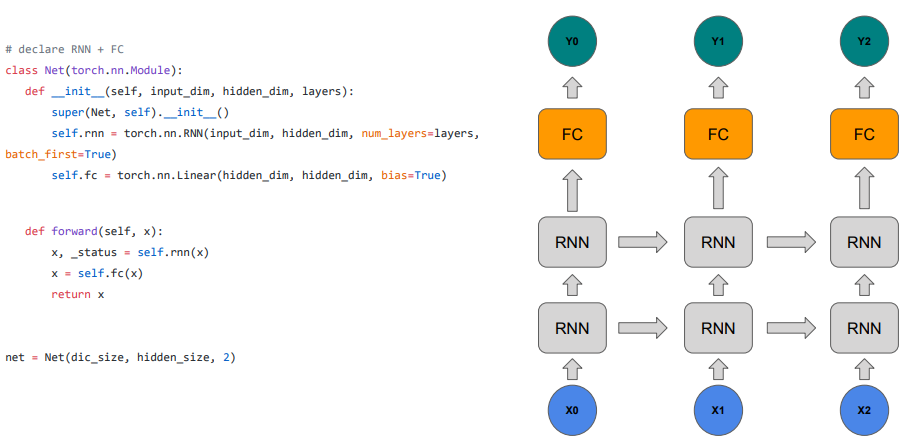
- num_layers가 2이기에 torch.nn.RNN이 2개의 층을 가지는 구조가 됨
- RNN 2개의 층을 지나고 FC를 거치면서 학습이 종료

'TimeSeries' example
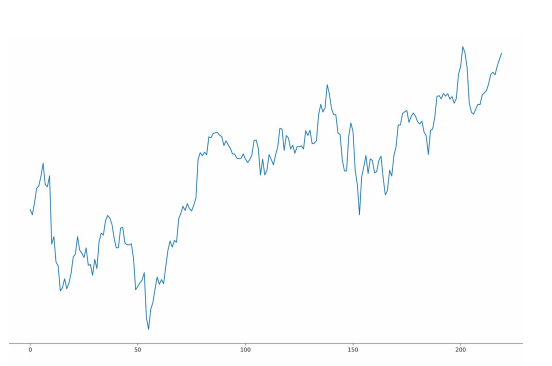
대표적인 시계열 데이터로는 주가데이터가 있습니다. 아래의 모습은 8일차의 주가를 예측하기 위해서 이전 7일간의 데이터를 보는 모델입니다. 비록 주가는 코스피, 경제, 호재 등 예상치 못한 변수들이 많이 숨어있습니다. 그렇기에 정확한 주가는 예측할 수 없지만, 기본적인 모델을 만들어보도록 하겠습니다.

위의 모델은 5개의 인풋이 들어오면, 이를 처리한 다음에 하나의 정보로 압축(예측해야 하는 값 - 예: 다음날의 종가)시켜서 다음의 hidden state에 넘겨주게 됩니다. 하지만 이러한 방식은 모델에 굉장히 부담스럽게 됩니다. 5개의 정보를 처리하는 것도 부담스럽지만, 하나의 정보로 압축시키는 것도 힘들기 때문입니다. 그렇기에 마지막에 FC을 연결해서 Fully Connected Layer가 종가를 예측하도록 설계하는 것이 일반적입니다. 이렇게 하면 데이터를 유통하는 부분과 레이블을 맞추는 부분을 나눠서 특정 네트워크에 가해지는 부담을 분산시키는 장점이 있습니다.



데이터를 다시보면, Volume과 다른 값들간의 차이가 큰 것을 볼 수 있습니다. 이러한 경우 모델은 둘의 스케일의 차이 또한 인식해줘야 하는데, 이러한 부담을 줄이기 위해서 모든 변수를 0~1로 스케일함으로써 모델에 가해지는 부담을 줄일 수 있습니다.


모델을 보면, 굉장히 잘 예측이 된 것 처럼 보입니다. 하지만, 이 모델을 가지고 주식시장에 뛰어 들면 패가망신할 가능성이 99%이상입니다. 그 이유는 주식시장에는 변동을 끼치는 요소가 많아서 위의 5가지 변수만을 가지고는 불가능합니다. 그리고 위의 값을 잘 보면, 예측값과 실제값이 모양은 같지만 original값이 조금 왼쪽에 있는 것을 볼 수 있습니다. 즉, 예측값은 전 날의 값을 예측한 것이지 당일의 값을 예측했다고 보기에는 무리가 있습니다.
'EDA Study > PyTorch' 카테고리의 다른 글
| [파이토치로 시작하는 딥러닝 기초] 4.1 RNN Basics (0) | 2020.03.26 |
|---|---|
| [파이토치로 시작하는 딥러닝 기초] 3.2 Advance CNN(VGG) (0) | 2020.03.21 |
| [파이토치로 시작하는 딥러닝 기초] 3.1 Convolution Neural Network (0) | 2020.03.21 |
| [파이토치로 시작하는 딥러닝 기초] 2.6 Batch Normalization (0) | 2020.03.20 |
| [파이토치로 시작하는 딥러닝 기초] 2.5 Dropout (0) | 2020.03.20 |



