
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- hackerrank
- 엘리스
- 나는 리뷰어다
- 협업필터링
- Object Detection
- Semantic Segmentation
- Python
- DFS
- eda
- Image Segmentation
- 나는리뷰어다
- 프로그래머스
- 튜토리얼
- DilatedNet
- TEAM-EDA
- 큐
- 스택
- TEAM EDA
- 한빛미디어
- 입문
- Machine Learning Advanced
- Segmentation
- 3줄 논문
- 파이썬
- pytorch
- 알고리즘
- MySQL
- Recsys-KR
- 코딩테스트
- 추천시스템
- Today
- Total
TEAM EDA
[파이토치로 시작하는 딥러닝 기초] 4.1 RNN Basics 본문
이번 글에서는 PyTorch로 RNN를 구현하는 것에 대해서 배워보도록 하겠습니다. 이번 글은 EDWITH에서 진행하는 파이토치로 시작하는 딥러닝 기초를 토대로 하였고 같이 스터디하는 팀원분들의 자료를 바탕으로 작성하였습니다. RNN에 대한 이론적인 설명은 밑바닥 부터 시작하는 딥러닝2와 김성훈 교수님의 모두를 위한 딥러닝 강의, ratsgo님의 블로그를 참고하였습니다.
목차
- RNN
- Usages of RNN
- RNN in PyTorch
- Simple Example
RNN
RNN은 Sequential data를 잘 다루기 위해 도입되었습니다. Sequential data는 순서가 중요한 데이터로 시계열 데이터(Time series), 문장(sentence)와 같은 예가 있습니다. 예) H -> E -> L -> L -> O처럼 HELLO라는 단어를 구성하는 순서가 중요한 경우

RNN의 구성은 위와 같습니다. 이전의 Hidden state의 가중치가 다음 Hidden state의 입력값으로 들어오는 형태입니다. 이러한 구조로 인해서 이전의 입력값을 반영(순서를 기억)하게 됩니다. RNN의 A는 모든 parameter을 공유합니다. 그렇기에 엄청나게 긴 단어가 들어와도 Cell A에 들어가는 파라미터만 알고 있으면 다음 단어를 예측할 수 있습니다.
Cell A는 기본적으로는 함수연산입니다. 이전 단계의 출력 값과 지금 단계의 입력값으로 구성됩니다. 즉, $h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t + b_h)$ 입니다.
Usages of RNN

- one to many : 입력값은 하나고 출력은 여러 개 (예 : 하나의 입력 이미지에 문장이 나오는 경우, 자막 같은 경우)
- many to one : 여러 개의 단어들이 입력(문장)되면 하나의 출력이 나옴 (예 : 감정에 대한 라벨)
- many to many (1) : 입력값과 출력 값이 있지만 사용하지 않아서 공백으로 처리 (예: 번역, 한 문장이 다 들어오면 그 이후에 영어로 번역을 진행함)
- many to many (2) : 입력이 들어갈 때마다 출력 값이 나오는 경우
RNN in PyTorch

파이토치에서는 torch.nn.RNN이라는 명령어를 통해 RNN을 구현할 수 있고 사용자는 input_size와 hidden_size만 지정해주면 됩니다.
rnn = torch.nn.RNN(input_size, hidden_size)
outputs, _status = rnn(input_data)Simple Example
예시 : Hell가 들어가면 다음 알파벳 o를 맞추기


- input_size : 4 (h의 차원의 크기 : [1, 0, 0, 0] )
- hidden_size : 2 (특별한 이유는 없지만, 슬픔, 기쁨, 분노 중 하나를 추론한다면 3으로 둘 수 있음)
- hidden_size의 크기가 outputs의 마지막 shape가 됨
- 이유는 아래의 첨부한 사진과 같음. hidden_state의 출력이 하나는 output으로 하고 다른 하나는 다음번 hidden_state로 가기에 둘은 같은 값을 가지게 됨


- sequence length : 0부터 t까지의 길이를 가지는 입력값
- 예) h, e, l, l, o의 경우 sequence length는 5
- output의 중간 shape가 sequence length가 됨(이건 모델이 알아서 인식함)

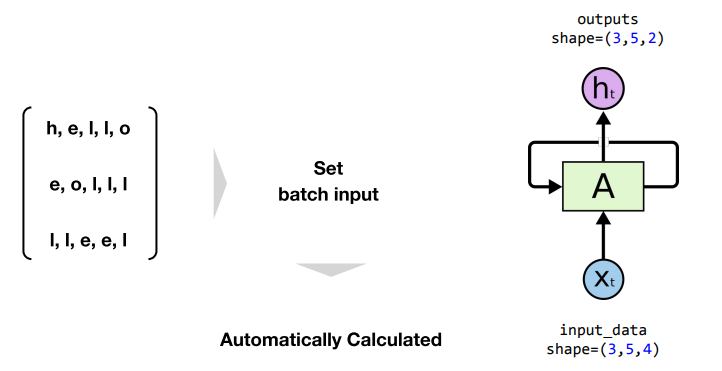
- batch size 역시 모델에 입력할 필요가 없이 input data만 잘 구성하면 알아서 인식됨
import torch
import numpy as np
input_size = 4
hidden_size = 2
# 1-hot encoding
h = [1, 0, 0, 0]
e = [0, 1, 0, 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]
input_data_np = np.array([[h, e, l, l, o],
[e, o, l, l, l],
[l, l, e, e, l]], dtype=np.float32)
# transform as torch tensor
input_data = torch.Tensor(input_data_np)
rnn = torch.nn.RNN(input_size, hidden_size)
outputs, _status = rnn(input_data)'EDA Study > PyTorch' 카테고리의 다른 글
| [파이토치로 시작하는 딥러닝 기초] 4.2 RNN Advanced (2) | 2020.03.28 |
|---|---|
| [파이토치로 시작하는 딥러닝 기초] 3.2 Advance CNN(VGG) (0) | 2020.03.21 |
| [파이토치로 시작하는 딥러닝 기초] 3.1 Convolution Neural Network (0) | 2020.03.21 |
| [파이토치로 시작하는 딥러닝 기초] 2.6 Batch Normalization (0) | 2020.03.20 |
| [파이토치로 시작하는 딥러닝 기초] 2.5 Dropout (0) | 2020.03.20 |



