
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 입문
- 스택
- TEAM EDA
- Segmentation
- Image Segmentation
- pytorch
- 큐
- Recsys-KR
- Python
- 나는 리뷰어다
- hackerrank
- DFS
- 엘리스
- 프로그래머스
- 추천시스템
- 코딩테스트
- Machine Learning Advanced
- Object Detection
- eda
- 파이썬
- 튜토리얼
- MySQL
- 알고리즘
- 3줄 논문
- 한빛미디어
- 협업필터링
- Semantic Segmentation
- TEAM-EDA
- DilatedNet
- 나는리뷰어다
- Today
- Total
목록전체 글 보기 (287)
TEAM EDA
 Cassava Leaf Disease Classification Public 13, Private 171 Solution
Cassava Leaf Disease Classification Public 13, Private 171 Solution
Cassava Leaf Disease Classification Public 13, Private 171 Solution 이번 포스팅에서는 Pseudo Lab 소속으로 4명의 팀원과 함께 나간 캐글 - Cassava Leaf Disease Classification 대회 솔루션의 후기를 작성하겠습니다. 정리한 내용이 길어서 이번 글에서는 저희 팀의 솔루션을 다음 글에서는 다른 팀의 솔루션과 배운점을 위주로 정리하도록 하겠습니다. 김현우 : https://github.com/choco9966 코드 : https://github.com/choco9966/Cassava-Leaf-Disease-Classification 영상 : https://www.youtube.com/watch?v=ofSsnFcerV4 1...
 NIPA 2021 인공지능 온라인 경진대회, 한국인 헤어스타일 세그멘테이션 2등
NIPA 2021 인공지능 온라인 경진대회, 한국인 헤어스타일 세그멘테이션 2등
NIPA 2021 인공지능 온라인 경진대회, 한국인 헤어스타일 세그멘테이션 2등 이번 포스팅에서는 ARTuna이라는 팀으로 4명의 팀원과 함께 나간 인공지능 온라인 경진대회의 후기를 작성하겠습니다. 김현우 : https://github.com/choco9966 코드 : https://github.com/choco9966/Korean-Hair-Segmentation 저희 팀은 카이스트 산업 및 시스템공학과인 저와 세이지리서치에서 근무하는 하헌진님, 아트랩에서 근무하시는 3분의 팀원 훈재님, 재희님, 대선님 이렇게 5명이 팀을 이루어서 대회를 진행했습니다. 본선 저희 팀이 참여한 대회는 이미지 분야에서도 한국인 헤어스타일 세그멘테이션 대회였습니다. 과학기술정보통신부 - 한국인 헤어스타일 세그멘테이션 모델 (..
쓰레기통 비우는 명령어 rm -rf ~/.local/share/Trash/files/\* # 혹은 경로에 따라서, rm -rf ~/.local/share/Trash/* 사용하지 않는 패키지 제거 sudo apt-get autoremove 캐시 제거 sync && echo 3 > /proc/sys/vm/drop_caches # 위의 코드가 permission error 나는 경우 sudo sh -c "echo 1 > /proc/sys/vm/drop_caches" 사용전 후 비교 df -h /dev/vdb1 2.0T 2.0T 4.7G 100% /home -> /dev/vdb1 2.0T 1.1T 1022G 51% /home
 Object Region Mining with Adversarial Erasing: A Simple Classification toSemantic Segmentation Approach (AE-PSL)
Object Region Mining with Adversarial Erasing: A Simple Classification toSemantic Segmentation Approach (AE-PSL)
Resources Title : Object Region Mining with Adversarial Erasing: A Simple Classification toSemantic Segmentation Approach (AE-PSL) Paper : https://arxiv.org/pdf/1703.08448.pdf Motivation & Introduction 기존 Weakly-Semantic segmentation 에서 pesudo mask를 생성하기위해서 CAM을 많이 사용합니다. 하지만, 이러한 CAM은 Classification Network에 의한 결과로 Object의 일부분만을 바라보는 현상이 있고 이를 바로 pesudo mask로 적용하기에는 무리가 있습니다. 이를 해결하기위해 CAM이 바라보..
 Context Encoding for Semantic Segmentation (EncNet)
Context Encoding for Semantic Segmentation (EncNet)
Resources Title : Dual Attention Network for Scene Segmentation (DANet) Paper : https://arxiv.org/abs/1803.08904 Code :https://github.com/zhanghang1989/PyTorch-Encoding Motivation & Introduction Semantic Segmentation 에서 많은 카테고리가 존재하는 경우에는 정확하게 분류를 하기가 어렵다. 사람도 카테고리가 많으면 분류하기 어려운데, 이를 좀 더 간단하게 하기위해서 상위 카테고리를 기반으로 분류를 진행하면 더 쉽지 않을까하는 동기에서 만들어진 모델이다. 이를 Context Encoding Module 이라고 해서 class-dependen..
 Dual Attention Network for Scene Segmentation (DANet)
Dual Attention Network for Scene Segmentation (DANet)
Resources Title : Dual Attention Network for Scene Segmentation (DANet) Paper : https://arxiv.org/abs/1809.02983 Motivation & Introduction 기존의 연구는 Global한 Context 정보를 잡기위해서 Kernel Size를 넓히거나 Global Average Pooling, Dilated Convolution 등을 이용했다. 하지만, 이는 object와 stuff 사이의 관계를 제대로 파악하지 못한다. 이를 위해, DANet은 2가지의 Self-Attention인 Position Attention과 Channel Attention을 통해서 위의 문제를 해결하려고 한다. Methodology Pos..
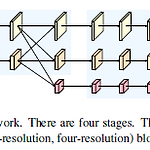 High-Resolution Representations for Labeling Pixels and Regions (HRNetV2)
High-Resolution Representations for Labeling Pixels and Regions (HRNetV2)
Resource Title : High-Resolution Representations for Labeling Pixels and Regions (HRNetV2) Paper : https://arxiv.org/pdf/1904.04514.pdf Motivation & Introduction Vision Task에서 High-Resolution representation learning은 중요한 역할을 한다. 하지만, 기존의 연구들의 대부분은 low-resolution 혹은 medium-resolution으로부터 High-Resolution을 복원하거나 dilated convolution을 통해서 medium-resolution을 계산하는게 전부이다. 비록 이렇게 resolution을 줄여야 receptiv..
 [나는 리뷰어다] 데이터 스토리
[나는 리뷰어다] 데이터 스토리
본 포스터는 한빛미디어에서 [나는 리뷰어다]를 통해 책을 지원받아 작성한 리뷰 포스터입니다. 기존의 많은 책들은 "데이터 분석"에 초점을 맞추었다면 이 책은 "스토리 텔링"에 맞추어져 있습니다. 데이터 분석 공모전을 하면서 항상 느끼는 점은 내가 분석한 내용을 어떻게 설명을 해야할지 였습니다. 같은 데이터를 가지고 분석한 팀원들에게도 내가 한 분석을 설명하기 어려운데 심사위원들에게 이를 어떻게 설명하고 이해시킬지 막막하기만 합니다. 안그래도 최근에 이러한 고민을 많이하게 되었고 7월 리뷰로 해당 책을 선택하게 되었습니다. 초급이라는 난이도 답게 책 자체는 많이 쉬운 편이었습니다. 책의 페이지가 200를 넘어가지만 페이지 내에 글씨 자체가 적은편이라 읽는 시간이 오래 걸리지 않았습니다. 내용 자체도 "직관..
1. 절대경로 찾기 import os os.getcwd() '/home/ubuntu/Upstage AI : 수식인식기' 2. 압축 풀기 from zipfile import ZipFile dataset = ZipFile('/home/ubuntu/Upstage AI : 수식인식기/train_dataset.zip') dataset.extractall('/home/ubuntu/Upstage AI : 수식인식기/') dataset.close() '/home/ubuntu/Upstage AI : 수식인식기/train_daset' 폴더가 생성됨
 [나는 리뷰어다] 스파크를 활용한 실시간 처리
[나는 리뷰어다] 스파크를 활용한 실시간 처리
본 포스터는 한빛미디어에서 [나는 리뷰어다]를 통해 책을 지원받아 작성한 리뷰 포스터입니다. 먼저 저는 대학원생이고 스파크의 경우 아예 처음이었습니다. 1. 소개 Apach Spark는 SQL, 머신러닝 등을 위한 대규모 데이터 처리 분석 엔진입니다. 한마디로 빅데이터를 분석하기 위한 언어입니다. 보통 Hadoop과 스파크 둘 중 하나의 언어를 사용하는데, 구글 클라우드 잼의 글에서는 아래와 같이 비교를 한다고 합니다. Hadoop은 주로 디스크 사용량이 많고 맵리듀스 패러다임을 사용하는 작업에 사용됩니다. Spark는 더 유연하지만 대체로 더 많은 비용이 드는 인메모리 처리 아키텍처입니다. 각 기능을 이해하고 있으면 언제 어떤 것을 구현할지 결정하는 데 도움이 됩니다. 출처 : https://cloud..