
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 3줄 논문
- pytorch
- Python
- MySQL
- Segmentation
- 나는 리뷰어다
- eda
- TEAM EDA
- 튜토리얼
- 한빛미디어
- Machine Learning Advanced
- TEAM-EDA
- 추천시스템
- 파이썬
- 엘리스
- 협업필터링
- hackerrank
- 알고리즘
- 입문
- 코딩테스트
- Semantic Segmentation
- 스택
- DFS
- Image Segmentation
- 나는리뷰어다
- Object Detection
- 큐
- 프로그래머스
- Recsys-KR
- DilatedNet
- Today
- Total
TEAM EDA
[4차대회] 아파트 실거래가 예측 - 데이터 탐색 본문
0. 들어가며
- 위 대회는 데이콘에서 열린 4차 대회입니다.
- 직방에서 주어진 아파트 실거래가를 바탕으로 rmse를 최소화하는게 목표입니다.
- 대회 참여 기간은 2018.11.12 ~ 2019.1.31 입니다.
- 저희팀은 public score 3등 / private score 1등으로 우승을 했습니다.
- 분석의 내용은 데이터 탐색 / 모델링 두가지 부분으로 나뉘게 되며 모델링은 이어지는 글에 작성하겠습니다.
1. 서론
통계청 2015년 자료에 의하면 일반적인 한국인의 절반(48.1%)은 아파트에 살고 있습니다. 그들은 아파트 주거 선호도가 매우 높고 또한 부의 증식 수단으로 아파트 가격에 관심이 많습니다. 이번 대회의 이번 대회의 데이터 제공자는 직방입니다. 직방은 부동산 정보의 비대칭성과 불투명성을 해소하기 위해 노력하며, 중개사와 구매자를 연결하여 부동산정보 서비스 시장의 신뢰도를 높이는데 기여합니다. 최근 매물 가격 정보는 직방, 다음부동산, 네이버부동산에서 볼 수 있습니다. 하지만 최근 매물 가격은 아직 거래되지 않아 정확하지 않은 정보 일 수 있습니다. 이에따라, 본 대회는 아파트 구매자들의 비대칭성 정보를 해결하기 위해 미래의 실 거래가 예측을 목표로 합니다.
[Files]
- train.csv : 서울/부산 지역의 1,100,000여개 거래 데이터, 아파트 거래일, 지역, 전용면적, 실 거래가 등의 정보
- test.csv : 실 거래가를 제외하고 train.csv와 동일
- subway.csv : 서울/부산 지역의 지하철에 대한 정보
2. 파일 탐색
먼저 주어진 3개의 파일(train, park, subway)의 변수를 살펴보도록 하겠습니다.
Train의 변수는 크게 3가지 특성으로 구성되어 있습니다.
- 아파트 거래일과 같은 거래 시점
- 층수와 난방, 공급면적을 의미하는 아파트의 정보
- 단지 내 주차공간, 아파트의 수, 아파트의 최고 층과 같은 단지 정보

지하철의 정보는 아래와 같습니다.

3. 데이터 탐색 - 개별변수
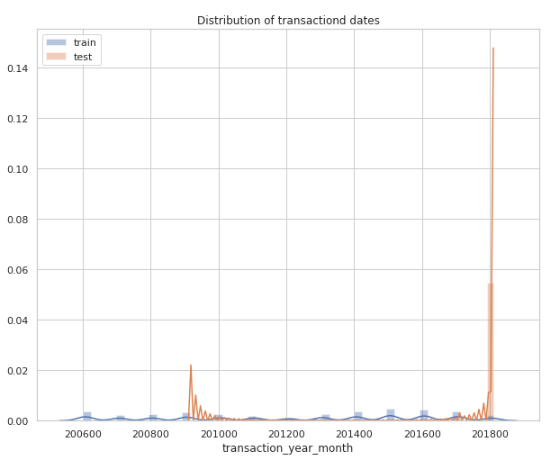
학습데이터와 평가데이터의 거래기간을 살펴보면 이상한 점을 발견할 수 있습니다. 학습데이터는 거래가 고른반면 평가데이터는 2009~2010년, 2018년 두 부분에 집중적으로 몰려있습니다. 이는 추후에 자세히 살펴보도록 하겠습니다.
다음으로는 아파트와 관련된 변수에 대해 살펴보도록 하겠습니다.
- year_of_completion : 아파트의 완공년도
- exclusive_use_area : 전용면적
- floor : 층
- heat_type : 난방 형태
- heat_fuel : 난방 연료
- room_id : 방의 크기를 인코딩한 정보
- supply_area : 공급면적
- room_count : 방의 갯수
- bathroom_count : 화장실의 갯수
- front_door_structure : 현관 구조
여기서 categorical변수는 heat_type , heat_fuel, room_id, front_door_structure이고 그 외는 numerical한 변수입니다.
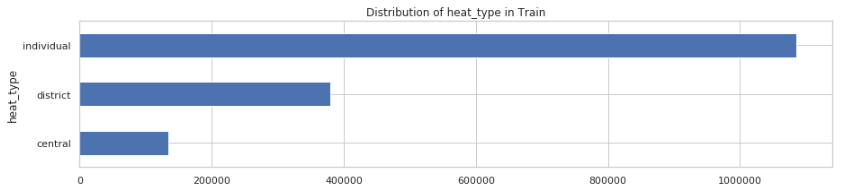


3가지 카테고리 변수의 바차트를 살펴보면 각 아파트별로 선호되는 유형이 보이고, 난방과 현관문구조에서 결측치 값을 보입니다. 먼저 각각의 의미를 살펴보고 왜 결측치를 가지는지 알아보도록 하겠습니다.
heat_type은 아파트별로 난방을 공급하는 형태가 어떻게 되어있냐는 변수입니다. 난방을 공급하는 형태는 3가지 종류가 있습니다. 개별난방, 중앙난방, 지역난방입니다. 개별난방은 각 세대별로 시설을 갖추어서 난방을 하는 형태입니다. 중앙난방은 단지 내 지하실같은 곳에 대형 보일러실을 갖추고 각 세대별로 난방을 공급하는 형태이고, 지역난방은 지역 내 일정한 공간에서 배관망을 통해서 각 단지에 공급하는 형태입니다.
heat_type과 연관된 변수는 heat_fuel입니다. 동일한 개별난방이어도 어떤 연료가 들어오냐에 따라 장단점이 달라지게 됩니다. 대표적으로는 LPG와 같은 gas를 사용하는 경우는 온수를 돌리면 빠르게 온수가 나오지 않는 단점이 있습니다. 그에 반해 cogneration은 열과 전기를 동시에 공급하는 형태로 그런 단점이 없습니다.
front_door_structure는 현관문의 구조를 의미합니다. stairway, mixed, corridor 3가지 형태가 있는데, 각각 계단식, 복합식, 복도식을 의미합니다. 복도식 아파트는 한층에 여러개의 가구가 있어서 같은 층의 모든 세대가 긴 복도를 함께 공유하는 현관 구조를 가집니다. 계단식 아파트의 경우는 한층에 2개의 세대가 있는 경우로 보통 엘레베이터에서 내리면 양옆으로 세대가 있는 경우입니다. 마지막으로 복합식의 경우는 한층에 3세대 정도가 있는 경우라고 합니다. 각각의 front_door_structure마다 장단점이 있는데, Homecc 인테리어(형태와 구조에 따른 아파트의 구분법)에서 참고한 내용으로는 아래의 표와 같습니다.
| 장점 | 단점 | |
| 계단식 | 맞바람으로 인해 환기가 잘 되며, 계단식 아파트보다 같은 면적 대비 가격이 저렴 | 단열이나 방음, 보안이 약한 편 |
| 복도식 | ||
| 복합식 | 복도식 아파트보다 전용면적이 넓고 배치가 다양해 조망이 좋은 편 | 배치된 방향에 따라 일조권이 좋지 않을 수 있고 계단식 아파트보다 소음에 노출되기 쉬움 |
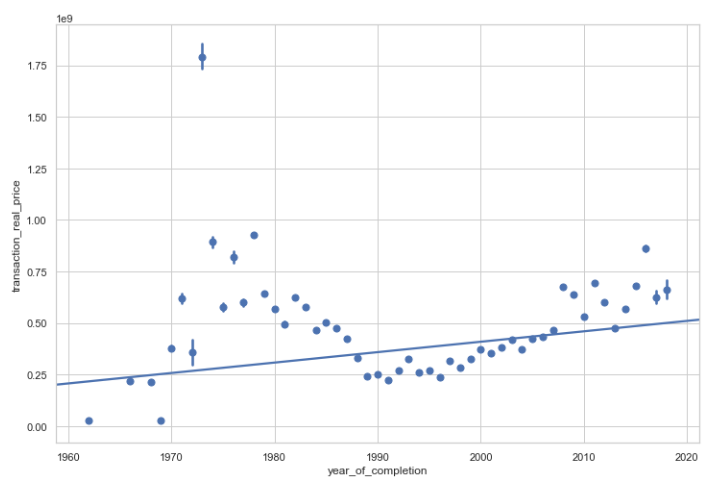
다음으로 Numerical한 변수들에 대해 살펴보도록 하겠습니다. year_of_completion은 완공년도로 아파트가 몇년도에 완공되었는지를 의미합니다. 그래프를 살펴보면 오른쪽으로 살짝 치우져진 분포를 가지고 있습니다.

1970년도로 과거에 만들어진 아파트에서부터 2018년으로 아파트가 팔린 해에 만들어진 아파트도 있습니다.
exclusive_use_area는 전용면적으로 아파트의 가격을 결정짓는 중요한 요소중에 하나입니다. 의미는 순수하게 내가 거주하는 공간의 면적을 의미합니다. 그렇다면 supply_area(공급면적)은 전용면적에서 주거 공용면적(엘레베이터 + 주차장 + 복도 등)을 포함한 면적을 의미합니다. 공급면적이 보통 우리가 말하는 평수에 해당합니다.


둘 사이의 그래프의 모양은 똑같지만 위에서 살펴본 의미 그대로 공급면적이 전용면적보다 조금 더 오른쪽으로 치우친 것을 확인할 수 있습니다.
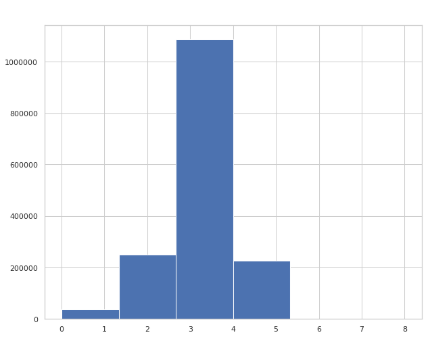
마지막으로 floor(층)과 방, 화장실의 변수들을 살펴보도록 하겠습니다. 먼저 층의 경우 -4층(지하)부터 80층까지 굉장히 범위가 넓었습니다.

그리고 분포를 살펴보면 9층에 많이 분포해있고 점차 긴 오른꼬리를 가지는 모습입니다.

방과 화장실의 경우 각각 아래의 그래프를 가지고 방이 화장실보다 큰 값을 가지는걸 볼 수 있습니다.

4. 데이터 탐색 - 상호작용변수
위에서 살펴본 변수들이 개별변수에 대한 분석이라면 이제부터는 각 변수와 다른 변수간의 상호작용을 통해서 변수가 의미하는 것들을 자세히 살펴보도록 하겠습니다. 먼저 목적변수와 입력변수간의 상관관계를 보겠습니다.
먼저 완공년도를 의미하는 year_of_completion과 Target변수와의 regression plot을 살펴보면 아래와 같습니다.
'EDA Project > Dacon' 카테고리의 다른 글
| [8차 대회] 신용카드 거래 데이터 시각화 대회 (0) | 2019.09.11 |
|---|---|
| [5차 대회] 신용카드 거래 데이터 시각화 대회 (0) | 2019.09.11 |
| [5차대회] Data Visualization Challenge 평가기준 (0) | 2018.12.28 |

