
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- hackerrank
- TEAM EDA
- Segmentation
- 코딩테스트
- Image Segmentation
- eda
- DFS
- MySQL
- Recsys-KR
- 프로그래머스
- 나는리뷰어다
- 한빛미디어
- Semantic Segmentation
- 엘리스
- pytorch
- 협업필터링
- 파이썬
- Machine Learning Advanced
- TEAM-EDA
- DilatedNet
- 큐
- Python
- 추천시스템
- 3줄 논문
- 스택
- 나는 리뷰어다
- 알고리즘
- 튜토리얼
- Object Detection
- 입문
- Today
- Total
TEAM EDA
Lecture 1 – Introduction and Word Vectors 본문
CS224N의 1주차 강의 Introduction and Word Vectors의 강의 순서입니다. 기본적인 인간의 언어에 대해 먼저 이야기를 하고 Wor2Vec와 Gensim에 대해서 이야기를 진행합니다.

1. The course
CS224n의 강의를 통해서 배울 수 있는 것은 아래와 같습니다. 첫째로, attention과 같은 최근 deep learning의 기법들을 배우고 이해할 수 있습니다. 두번째로, 사람의 언어가 왜 이해하기 어려운지 그리고 어떻게 생산해야 하는지, 이해해야 하는지에 대해 알 수 있습니다. 마지막으로, PyTorch를 이용하여 자연어처리의 많은 문제들을 해결할 능력을 기를 수 있습니다.

2. Human language and word meaning

우리는 단어의 의미를 어떤식으로 표현합니까? 사전적으로 의미의 정의는 아래와 같이 단어 혹은 구절, 표현들을 통해 전달하고자 하는 생각을 뜻합니다.

아래의 그림처럼 우리는 단어의 의미를 인식합니다. Signifier(symbol - 단어)을 보고 그 속에 숨겨진 signified(idea or thing - 의미)를 받아들이는 것 입니다.

How do we have usable meaning in a computer?
위의 방식이 인간이 의미를 인식하는 방법이라면, 아래는 컴퓨터가 의미를 인식하는 방법입니다. 컴퓨터는 의미를 인식하는 방법의 하나로 WordNet이라는 것을 사용합니다. WordNet이란(https://ko.wikipedia.org/wiki/%EC%9B%8C%EB%93%9C%EB%84%B7) 영어의 의미 어휘목록입니다. 영어 단어를 'synset'이라는 유의어 집단으로 분류하여 간략하고 일반적인 정의를 제공하고, 이러한 어휘목록 사이의 다양한 의미 관계를 기록합니다. (일종의 사전과 같은 개념입니다.) 아래의 예시를 보면 컴퓨터는 good이라는 단어를 보고 의미를 파악할때, good과 비슷한 명사, 형용사, 부사 등을 사람이 기록한 사전을 보고 파악합니다.


하지만 위와 같은 방식은 문제점이 있습니다. 첫째로, 어감이나 숨겨진 의미를 인식하기 어렵습니다. 문맥을 인식하지 않고 단어를 보다보니 문맥에 따라서 의미가 달라지는 경우 정확한 의미를 파악하기 어렵습니다. 둘째로, 단어들의 최신 정보를 유지할 수 없습니다. 사전을 항상 개선하지 않으면 새로운 의미나 새로운 단어들의 정보를 알 수 없다는 것 같습니다. 추가적으로 사람이 사전을 기록하기에 주관성이 들어가고, 단어의 유사성을 정확하게 계산하지 못한다는 점 등등의 문제도 있습니다.

전통적인 NLP에서 우리는 단어를 구별 된 의미로 살펴봤습니다. hotel, motel 은 비슷한 표현이지만 컴퓨터는 둘을 one-hot vector으로 바꾸기 때문에 독립된 단어로 인식합니다.

위에처럼 단어를 discrete하게 인식하게 되면 생기는 문제는 아래와 같습니다. 웹에서 Seattle motel를 찾으려고 하면, 우리는 비슷한 의미인 Seattle hotel까지 같이 살펴볼 수 있습니다. 하지만 둘을 discrete하게 인식하게 되면 motel과 hotel은 orthogonal하게 인식하기 때문에 둘 사이의 유사성은 아예 없다고 생각하게 됩니다. 그러면 motel과 비슷한 hotel이 검색어에 노출되지 않는 문제로 이어지게 됩니다. 이를 해결하기 위해서, vectors자체를 유사성으로 표현하는 시도를 하게 되고 Word2vec라는 개념이 도입되게 됩니다.

위의 Word2vec이 도입되기 위한 핵심 개념은 단어의 의미를 파악하기 위해서 주변의 단어들을 살펴보는 것입니다. Distributional sematics의 가정은 '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다' 입니다. 예를들어, 강아지는 귀엽다, 강아지는 예쁘다, 강아지는 사랑스럽다. 라는 3가지의 문장에서 귀엽다/예쁘다/사랑스럽다를 비슷한 의미를 가진다라고 인식하는 기법입니다.
파리의 언어학도님의 설명에 따르면, 이렇게 단어들의 수치화된 분포표현(distributional representation)은 단어들의 유사도에 기반하여 표현된다. 여기서 말하는 단어의 유사도는 해당 단어와 함께 출몰한 주변단어(context)를 기준으로 결정되기 때문에, 결국 단어의 "symbol"을 말하는 것이 아닌 단어가 가지고 있는 문법적, 개념적 "의미" (semantics of word meaning)을 나타낼 수 있게된다. 예를들면, 아래의 그림에서 banking자리를 대신 할 단어는 뭐가 될까? 주변단어(context)를 고려하면 아마 banking과 비슷한 품사, 의미를 가진 단어가 들어갈 수 있다.

위의 가정을 통해 Word2vec을 적용하면 아래와 같이 원핫벡터가 아니라 유사도벡터로 표현 된 임베디드된 결과를 얻을 수 있습니다. 추가적으로 위에서 설명한 단어의 symbol표현을 one-hot encoding이라고 한다면, 의미를 내포한 단어표현 (distributional representation)은 word Embedding으로 표현합니다.

아래의 사진은 Word2vec에 의해서 비슷한 단어들끼리 모아진 결과를 보여주고 있습니다.

위에까지 Word2vec의 개념과 결과를 알아봤고 이제는 어떤 알고리즘으로 작동하는지 알아봐야 합니다.

기본적으로 텍스트의 말뭉치가 많을 때, Word2vec은 두가지 방식으로 진행됩니다. 주변단어로 중심단어를 예측하는 CBOW 방식, 중심단어로 주변단어를 예측하는 Skip-Gram 입니다. Skip-Gram의 경우 CBOW보다 학습을 개선 할 수 있는 횟수가 많기 때문에 성능이 좋다고 알려져 있습니다. 아래의 두가지 슬라이드는 Word2Vec이 학습하는 과정을 보여준 것입니다. 하지만 예시로는 적합하지 않기 때문에, ratsgo님의 블로그에 있는 예시로 이해해보도록 하겠습니다.

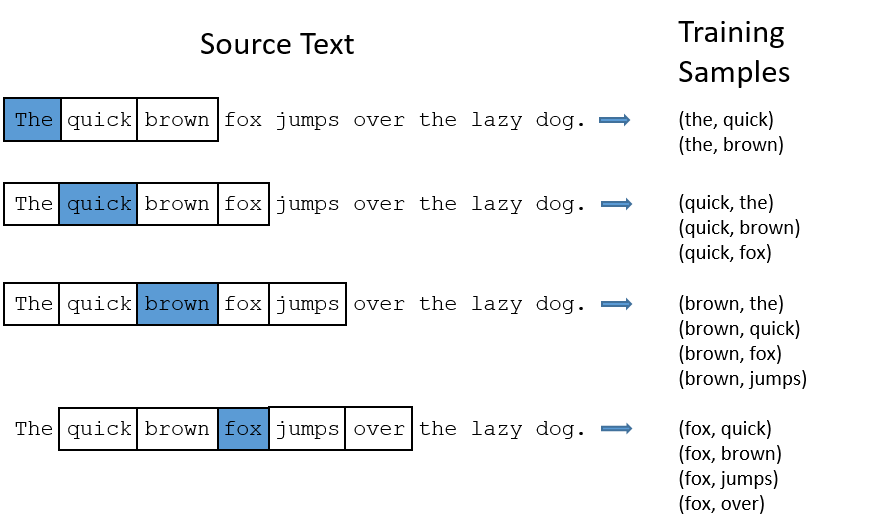
‘The quick brown fox jumps over the lazy dog.’ 문장으로 시작하는 학습말뭉치가 있다고 칩시다. 윈도우(한번에 학습할 단어 개수) 크기가 2인 경우 아키텍처가 받는 입력과 정답은 아래와 같습니다. 아래의 과정은 The로 시작해서 dog까지 총 9번의 Step이 진행 되고, 그 속에서 내가 설정한 window size에 따라 학습이 여러번 돌아가게 됩니다. 첫번째 Step인 The를 보면, The를 중심단어로 하고 quick과 brown을 주변단어로 합니다. 그리고 이를 같이 학습하는 것이 아니라 (the, quick) (the, brown)을 따로하여 학습을 진행하게 됩니다. 이러한 부분이 skip-gram이 cbow와 다른 부분입니다. cbow는 brown과 quick을 같이 학습함에 따라 1번의 학습만 진행하게 됩니다. 하지만 skip-gram의 경우 주변단어의 갯수만큼 학습을 진행하면서 업데이트를 하기 때문에 성능이 더 좋을 수 밖에 없습니다.
이제 수식을 살펴보도록 하겠습니다. t = 1, ... , T (T = 단어의 갯수)를 가지고 window size를 m으로 설정할 때 다음의 Likelihood를 계산하게 됩니다. 위의 식을 예시로 하면, T는 9이고 m은 2로 설정되어지고 The부터 dog까지 9번의 과정을 거칩니다. 그리고 그 과정속에서 m = 2일때, P(wt+j | wt ; ceta)를 곱한 값을 계산합니다. 마지막으로 log를 씌움으로써 곱하기를 더하기로 바꾸고 최종적인 목적식을 최적화하도록 설정되어있습니다.
Likelihood가 objective function부분으로 바꾼부분은 파리의 언어학도님의 블로그에 설명이 잘 나와있습니다. 우리는 여기서 확률적 고찰 J'(세타)을 마치고 기계학습의 관점에서 생각을 해보자. J(세타)가 기계학습의 관점으로 변경한 수식인데, 이 때 수식에 -1/T이 추가되고 log를 씌우는 일이 발생했다. 이 말은 바꿔서 말하면 Negative log-likelihood 방식으로 우류에 대한 loss를 계산한다는 이야기입니다. Negative log-likelihood 방법은 기계학습에서 많이 사용되는데, 확률 수식 J'(세타)가 최대확률값을 반환하는 파라미터들을 찾는 문제였다면, 기계학습에서는 손실값 J'(세타)을 최소로 하는 파라미터를 찾는 일로 바꾼 것이다. 그래서 negative부분은 -1/T 를 의미하고 log를 씌우는 이유는 p값이 1이하로 매우 작아서 이를 커지게 함으로써 계산의 편리함과 loss값의 분포를 regular하게 만드는 효과가 있다.

하지만 여기서 문제는 P(wt+j | wt ; ceta)를 구하는 방법을 알아야 한다는 사실입니다. 아래의 내용은 ratsgo's의 블로그에서 설명 한 내용이 나와있습니다.
아래의 식을 벡터의 곱으로 나타내면 아래의 p(o|c)와 같이 나타낼 수 있습니다. 이 식의 의미는 중심단어(c)가 주어졌을 때, 주변단어(o)가 나타날 확률이라는 뜻입니다. 식을 최대화하려면 우변의 분자는 키우고 분모는 줄여야 합니다.

우선 우변의 vv는 입력층-은닉층을 잇는 가중치 행렬 WW의 행벡터, uu는 은닉층-출력층을 잇는 가중치 행렬 W′W′의 열벡터입니다.
우변 분자의 지수를 키우는 건 중심단어(c)에 해당하는 벡터와 주변단어(o)에 해당하는 벡터의 내적값을 높인다는 뜻입니다. 벡터 내적은 코사인이므로 내적값 상향은 단어벡터 간 유사도를 높인다는 의미로 이해하면 될 것 같습니다.
분모는 줄일 수록 좋은데요, 그 의미는 윈도우 크기 내에 등장하지 않는 단어들은 중심단어와의 유사도를 감소시킨다는 정도로 이해하면 될 것 같습니다.
아래는 Word2Vec의 학습파라메터인 중심단어 벡터 업데이트 과정을 수식으로 정리한건데요, 저도 정리 용도로 남겨 두는 것이니 수식이 골치 아프신 분들은 스킵하셔도 무방할 것 같습니다. 중심단어 벡터의 그래디언트는 아래와 같습니다.
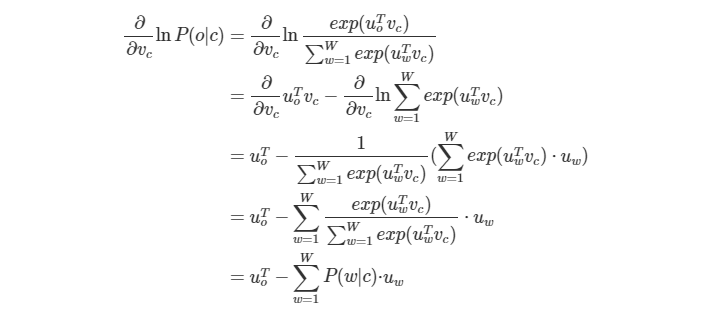
이렇게 구한 중심단어 그래디언트의 반대 방향으로 조금씩 중심단어 벡터를 업데이트합니다. (여기서 알파는 사용자가 지정하는 학습률=learning rate)

출처 : ratsgo's의 블로그 Word2vec 부분

위에서 말한대로 p(o|c)의 분모는 윈도우 크기 내에 등장하지 않는 단어들과 중심단어와의 유사도이고 분자는 윈도우 크기 내에 등장하는 단어들과 중심단어와의 유사도입니다. 그리고 이 구조는 softmax function하고 매우 비슷한데, softmax함수는 입력받은 값의 출력을 0~1사이의 값으로 모두 정규화하여 출력 값들의 합을 항상 1이 되도록 하는 function입니다.

위의 식에서 에러를 최소화하기 위해서 우리는 파라미터를 최적화 해야 합니다. 이때 파라미터를 최적화하는 방법으로 사용하는 방식이 Gradient Descent(경사하강법)입니다.
참고자료
- https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
- https://ratsgo.github.io/natural%20language%20processing/2017/03/08/word2vec/
- https://arxiv.org/pdf/1301.3781.pdf
- https://www.youtube.com/watch?v=8rXD5-xhemo&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z
- https://blog.naver.com/jujbob/221147997064
'강의 내용 정리 > CS224N' 카테고리의 다른 글
| Lecture 3: Word Window Classification,Neural Networks, and Matrix Calculus (0) | 2019.04.19 |
|---|---|
| Lecture 2: Word Vectors and Word Senses (2) | 2019.04.14 |

