
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 한빛미디어
- 스택
- Image Segmentation
- TEAM EDA
- Recsys-KR
- 프로그래머스
- eda
- Semantic Segmentation
- 나는 리뷰어다
- pytorch
- 추천시스템
- MySQL
- TEAM-EDA
- 튜토리얼
- DFS
- hackerrank
- 3줄 논문
- 나는리뷰어다
- 큐
- Python
- 코딩테스트
- Machine Learning Advanced
- 협업필터링
- 입문
- 엘리스
- Object Detection
- 파이썬
- DilatedNet
- Segmentation
- 알고리즘
- Today
- Total
TEAM EDA
Convolutional Neural Network (AlexNet) 본문
Note : 본 자료는 edwith 최성준강사님의 논문으로 짚어보는 딥러닝 맥을 정리한 자료입니다.
CNN의 구조

CNN의 구조는 위의 사진과 같습니다. Input이라는 이미지가 들어오면 Convolutions작업을 통해서 feature maps를 만들어 내고 Subsampling을 통해서 그 사이즈를 줄입니다. 마찬가지로 Convolutions - Subsampling 작업을 반복하다가 마지막에 Full Connection이라는 작업을 통해서 Output(Fully Connected layer)을 산출합니다.

위의 과정을 더 자세하게 설명 하겠습니다. 우리는 사진이 들어오면 Output으로 이 사진이 무슨 사물을 가르키는지를 알아보는 Neural Network를 만들것입니다. 먼저 Image로 보트사진이 들어왔습니다. 이러한 사진을 구분하기 위해 보트가 가지는 특징을 추출(Feature extraction) 해보려고 합니다. 그러한 과정이 Convolution입니다. Convolutions는 filter라는 도구를 이용하여서 특징을 추출하고 그 결과물로 feature maps를 만듭니다.
위의 과정에서는 3개의 filter를 통해서 feature maps를 만든 것 입니다. 그리고 Pooling이라는 Subsampling작업을 통해서 사이즈를 줄인 후 위의 과정을 반복한 것입니다. convolutions와 subsampling을 통해서 feature extraction을 하고 마지막으로 Fully Connected layer는 위 사진이 dog인지 cat인지 boat인지 bird인지의 확률을 추출해냅니다.
cnn이 잘 되는 이유?
1. Local Invariance : 국소적으로 비슷하다. convolution filter가 전체이미지를 돌아다니기 때문에, 우리가 찾고자 하는 물체(보트)가 어디에 있는지는 알지 못하지만 물체의 정보를 잘 포함하고 있다.
2. Compositionality : 앞에서 봤던 구조를 의미하는데, 반복적으로 계층구조를 쌓는것을 의미합니다.
convolution 이란?
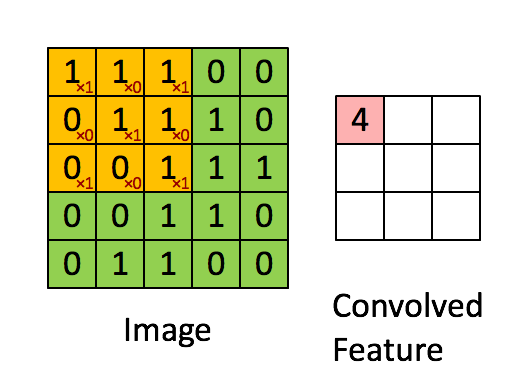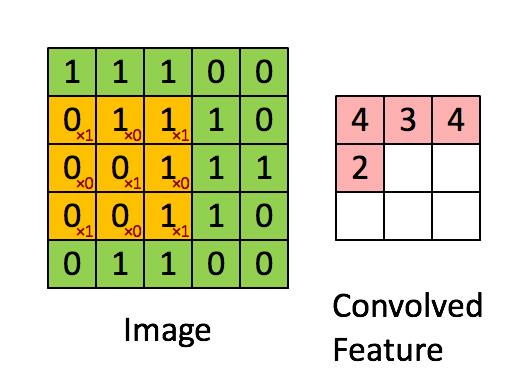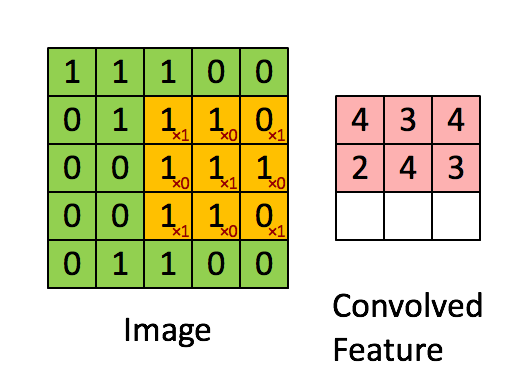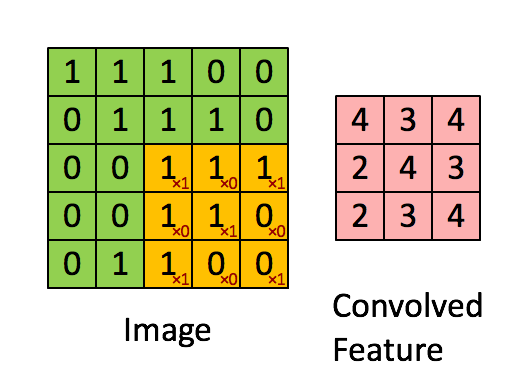
위에서 convolutions는 filter라는 도구를 이용해서 특징을 추출하는 과정이라고 말했습니다. 여기서 filter는 왼쪽 그림에서 노란 3x3의 행렬을 의미합니다. filter는 대각선으로 1의 값을 가지고 (왼쪽 아래 빨간색 글씨) 차례대로 처음부터 끝까지 진행합니다. 그러면서 Convolved Feature(Feature map)를 만드는데 이 과정을 우리는 convolution이라고 합니다. 여기서는 한개의 filter만 이용했지만 3x3의 filter를 n개 사용하면 Feature map은 n개 만큼 나오게 됩니다.
zero-padding 이란?

zero-padding 이란 가장자리를 0으로 둘러쌓는것을 의미합니다. 위의 그림에서는 1 2 -1 1 -3 이라는 값 양옆에 0을 적은것을 의미하고, 위의 예시에서는 아래의 표와 같이 가장자리를 0으로 둘러쌓은 것을 의미합니다.

이렇게 되면 장점이 3가지가 있습니다. 1번째로, 가장자리에 있던 정보의 손실이 사라진다는 점입니다. 그 이유는 zero-padding을 하지 않으면 사이즈가 계속 줄어들어서 가장자리의 정보가 줄어드는데 zero-padding을 할 경우 사이즈가 줄어들지 않습니다. 두번째 장점은 위에서 말한 사이즈가 줄어들지 않는다는 점입니다. 이미지의 경우 그 구조자체가 중요할 수가 있는데 구조가 바뀌지 않으니 하나의 장점이 됩니다. 마지막으로는 0이라는 값이 Feature에 반영되어서 overfitting을 방지할 수 있다는 점 입니다.
stride 이란?

stride는 몇칸씩 건너뛰는지를 의미합니다. 왼쪽의 경우 노란색선을 보면 1칸씩 규칙이 반복되고, 오른쪽의 경우 2칸씩 반복되는것을 볼 수 있습니다. 이것을 바로 stride라고 하고 왼쪽은 stride = 1, 오른쪽은 stride = 2라고 표현합니다. stride를 2보다 크게 하는 것은 뒤에서 나올 pooling과 같이 데이터 사이즈를 줄이는것에 있습니다. 위에서 분명 zero-padding의 장점은 사이즈를 줄이지 않는것이라 했는데, 갑자기 사이즈를 줄이는것에 목적이 있다고 말하는 이유는 위의 경우에는 가장자리 정보의 손실이 일어나지만, 아래의 경우는 가장자리 정보의 손실을 없애면서 특징을 추출하는것에 의의가 있습니다. 추가적으로 같은 정보를 여러번 선택하지 않는 부분에서 overfitting의 위험이 떨어지기도 합니다.
Conv2D
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)

위의 convolution과정을 도식화한게 위의 사진과 같습니다. 먼저 주황색의 3x3x3은 filter의 사이즈를 의미하고, 민트색의 4x4x3은 batch size를 의미합니다. filter는 위에서 배웠고, batch가 무엇이냐면 한마디로, 이미지의 묶음이라고 생각하시면 됩니다. 보통 딥러닝 모델을 돌릴때, 속도와 메모리 문제때문에 하나의 이미지 혹은 전체 이미지를 한번에 돌리는것이 아니라 묶음단위로 학습을 시킵니다. 이것은 우리는 batch라고 하고 여기에서는 4x4x3의 묶음으로 돌렸다고 생각하시면 됩니다. 여기서는 이미지가 한장이기 때문에 batch = 1이라고 가정합시다. 그런데 위의 글씨를 잘 보면 channel이라는 용어가 나오는데 이것은 RGB의 색을 가진 이미지여서 3이라고 생각하시면 됩니다. 다시 정리하면, 3x3x3의 filter로 4x4x3의 batch를 convolution해서 출력값이 4x4x7이 나옵니다. 여기서 7는 filter의 갯수를 의미합니다.
참고로 parameter의 수는 3x3x3x7로 189입니다.
CNN 구조#2



출처 : https://www.slideshare.net/agdatalab/deep-learning-convolutional-neural-network
|
Stride size in filter |
Max pooling |
공통점 |
Overfitting을 방지한다. 차원 축소 |
|
차이점 |
모든 정보를 가진 채 정보를 희석. |
불필요한 정보는 버리고 중요한 정보만 선택. (average pooling은 모든 정보를 다 가져갑니다.) |
parameter 수

딥러닝에서는 parameter의 수를 아는것이 중요합니다. 그 이유는 같은 모델이어도 parameter의 수가 적으면서 layer를 많이 쌓는게 모델의 성능이 좋기 때문입니다. 그래서 우리는 직관적으로 파라미터의 수를 알고 줄일 수 있도록 노력해야 합니다.
먼저 첫번째 convolution layer에서의 파라미터의 수는 576+64 입니다. 576는 3x3x1의 filter가 64개가 있다는 의미이고 64는 각각의 filter마다 bias가 존재해서 생긴 파라미터입니다. 그리고 뒤에서 Fully connected 부분에서는 14x14x64 를 10개의 output으로 분류해주는 파라미터가 필요합니다. 그래서 14x14x64x10 이라는 값이 생깁니다.
참고자료
http://aikorea.org/cs231n/convolutional-networks/
https://ratsgo.github.io/deep%20learning/2017/04/22/NNtricks/
https://stackoverflow.com/questions/2480650/role-of-bias-in-neural-networks
https://www.edwith.org/deeplearningchoi/lecture/15293/
ImageNet Classification with Deep Convolutional Neural Networks(2012)https://www.slideshare.net/agdatalab/deep-learning-convolutional-neural-networkhttp://bcho.tistory.com/1149
틀린 부분이나 궁금한 부분은 댓글로 남겨주시기 바랍니다.
'EDA Study > 머신러닝' 카테고리의 다른 글
| Feature selection using target permutation (Null Importance) (0) | 2019.09.11 |
|---|---|
| Attn: Illustrated Attention (0) | 2019.09.11 |
| ADSP 3과목 정리내용 - 5장: 정형 데이터 마이닝 (0) | 2019.03.02 |
| Analysis of Variance (분산 분석) (0) | 2018.12.23 |
| Introductory Guide – Factorization Machines & their application on huge datasets (with codes in Python) (0) | 2018.12.19 |


