
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Python
- MySQL
- 스택
- Semantic Segmentation
- 엘리스
- Segmentation
- 파이썬
- 3줄 논문
- 나는리뷰어다
- TEAM EDA
- 협업필터링
- DFS
- 코딩테스트
- eda
- 나는 리뷰어다
- 한빛미디어
- hackerrank
- 추천시스템
- Machine Learning Advanced
- Object Detection
- DilatedNet
- 입문
- 큐
- TEAM-EDA
- 프로그래머스
- Image Segmentation
- 알고리즘
- 튜토리얼
- Recsys-KR
- pytorch
- Today
- Total
TEAM EDA
[Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (이상치) 본문
[Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (이상치)
김현우 2023. 8. 7. 13:30이전 강의인 [Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (결측치)에 이어서 이상치에 대해서 살펴보도록 하겠습니다.
이상치란 무엇일까요?

이상치(outlier)는 일반적인 데이터 패턴에서 벗어나거나 예외적인 값을 가지는 데이터 포인트를 의미합니다. 이러한 이상치는 주로 측정 오류, 혹은 특이한 상황 등으로 인해 발생하는 값입니다. 이러한 이상치는 통계적 결과를 왜곡 하는 원인이 되기도 하고, 모델의 학습을 방해하는 요소이기도 원인을 파악하고 원인에 따른 처리를 하는게 중요합니다. 예를들어, 위의 그래프처럼 축구선수의 평균연봉은 222000으로 크게 느껴지지만, 메시라는 선수 한명을 제외하면 10배 가까이 확 낮아지는 것을 볼 수 있습니다. 그렇기에, 이런 이상치 하나가 통계적인 결과를 많이 왜곡하는 결과를 가져옵니다.

또한, 예전에 직방X데이터 뽀개기의 발표에서 실거래가 발표에서 흥미로웠던 슬라이드인데, 부동산 거래에도 다양한 이상치가 있다고 합니다.
- 측정 오류 : 사람이 실제 실거래 가격을 기록하기에 실수로 잘못 작성하는 경우
- 특이한 상황 : 업거래, 다운거래 (일종의 편법, 다른 의도로 인한 거래)를 하려고 가격을 한 경우
위의 5개의 케이스 (입력오류, 업거래, 다운거래, 미분양 아파트 일괄매매, 임대 후 분양전환)인데 이상치별로 발생하는 원인이 다릅니다. 이러한 이상치의 발생원인을 아는 것은 이상치별 대처하는 방법이 달라지기에 미리 파악해야합니다.
이상치는 그러면 왜 처리를 해야할까요?
이상치는 전체 데이터의 패턴을 왜곡하거나 분석 결과를 실수로 인해 왜곡시킬 수 있기 때문에 처리해야 합니다. 모델은 이상치로 인해 왜곡된 패턴을 학습하고, 우리는 왜곡된 패턴으로 인한 분석 결과를 통해 의사결정을 할 수도 있습니다. 그렇기에, 이상치를 처리하는 이유는 다음과 같습니다
- 모델의 안정성 향상
- 패턴 탐색 및 인사이트 도출
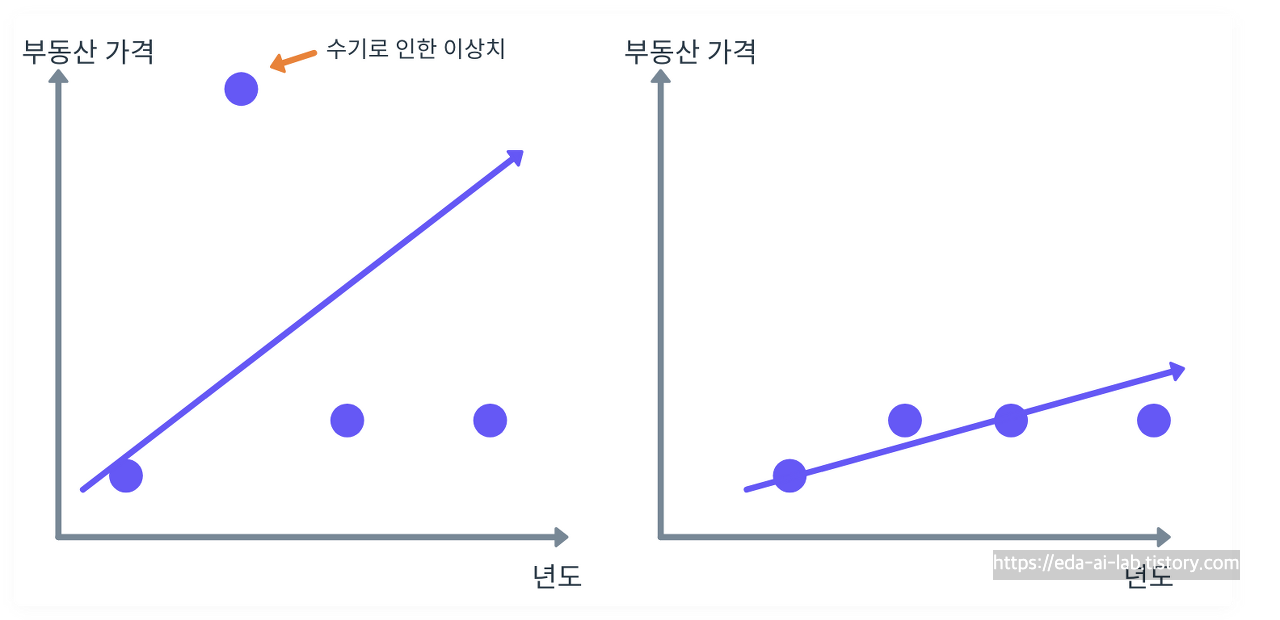
1. 모델의 안정성 향상 : 이상치에 의해 특정 모델의 학습을 방해하거나 예측 결과를 왜곡시킬 수 있습니다. 대표적으로 선형 회귀 모델이나 KNN 같은 경우 이상치의 영향을 받기가 쉽습니다. 해당 모델들이 이상치에 영향을 받는 부분은 [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (선형 모델)와 [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (KNN)의 글에서 참고하시기 바랍니다. 간단하게 아래의 그래프만 봐도 왼쪽의 이상치 하나에 의해 선형회귀선이 많이 달라지는 것을 볼 수 있습니다.
2. 패턴 탐색 및 인사이트 도출 : 이상치를 제거하거나 처리함으로써 데이터셋의 정확한 패턴을 파악하고 유용한 인사이트를 도출할 수 있습니다. 이부분은 2가지 의미로 해석이 됩니다. 모델이 데이터의 패턴을 잘 파악하기도 하고, 모델이 해석한 결론이나 우리가 분석한 부분에 대해 정확한 의사결정이 가능해집니다. 혹은, 이상치를 분석하면서 부동산 이상치 예시에서 본 것처럼 이상치를 분석하면서 원인을 파악하고 이에대해 인사이트를 얻을 수도 있습니다. (예 : 부동산 실거래가에는 여러 종류의 이상치가 발생 - 수기오류의 경우 사람의 실수로 발생하는 부분이 생기니 이걸 자동으로 막아줄 필요! 혹은 업거래나 다운거래등의 부정거래가 실거래가에 녹아드는 문제가 발생 - 이를 자동으로 감지해서 제거해주거나 해당 거래가 나올 경우 신고할 수 있어야함. 미분양 아파트의 일괄매매의 경우 예측도 저 가격으로 할 수 있도록 미분양 아파트라는 피처를 추가 등과 같이 여러 인사이트를 얻고 방안에 대해 고민할 수 있습니다.)
이상치의 종류는 어떤 것이 있을까요?
이상치는 대표적으로 3가지가 있습니다. 점 이상치, 상황적 이상치, 집단적 이상치입니다.
첫째, 점 이상치는 위에서 얘기한 것과 같은 이상치를 의미합니다. 저희가 일반적으로 생각하고 관측하는 이상치입니다.

둘째, 상황적 이상치는 특정 상황에서만 이상치로 간주되는 데이터 포인트를 의미합니다. 동일한 데이터 포인트가 다른 상황에서는 이상치가 아닐 수 있습니다. 예를들어, 아이스크림의 경우 당연하게 여름에 많이 팔리고 겨울에는 적게 팔립니다. 근데 2023.1월처럼 겨울에 많이 팔리는 경우 90만개라는 판매량 자체가 이상한 값은 아니지만, 겨울이라는 상황에서는 이상한 값으로 간주됩니다.
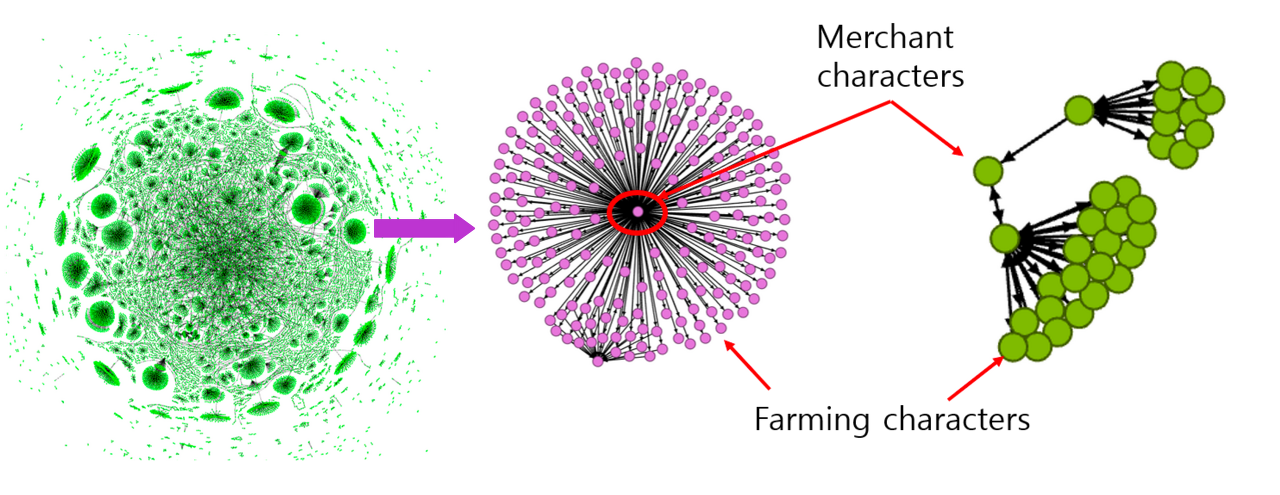
마지막으로, 집단적 이상치가 있습니다. 집단적 이상치는 데이터 분포에서 집단적으로 편차가 이탈되어 이상치로 간주하는 부분으로 관측치 개별로 보았을 때는 이상치처럼 보이지 않지만, 집단으로 봤을때는 이상치처럼 보이는 것이 특징입니다. 대표적인 예시로 게임에서 "작업장 (golf-farming group)" 같은 경우를 생각해볼 수 있습니다. 그래프를 보면 수백개의 캐릭터들이 한개의 캐릭터 (Merchant)를 중심으로 선이 뻗어나가는 것을 볼 수 있습니다. 즉, 전체 유저 중에서 특정한 목적을 가지고 작업장을 운영하는 집단이 일반 유저와 다른 모습을 보이고 이러한 경우를 집단적 이상치라고 합니다.
이상치는 그러면 어떻게 확인하고, 어떻게 처리할 수 있을까요?
이러한 이상치는 위의 그래프(직방X데이터 뽀개기 발표 자료 (by 서범석님))처럼 그려서 확인하는 방법과 통계적인 방법을 통해 확인하는 방법이 있습니다. 통계적인 방법의 대표적인 방법으로는 Z-Score 방식과 IQR 방식이 존재합니다.
1. Z-Score

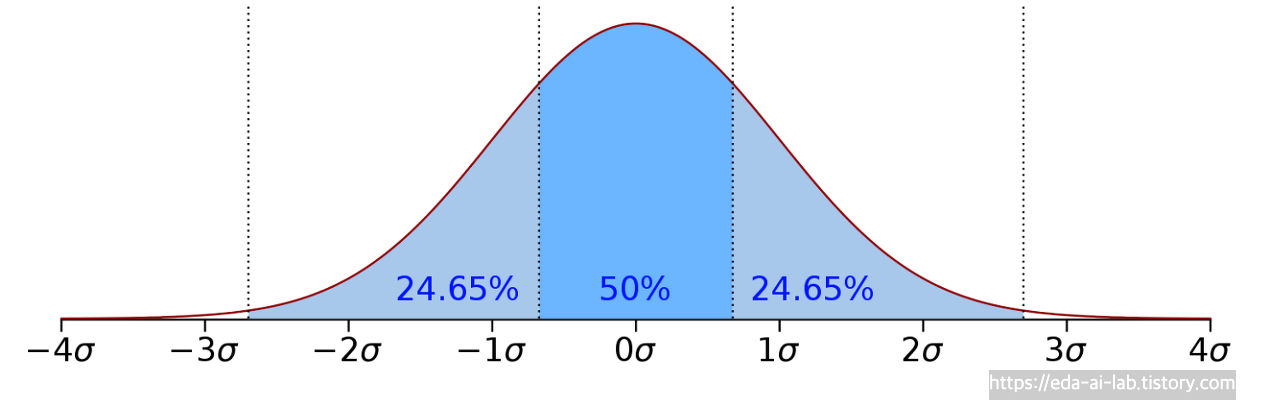
Z-Score는 데이터 포인트가 평균으로부터 얼마나 떨어져 있는지를 나타내는 통계적 척도입니다. 보통 데이터 포인트들이 정규분포를 따른다고 가정하고, 해당 스코어의 임계값을 2나 3으로 설정하여 Z-Score가 해당 임계값을 초과하는 경우를 이상치로 판단합니다.
Z-Score 방식의 장단점
장점: 표준화된 접근 방식으로, 평균과 표준편차를 사용하여 데이터의 상대적 위치를 평가합니다. 이상치의 정도를 수치적으로 평가할 수 있어 데이터셋의 통계적 특성을 고려하면서 이상치를 판단할 수 있습니다.
단점: 데이터가 정규 분포를 따르지 않을 경우, 잘못된 결과를 내릴 수 있습니다. 또한, 데이터 분포의 형태에 따라 임계값을 설정하기 어려울 수 있습니다.
2. IQR (Interquartile Range) 방식

IQR 방식은 데이터의 중간 50% 범위인 IQR을 사용하여 이상치를 판단하는 방법입니다. 데이터의 25번째 백분위수(Q1), 다른 말로는 제 1사분위와 75번째 백분위수(Q3), 제 3사분위를 사용하여 IQR을 계산하고, IQR에 보통 상수 1.5를 곱한 후 Q1보다 작거나 Q3보다 큰 값들을 이상치로 간주합니다.
IQR 방식의 장단점
장점: 데이터의 분포와 중심 경향성을 고려하여 이상치를 판단합니다. 데이터가 정규 분포를 따르지 않아도 상대적으로 강인한 방식입니다. (백분위수를 사용하기에 강인한 모습을 보입니다)
단점: IQR을 상수로 곱하는 상수의 선택에 따라 결과가 달라질 수 있습니다.
Z-Score와 IQR 선택
Z-Score은 정규 분포를 따르는 데이터에 적합하고 IQR은 정규 분포를 따르지 않는 데이터에 더 적합합니다. 그렇기에, 정규분포에 가까울 수록 Z-Score가 그렇지 않을수록 IQR이 더 강인한 모습을 보입니다.
이상치는 어떻게 처리할 수 있을까요?
이상치의 처리 방식은 대표적으로 2가지가 있습니다.
- 삭제
- 변환
- 대체 (통계 값 혹은 모델의 값)
1. 이상치 삭제
결측치에서 본 것 처럼 이상치가 생긴 데이터 포인트 (인스턴스)를 지워버리는 방식입니다. 해당 방식은 데이터가 많은 경우에 삭제해도 영향을 적게 받아서 유용합니다. 다만, 이상치 자체가 위에서 언급한 것 처럼 유용한 정보를 가지고 있을 수도 있으니 삭제하는 경우에는 반드시 주의해야합니다. (입력오류같이 지워도 무방한 이상치를 지우는게 가장 좋습니다)
2. 이상치 변환
삭제가 아닌 변환을 사용할 수도 있습니다. 예를 들어, 로그 변환 등을 생각해볼 수 있습니다.

로그 변환의 경우 큰 값은 더 작게, 작은 값은 조금 작게 바꾸는 효과가 있습니다. 그렇기에, 만일 이상치가 크게 생기는 경우 그 값을 작게만들어서 y = x 일때의 차이보다 y = log1p(x) 일때 차이가 적어져서 이상치의 효과가 작아지는 효과가 있습니다. (이상치가 많은 경우에 이런 방법을 적용하면 효과가 있고, 경험상 Transformer을 사용할때 가격같은 변수에 대해 이러한 방법을 많이 적용합니다. 이상치의 대체 목적도 있지만 가격이 변화 차이가 작은 폭에서 변화가 큰 폭에서의 변화보다 크게 느껴지게에 그런 효과를 반영해주기 위함도 있습니다.)
3. 이상치 대체
마지막으로, 이상치를 대체할 수도 있습니다. 이때, 통계치를 이용해서 평균, 중앙값 등의 값을 이용해서 대체하기도 하고 KNN 혹은 위의 부동산 주가 예측 상황에서는 시계열 모델등을 이용해서 대체하는 방법도 있습니다. 혹은, 비지도 학습 방법 K-means, Isolation Forest, OneClass SVM, ElliticEnvelope 등의 방법을 사용하기도 합니다.

추후, 모델을 활용한 이상치 제거 방법 (KNN, 시계열) 등에 대해 글 하나 작성하기
여기까지 해서 데이터에 이상치가 있는 경우 어떻게 처리할 지에 대해 알아봤습니다. 다음 강의에서는 데이터의 카테고리 변수에 대해 인코딩하는 방법에 대해 알아보도록 하겠습니다.
'EDA Study > Machine Learning Advanced' 카테고리의 다른 글
| [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (선형 모델) (1) | 2023.08.11 |
|---|---|
| [Machine Learning Advanced] 5강. 머신러닝 강의 - 기본 ML 모델 (개요) (1) | 2023.08.09 |
| [Machine Learning Advanced] 7강. 머신러닝 강의 - 데이터 셋 분할 (1) | 2023.08.08 |
| [Machine Learning Advanced] 6강. 머신러닝 강의 - 변수 선택 (4) | 2023.08.07 |
| [Machine Learning Advanced] 2강. 머신러닝 강의 - 데이터 전처리 (변수의 인코딩, 임베딩 방법) (3) | 2023.08.07 |



