
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Semantic Segmentation
- Segmentation
- 코딩테스트
- 나는리뷰어다
- 추천시스템
- 스택
- TEAM EDA
- Machine Learning Advanced
- Object Detection
- 튜토리얼
- Recsys-KR
- eda
- 큐
- DilatedNet
- pytorch
- 파이썬
- hackerrank
- 협업필터링
- TEAM-EDA
- 입문
- 알고리즘
- 엘리스
- Python
- 프로그래머스
- Image Segmentation
- 나는 리뷰어다
- DFS
- MySQL
- 한빛미디어
- 3줄 논문
- Today
- Total
TEAM EDA
[Kaggle] IEEE-CIS Fraud Detection 1st Solution (Disscussion) 본문
원문 링크
Summary
Main magic:
- client identification (uid) using card/D/C/V columns (we found almost all 600 000 unique cards and respective clients)
- uid (unique client ID) generalization by agg to remove train set overfitting for known clients and cards
- categorical features / supportive features for models
- horizontal blend by model / vertical blend by client post-process
Features validation:
We've used several validation schemes to select features:
- Train 2 month / skip 2 / predict 2
- Train 4 / skip 1 / predict 1
We were believing that it was the most stable option to predict future and unknown clients.
Models:
We had 3 main models (with single scores):
- Catboost (0.963915 public / 0.940826 private)
- LGBM (0.961748 / 0.938359)
- XGB (0.960205 / 0.932369)
Simple blend (equal weights) of these models gave us (0.966889 public / 0.944795 private). It was our fallback stable second submission.
The key here is that each model was predicting good a different group of uids in test set:
- Catboost did well on all groups
- XGB - best for known
- LGBM - best for unknown
Predictions:
- 6 folds / GroupKfold by month
- almost no fine-tuning for models
Time is not most important
- 이번 대회는 시간에 관련된 대회가 아니다.
- adversarial validation의 AUC가 1을 가진다는 것은 시간에 따른 FRAUD유형이 바뀐다는 의미가 아니라 데이터셋의 사람이 바뀐다는 의미이다.
- 이 사실을 깨달으면, 이 대회는 unseen clients를 잘 예측하도록 모델을 만드는 것이 중요하다.
- 아래의 그림은 Private set의 데이터를 그린 것이다. 68.2%의 고객은 train data에서 보지 못한 사람들이고, 16.4 %는 train data에서 본 사람들이고, 15.4%는 알 수 없는 사람들이다.
- 각각의 파란선은 하나의 고객을 의미하고, 하나의 고객은 시간에 따라 많은 거래를 발생시킨다.
- 왼쪽끝은 첫번쨰 거래를 오른쪽 끝은 마지막 거래를 의미한다.
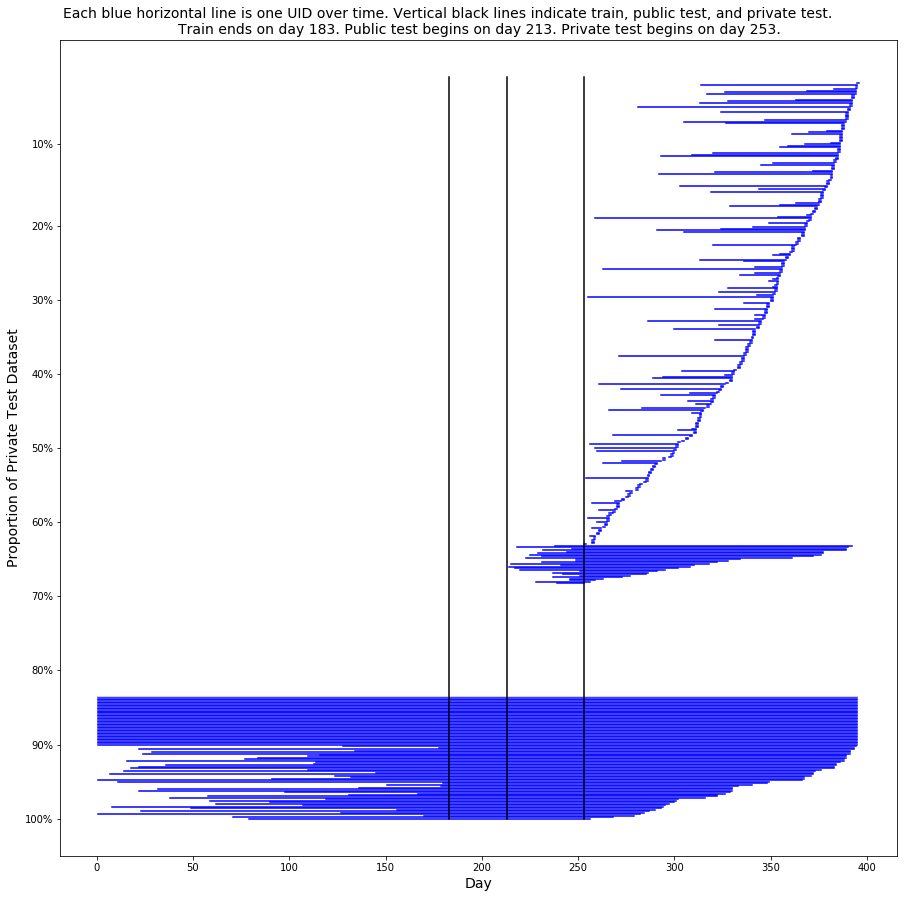
Magic Feature
-
대회 HOST Lynn에 따르면, 이 대회는 fraud transactions을 탐지하는 것이 아닌 해당 거래를 발생시킨 사용자를 찾는 대회라고 했음
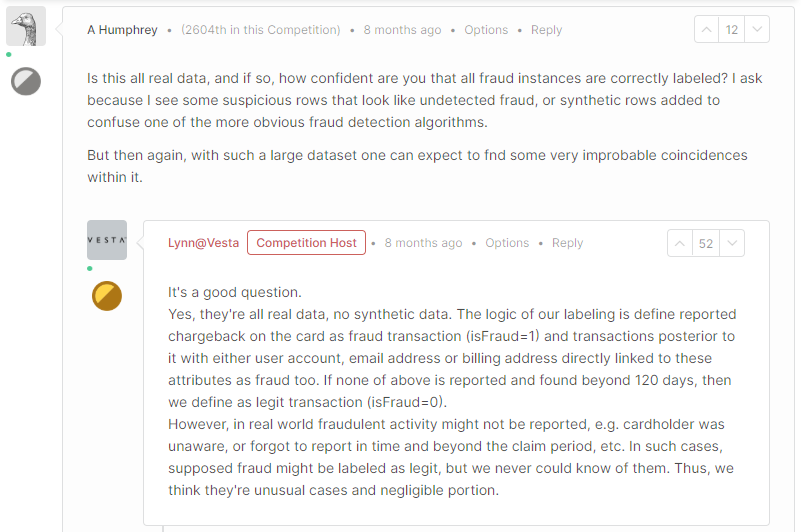
The logic of our labeling is define reported chargeback on the card as fraud transaction (isFraud=1) and transactions posterior to it with either user account, email address or billing address directly linked to these attributes as fraud too. If none of above is reported and found beyond 120 days, then we define as legit transaction (isFraud=0). -
즉, 고객이 fraud transaction을 발생시키면, 전체 계좌의 거래 내역이 isFraud가 1로 바뀌게 된다. 그러므로 우리는 fraud를 발생시킨 고객들을 예측하는 것이 중요하다.
-
120일 후에 카드의 isFraud가 0이 된 고객들을 드물게 training data에서 볼 수 있다. (이는 사기를 발생했던 신용카드가 재사용되었다는 것보다는 종료되었다는 의미같다. <- 무슨말인지 모르겠어요...)
-
아래의 파이차트는 이에 대한 내용을 보여준다. 전체 training dataset의 2개 이상의 거래를 한 738338명의 사용자의 거래입니다. 그 중 96.9%는 항상 isFraud가 0이고 2.9%는 항상 1이고 오직 0.2%만 둘이 섞여있다.
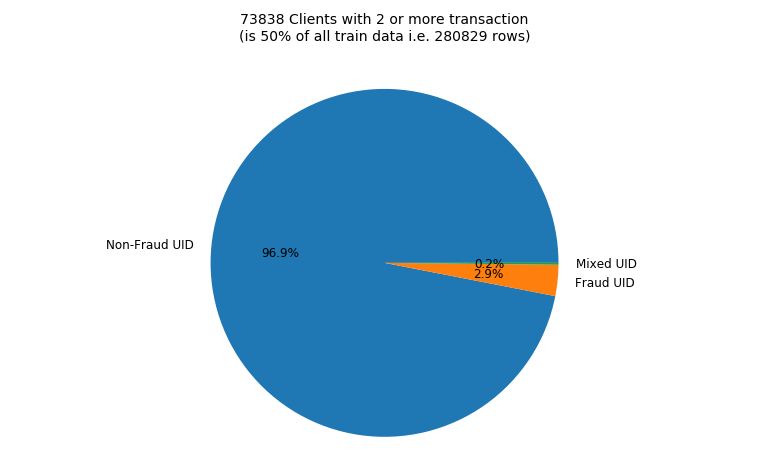
Fraudulent Clients
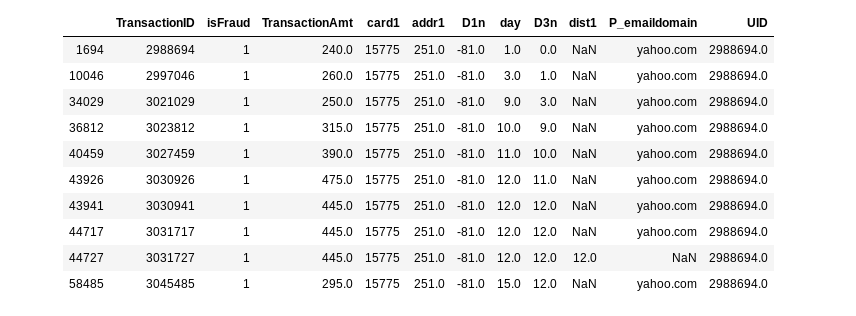
다음은 isFraud가 1인 Client_id 2988694의 고객이다. 클라이언트를 식별하는 핵심은 세 개의 열 card1, addr1 및 D1이다. 변수 D1은 "클라이언트 (신용 카드)가 시작된 날"이다. 따라서 D1n = TransactionDay에서 D1을 뺀 값은 카드가 시작된 날을 의미한다. (TransactionDay = TransactionDT / (24 * 60 * 60)). 아래 예에서 이 신용 카드는 -81 일에 시작되었고, 이는 2017 년 12 월 1 일에 데이터 세트가 시작되기 때문에 2017 년 9 월 10 일을 의미한다. 또한 D3n = TransactionDay에서 D3을 뺀 값은 각 클라이언트의 마지막 트랜잭션 날짜를 가리키는 의미한다.
이것말고도 고객을 식별하는 데 도움이되는 변수들이 있다. 이에 대한 내용은 다음의 커널을 보면 된다.
Preventing Overfitting
train과 public test dataset에 오버피팅되는것을 예방하기 위해서, UID를 직접적으로 모델에 사용하지 않았다. 대신에 UID을 식별할 수 있는 D, V, ID 컬럼들을 사용했다. (어떤 변수가 유저 아이디를 식별하는 지 확인하려면 이 커널을 보면 된다)
우리는 UID를 직접적으로 사용하지 않았는데, 그 이유는 68.2%의 사용자가 PRIVATE에서는 나타나지 않았기 떄문이다. 대신에 우리는 aggregated Group을 이용한 파생변수들을 활용했다. 예를들어, 아래와 같이 C, M을 이용해서 사용하고 UID는 삭제했다. 이렇게 함으로써 학습하지 못한 UID에 대해 더 잘 모델이 분류할 능력을 가지게 되었다.
new_features = df.groupby('uid')[CM_columns].agg(['mean'])How to Find UIDs
우리는 UID를 두가지 방법으로 찾았고 구체적인 내용은 다음의 디스커션에 있습니다.
이전의 콘스탄틴의 original public FE kernel은 UID가 없이 AUC = 0.924에 LB 0.9485 였다. UID를 활용한 그의 커널은 AUC = 0.9377 , public LB 0.9617 을 달성할 수 있었다. 스크립트로 UID를 생성하는 목적은 EDA와 validation tests, post process를 위함이고 모델에는 직접적으로 사용하지 않았다. 대신, 머신러닝이 사용자를 잘 발견할 수 있도록 도와주었다.
UID는 다음의 3가지를 가능하게 해줍니다.
- Model이 fraud를 더 잘 발견하도록 한다.
- 우리가 seen clients와 unseen clients에 대해 학습을 잘 수행했는 지 알려준다.
- post processing을 할 수 있게 해준다.
캐글의 사기 경쟁 데이터 세트에는 430 개의 열이 있습니다 !! 고객을 식별하는 데 도움이되는 열을 어떻게 알 수 있습니까? 처음에는 열을 수동으로 살펴보고 시행 착오를 사용하여 UID를 만들었습니다. 나중에 더 체계적인 접근 방식을 개발했습니다.
트레인 및 테스트 데이터에는 각기 다른 클라이언트 집합이 있으며 (일부 클라이언트는 동일, 일부는 다름) 적대적 유효성 검사를 수행하여 클라이언트를 구별하는 데 도움이되는 열을 찾을 수 있습니다. (즉, 모든 학습 데이터와 테스트 데이터를 함께 혼합. 그 후 새 열 "is_this_transaction_in_test_data?"를 추가하십시오. 그런 다음 트랜잭션이 테스트 데이터에 있는지 또는 데이터를 학습 하는지를 분류하는 모델을 학습하십시오.) D 열을 변환 한 후 처음 53 개 열에서만 이 작업을 수행하면 AUC = 0.999 및 다음의 변수 중요도를 볼 수 있습니다.

사용자를 식별하는 데 가장 중요한 열은 D10n, D1n, D15n, C13, D4n, card1, D2n, card2, addr1, TransactionAmt 및 dist1입니다. 클라이언트를 찾는 데 사용해야하는 열입니다.
모델을 일반화하기 위해 card1, addr1, D1n에서 uid를 형성하고 uid에 대한 집계로 다른 기능을 제공합니다. 열 D4n, D10n, D15n은 특정 시간 날짜이므로 (주 D4n = 일-D4) 집계 된 평균 및 표준 편차를 제공합니다. 특정 uid가 D15n에 대해 std = 0이면 모든 D15n이 동일하다는 것을 알 수 있습니다 (변경되지 않음). std! = 0이면 해당 특정 uid에 실제로 2 개 이상의 클라이언트가 포함되어 있으며 모델이 이를 분할합니다. 열 C13은 누적 카운트 열입니다. 따라서 uid를 이용해 nunique를 집계하는 것을 선호합니다. 그런 다음 집계 된 nunique 수가 uid_FE와 같으면 (uid_FE :uid 내의 트랜잭션 수) 이것이 하나의 클라이언트라는 것을 알 수 있습니다. uid_FE! = AG (C13, uid, nunique) 인 경우이 uid에는 둘 이상의 클라이언트가 포함되어 있으며 모델은 이를 분할합니다.
339 개의 V 열이 있습니다. 어느 쪽이 고객을 식별합니까? 다시 한 번 V 열에 대해서만 적대적 유효성 검사를 수행하고 AUC = 0.999를 얻습니다. 다음과 같은 열이 중요합니다.

NAN V 블록 V126-V136의 열은 클라이언트를 식별하는 데 중요하고 NAN V 블록 V306-V320의 열은 클라이언트를 식별하는 데 중요합니다. 여기에서 상관 감소를 수행 한 후 다음과 같은 중요한 V 열이 남아 있고 uid를 통해 집계됩니다. 여기에서 상관 감소를 수행 한 후 다음과 같은 중요한 V 열이 남아 있고 uid를 통해 집계됩니다.
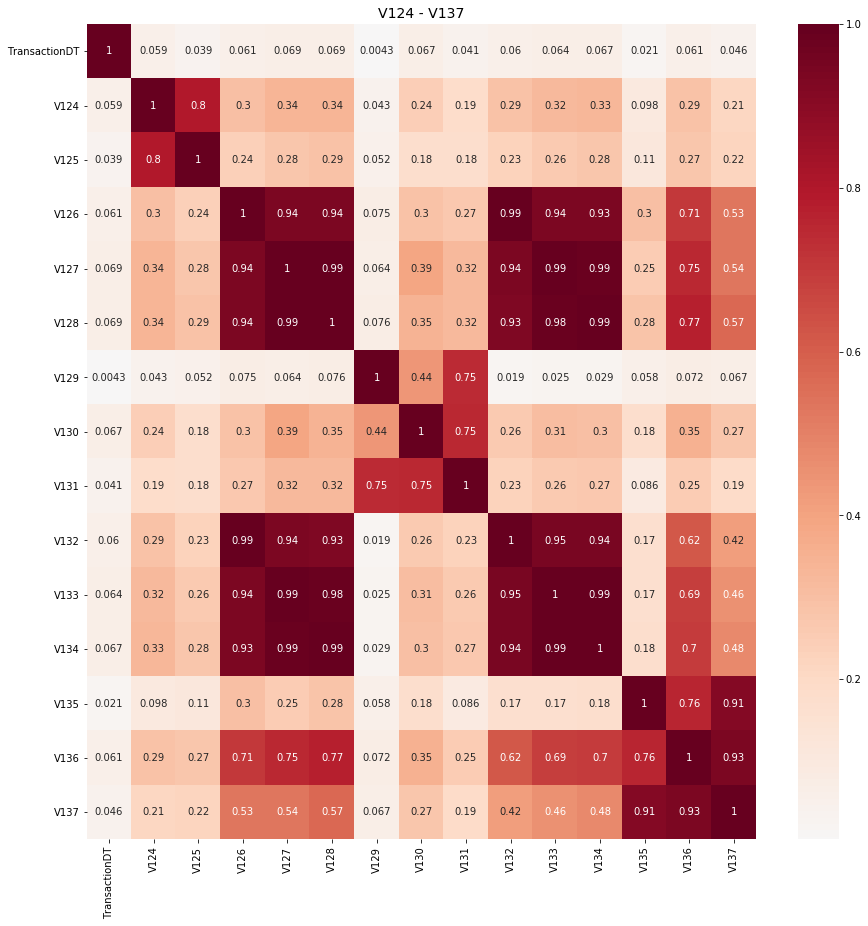

아래의 6 줄의 코드는 클라이언트 (신용 카드)를 찾은 다음, 클라이언트 (신용 카드)를 분류하는 그룹 기능을 모델에 제공해야합니다. 다시 한 번, uid에 중요한 열을 집계하여 이 작업을 수행합니다.
encode_AG(['D9'],['uid'],['mean','std'])
encode_AG(['P_emaildomain','DT_M','id_02','cents'], ['uid'], ['nunique'])
encode_AG(['C'+str(x) for x in range(1,15) if x!=3],['uid'],['mean'])
encode_AG(['M'+str(x) for x in range(1,10)],['uid'],['mean'])
Q. 모델이 UID를 발견할 수 있도록 도와준다는 말이 무슨 의미인가요? card, addrs, Ds를 이용해 UID를 발견하는 것과 어떻게 다른것인가요??
A. 실제 Client group은 card1 + addr1 + D1n보다는 작습니다. 그러나 건축가로써 우리는 card1 + addr1 + D1n + D15n 와 같은 정교한 값을 사용하도록 하면 안됩니다. 대신 우리는 uid1과 D15n을 따로 주고 모델 스스로 둘을 결합도록 해야합니다. 게다가 uid1에 대한 집계로 D4, D10, D15, C13, C14, V127, V136, V307, V309, V320 과 같은 변수들을 제공할 수 있습니다.
예를 들어, C14는 대부분 단일 client에 대해 동일하게 유지되어야합니다. 스크립트에서 우리는 df.groupby(['uid']).C14.agg(['std'])를 통해 그렇게 했습니다. std가 0일 때, 모델은 C14가 전체 UID에 대해 동일하다는 것을 알고 있습니다. std가 0이 아닌 경우, 모델은 uid에 둘 이상의 client가 포함되어 있음을 알 고 있습니다. 다음으로 모델을 다른 변수들을 사용하여 해당 uid를 둘 이상의 고객으로 분리합니다. 모델이 스크립트에서 시행하는 규칙보다 C14를 더 잘 사용하는 방법을 모델이 파악할 것 입니다.
An actual client group is smaller than uid1 = card1+addr1+D1n where D1n=day-D1. But as the architect we shouldn't force our model to use a more precise uid such as uid2 = card1+addr1+D1n+D15n. Instead we should give it uid1 and D15n separately and let the model decide when it wants to combine the two. Furthermore we can give it columns dist1, D4, D10, D15, C13, C14, V127, V136, V307, V309, V320 as various aggregations over uid1.
For example, C14 should stay the same for a single client (card holder) most of the time. In our script we enforce that is does all the time. But we give our model df.groupby('uid').C14.agg(['std']). When std=0, the model knows that the C14 is the same for the entire uid. When std!=0, the model knows that that uid contains more than 1 client. Next the model will use another column to separate that uid into 2 or more clients. You see the model will figure out how to use C14 better than the rules we enforce in our script.
Q. 놀라운 생각이야. 나는 이것을 올바르게 이해하고 싶어. UID2의 예시에서, UID와의 상호작용을 강요하지 않고 단순히 D15n을 변수로 추가한거야?
A. 음... 나는 당신이 uid2 = card1+addr1+D1n+D15n을 사용하는 것은 나쁜 생각이 아니에요. 콘스탄틴이 하는 일 입니다. 그리고 그것은 잘 작동합니다. 그러나 나는 매우 정교한 uid를 만드는 경우 모델은 인간이 만든 정교한 uid를 선택할 수 밖에 없습니다. 이럴 경우에는 좋은 생각이 아닌 것 같습니다.
그래서 나는 uid와 추가적인 변수들을 주는 것을 선호한다. D15n같은 변수는 동일한 D15n을 가진 값을 트랜잭션들이 같은 클라이언트에 속할 가능성이 높으므로 도움이 됩니다. 따라서, D15n을 block으로 만듭니다. 또다른 building block은 $X_train['outsider15'] = (np.abs(X_train.D1-X_train.D15)>3).astype('int8')$ 이었다. 이러한 boolean은 모델이 D15n과 D1n을 비교하도록 도와준다. 만약 2이내의 값을 가지면 uid가 옳은 것으로 모델이 판단한다.
추가적으로 $df.groupby('uid').D15n.agg(['mean','std'])$와 같은 변수를 모델에 제공할 수 있다. 다른 예로는 C10이다. C10은 대체적으로 증가하는 모습을 가지므로 너는 $df.groupby(['uid'])['C10'].shift()$와 같은 값을 줄수도 있다. 만약 이 값이 음수라면, UID는 시간에 따라 감소하는 C10을 포함할 것이다. 결론적으로, 나는 어떤 변수들이 고객을 식별하는데 도움이 되는지 찾는 것이 중요하다 생각하고 그 다음에 그들을 다른 변수들과 상호작용하도록 변환해서 LGBM이 모델을 잘 설계할 수 있도록 도와주는 것이 필요해보인다.
So I prefer giving it uid and additional "building blocks". The featureD15n = day - D15helps because transactions that have the same D15n are more likely to belong to the same client. ThusD15nis a building block. Another building block is the feature $X_train['outsider15'] = (np.abs(X_train.D1- X_train.D15)>3).astype('int8').$ This boolean helps your model compare D15n to D1n. If these two numbers are within plus or minus one of each other that adds confidence thatuidis correct. Additionally give your model $df.groupby('uid').D15n.agg(['mean','std']).$ Another example is that C10 is usually increasing so you can give it $df.groupby(['uid'])['C10'].shift()$ which should always be zero or one. If it is negative than uid contains a C10 that decreases in time.
So in conclusion, i thinks it is important to know which columns help identify clients and then transform them and/or interact them with the others in a way that LGBM can utilize to create some "black box" rule about which transactions are from the same client (credit card).
Q. Just awesome! That's all I have to say…
The reason adversarial validation has AUC=1 is not because the nature of fraud changes radically over time but rather because the clients in the dataset change radically over time.
I was most concerned that my model's adversarial validation is always nearly auc=1, but you taught me the truth behind it.
And one question about your solution..
In the Preventing Overfitting part. You said..
new_features = df.groupby('uid')[CM_columns].agg(['mean'])
But as I know, M features are categorical features. How did you get aggregate group statistics for M features?
Thanks as always!
대단해!! 그게 전부 야
적대적 유효성 검사에 AUC = 1이 있는 이유는 사기의 특성이 시간이 지남에 따라 급격히 변하기 때문이 아니라 데이터 집합의 클라이언트가 시간이 지남에 따라 급격히 변하기 때문입니다.
내 모델의 적대적 검증이 항상 거의 auc = 1이라는 것이 가장 우려되었지만, 당신은 저에게 진실을 가르쳐주었습니다.
그리고 귀하의 솔루션에 대한 한 가지 질문이 있다. 과적한 부분에서 당신이 말한,
new_features = $ df.groupby('uid')[CM_columns].agg(['mean']) $
그러나 내가 아는 것처럼 M 기능은 범주 기능입니다. M 기능에 대한 집계 그룹 통계는 어떻게 얻었습니까?
A. Thank you. Columns M1 thru M9 excluding M4 are boolean, so first we map them to{'T':1,'F':0}. Then averaging makes sense. For column M4, we map{'M0':0,'M1':1,'M2':2}and hope the average makes sense :-) NANs are excluded from means.
감사합니다. M4를 제외한 M9에서 M9까지의 열은 부울이므로 먼저 { 'T': 1, 'F': 0}에 맵핑합니다. 그러면 평균화가 의미가 있습니다. M4 열의 경우 { 'M0': 0, 'M1': 1, 'M2': 2}를 매핑하고 평균이 의미가 있음을 희망합니다. :-) NAN이 평균에서 제외됩니다.
(아자르 - 크리스 대화)
Q. Thanks Chris, great job!
I will share today, did you also find groups by id19+id20?
Groups that span across multiple cards, and share the same D8 date.
고마워 크리스, 잘 했어!
오늘 공유하겠습니다. id19 + id20의 그룹도 찾으셨습니까?
여러 카드에 걸쳐 있고 동일한 D8 날짜를 공유하는 그룹입니다.
A. Thanks Amir and congrats on your strong Silver finish. I was not aware ofid_19andid_20. I'm eager to read how you found clients and did your post process that you describedhere. That post says that you found a way to increase LB by 0.006, that's amazing. We also had a post process that could raise our high score 0.001 more (and raise weaker models by a greater amount).
감사합니다 아미르와 강한 실버 마감을 축하합니다. id_19 와 id_20을 몰랐습니다. 나는 당신이 어떻게 클라이언트를 찾았고 당신이 설명한 사후 프로세스를 읽길 간절히 바라고 있습니다 (https://www.kaggle.com/c/ieee-fraud-detection/discussion/109455). 그 게시물에 따르면 LB를 0.006 증가시키는 방법을 찾았습니다. 우리는 또한 높은 점수를 0.001 더 올릴 수있는 후 처리 과정을 가졌습니다 (그리고 약한 모델은 더 많이 증가시킵니다).
Q. Hi Chris, Thanks although i was really hoping for my first gold.
The post process was nothing fancy, simply putting 1s for customers we know are fraud from train set.
This was later irrelevant once we implemented the information into the model.
I'll post later today.
Thanks!
안녕 크리스, 정말 내 첫 금을 바라고 있었지만 감사합니다. 포스트 프로세스는 환상적이지 않았으며, 단순히 기차 세트에서 사기를당하는 고객을 위해 1을 넣었습니다. 정보를 모델에 구현 한 후에는 나중에 관련이 없었습니다. 오늘 나중에 게시하겠습니다. 감사!
A. Our post process was a little different. We tried yours, but with our models, we got a higher score by not replacing by 1s. Instead, given a specific UID, we would take the average of that UIDsisFraudfrom train and predictions from test. Then we would replace all prediction with that average.
우리의 사후 프로세스는 약간 달랐습니다. 우리는 당신을 시도했지만, 우리의 모델에서는 1로 대체하지 않음으로써 더 높은 점수를 얻었습니다. 대신, 특정 UID가 주어지면, 우리는 UIDsisFraud의 평균을 기차에서 가져오고 테스트에서 예측합니다. 그런 다음 모든 예측을 해당 평균으로 바꿉니다.
Q. Congratulations to you and@kyakovlevon the 1st place. How much did the post process boost your lb score ?
축하드립니다. @ kyakovlevon 1 위. 포스트 프로세스가 파운드 점수를 얼마나 높였습니까?
A. Our best submission of Public LB 0.9677 is 0.9672 without post process. It's private changes from 0.9459 to 0.9454. So it boosted our best by 0.0005. Sometimes it does more. We have another submission that was 0.9664 which got boosted to 0.9674, so that was 0.0010. And it boosted my XGB from LB 0.9602 to LB 0.9618.
공개 LB 0.9677의 최선의 제출은 사후 프로세스없이 0.9672입니다. 비공개 변경은 0.9459에서 0.9454로 변경되었습니다. 따라서 0.0005로 최고를 향상 시켰습니다. 때로는 더 많은 일을합니다. 우리는 0.9664로 0.9674로 승격 된 또 다른 제출물을 가지고 있는데, 이것은 0.0010입니다. 그리고 그것은 XGB를 LB 0.9602에서 LB 0.9618로 향상 시켰습니다.
EDA
이 대회에서 가장 어려운 점 중 하나는 EDA 였다. 많은 변수가 존재하고 의미 또한 숨겨져 있었다. 첫번째 150개의 변수들에 대해 Alijs's가 좋은 EDA를 해주었고, 남은 300개의 변수들에 대해서 다음의 커널에 작업한 내용이 있다. 우리는 V의 수를 줄이기 위해서 3가지 트릭을 사용했다. 비슷한 NAN구조로 V의 그룹을 발견하고, 3가지 방법을 사용했다
- 각각의 그룹에 PCA 적용
- 각각의 그룹으로부터 상관성이 없는 변수들의 가장 길이가 긴 subset을 추출
- 전체 그룹을 모든 변수들의 평균으로 대체
후에, 아래에 적힌 변수선택 기법으로 위의 변수들을 제거했다. 예를들어, v322-v339는 time consistency에 의해서 제거했다.
Q, @cdeotte,@kyakovlev, Congratulations! and thanks for sharing your insights and your approach.
I have 2 quick questions if you get a chance to answer.
I tried creating UIDs but mine did not involve D1 and I was not confident of my UIDs being right. I would love to understand your approach for creating the UIDs.
1) How did you identify the meanings ofD1 and D3?
2) How were you sure"card1, addr1, and D1"were enough for the UID (how did you validate that)?
Many Thanks!
@ cdeotte, @ kyakovlev, 축하합니다! 통찰력과 접근 방식을 공유해 주셔서 감사합니다. 대답 할 기회가 있다면 두 가지 간단한 질문이 있습니다. UID를 만들려고했지만 D1과 관련이 없으며 UID가 올바른지 확신하지 못했습니다. UID를 만드는 방법을 이해하고 싶습니다.
1) D1과 D3의 의미를 어떻게 식별 했습니까?
2) "card1, addr1 및 D1"이 UID에 대해 얼마나 확신 했습니까 (어떻게 확인 했습니까)? 많
은 감사합니다!
A. https://www.kaggle.com/kyakovlev/ieee-uid-detection-v6
이것은 "순수한"ID 접근입니다
https://www.kaggle.com/kyakovlev/ieee-basic-fe-part-1
일반 ID의 블록 11
A.
How were you sure "card1, addr1, and D1" were enough for the UID (how did you validate that)?
We perform "purity tests". The purpose of UIDs is the divide the dataset into groups that are either allisFraud=0orisFraud=1so that we can easily classify transactions. After creating a new UID, computedf.groupby('uid').isFraud.agg(['mean'])and check the ratio of pure versus unpure groups.
「순도 테스트」를 실시합니다. UID의 목적은 데이터 세트를 모두 isFraud = 0 또는 isFraud = 1 인 그룹으로 나누므로 트랜잭션을 쉽게 분류 할 수 있습니다. 새 UID를 생성 한 후 computedf.groupby ( 'uid'). isFraud.agg ([ 'mean']) 및 순수 그룹과 불순 그룹의 비율을 확인하십시오.
Feature Selection
변수 선택은 매우 중요헀다. 왜냐하면 우리는 많은 변수들을 가지고 있었고 모델을 효율적으로 사용하기 위해서다. 우리의 xgb는 250개의 변수들을 가지고 6개의 폴드로 10분의 시간이 걸렸다 Konstantin will need to say what his models had (무슨말인지 모르겠어요). 우리는 변수를 선택하기위해 우리가 알고 있는 모든 트릭을 사용했다.
- forward feature selection (using single or groups of features)
- recursive feature elimination (using single or groups of features)
- permutation importance
- adversarial validation
- correlation analysis
- time consistency
- client consistency
- train/test distribution analysis
하나의 흥미로운 트릭인 "time consistency"는 싱글모델을 single feature (or small group of features)로 첫번째달로 마지막달을 예측한 것이다. 이러한 방법은 변수 그자체가 시간에 일관성있는지 검증하였고 우리는 5%정도의 성능이 나쁜 변수들을 발견할 수 있게 해주었다. 학습시 AUC가 0.6이고 검증시는 0.4이었다. 즉, 몇몇 변수들은 현재에서 패턴을 발견하고 이러한 패턴은 미래에는 나타나지 않는다. 물론 상호작용의 복장성의 가능성이 있다. 하지만 우리는 모든 테스트와 다른 테스트들에 대해 두번 검증했다.
time consistency code
# ADD MONTH FEATURE
import datetime
START_DATE = datetime.datetime.strptime('2017-11-30', '%Y-%m-%d')
train['DT_M'] = train['TransactionDT'].apply(lambda x: (START_DATE + datetime.timedelta(seconds = x)))
train['DT_M'] = (train['DT_M'].dt.year-2017)*12 + train['DT_M'].dt.month
# SPLIT DATA INTO FIRST MONTH AND LAST MONTH
train = train[train.DT_M==12].copy()
validate = train[train.DT_M==17].copy()
# TRAIN AND VALIDATE
lgbm = lgb.LGBMClassifier(n_estimators=500, objective='binary',
num_leaves=8, learning_rate=0.02)
h = lgbm.fit(train[[col]], train.isFraud, eval_metric='auc',
eval_set=[(train[[col]],train.isFraud),(validate[[col]],validate.isFraud)])
auc_train = np.round(h._best_score['valid_0']['auc'],4)
auc_val = np.round(h._best_score['valid_1']['auc'],4)Run this with variable col equal to the column you wish to test. Here are some results. Variable C3 hasauc_train = 0.5andauc_val = 0.5. Variable C7 hasauc_train = 0.65andauc_val = 0.67. And Variableid_38hasauc_train = 0.61andauc_val = 0.36. The next step is to remove weak variables from your model and then evaluate your entire model with your normal local validation to see if AUC increases or decreases. Using this, we found and removed 19 features and resultantly improved our model.
테스트하려는 열과 동일한 변수로 이것을 실행하십시오. 결과는 다음과 같습니다. 변수 C3 has auc_train = 0.5 and auc_val = 0.5. 변수 C7 has auc_train = 0.65 and auc_val = 0.67. 그리고 변수 id_38 has auc_train = 0.61 and auc_val = 0.36입니다. 다음 단계는 모델에서 약한 변수를 제거한 다음 일반적인 로컬 검증을 통해 전체 모델을 평가하여 AUC가 증가 또는 감소하는지 확인하는 것입니다. 이를 사용하여 19 개의 기능을 찾아 제거하고 결과적으로 모델을 개선했습니다.
-> auc_train과 auc_val이 다른 것을 찾은 다음에 지우고 로컬 검증에서 전체모델을 평가했다는 의미인가?
Q. Can you tell me more about "client consistency" and "train/test distribution consistency"?
A. "train/test distribution consistency" is comparing the distribution (histogram) of a feature in the training set with its distribution (histogram) in the test set. For example TransactionDT has low values in train and high values in test. And the values do not overlap. This feature is bad (obviously) so we drop it. You can either inspect features manually or use a library like from scipy.stats import ks_2samp. Documentation here, drop features with p=0.
"client consistency" is similar to "time consistency". Split your train dataset by UIDs. Put 80% of UIDs (clients i.e. credit cards) into a train subset and 20% UIDs into a holdout (validation set). Make sure that no UID (client/credit card) is in both sets. Then train models on the 80% train and predict the 20% unseen clients. This evaluates how well features can predict unseen clients (credit cards).
"클라이언트 일관성"및 "트레이닝 / 테스트 배포 일관성"에 대해 더 자세히 말씀해 주시겠습니까?
"트레인 / 테스트 분포 일관성"은 학습 세트의 기능 분포 (히스토그램)와 테스트 세트의 분포 (히스토그램)를 비교합니다. 예를 들어 TransactionDT는 트레인에서 값이 낮고 테스트에서 값이 높습니다. 그리고 값이 겹치지 않습니다. 이 기능은 (분명히) 나쁘므로 삭제합니다. 기능을 수동으로 검사하거나 scipy.stats import ks_2samp와 같은 라이브러리를 사용할 수 있습니다. 여기에 문서가 있고 p = 0으로 기능을 삭제하십시오. "클라이언트 일관성"은 "시간 일관성"과 유사합니다. UID로 트레인 데이터 세트를 분할하십시오. UID (클라이언트, 즉 신용 카드)의 80 %를 트레인 하위 세트에, 20 % UID를 Holdout (검증 세트)에 넣습니다. 두 세트 모두에 UID (클라이언트 / 신용 카드)가 없는지 확인하십시오. 그런 다음 80 % 열차에서 모델을 훈련시키고 보이지 않는 20 % 고객을 예측하십시오. 이 기능은 보이지 않는 클라이언트 (신용 카드)를 예측할 수 있는 기능을 평가합니다.
Q. Hi Chris,
Thanks a lot!
I simply can't get my head around why the M means and D means\Std by card-addr combination works.
as a data analyst (not a data scientist) i'm used to having accurate data, so i went onwards with a very strict script to capture highest accuracy information.
but using these features in the model , which are quite simple - you say the model manages to do it by itself,
could you please explain why it works?
also -
you mentioned that we don't have fraud information about users that are only in the future, do you think that these features generalize well to unseen users?
meaning - the mean(Ms) mean(Ds) etc. they have a pattern that predicts fraud in unknown customers?
크리스 안녕하세요 고마워요! 왜 card와 addr의 조합에 의한 M 평균와 D 평균, 편차가 잘 작동하는지에 대해 모르겠습니다.
데이터 과학자가 아닌 데이터 분석가로서 나는 정확한 데이터를 가지고 있었기 때문에 매우 정확한 스크립트를 사용하여 최고의 정확도 정보를 수집했습니다. 그러나 모델에서 이러한 기능을 사용하는 것은 매우 간단합니다. 모델이 자체적으로 관리한다고 말합니다. 왜 작동하는지 설명해 주시겠습니까?
또한- 미래에 있는 사용자에 대한 사기 정보가 없다고 언급했습니다. 이러한 기능이 보이지 않는 사용자에게 일반화되었다고 생각하십니까? 의미-평균 (Ms) 평균 (Ds) 등 그들은 알 수없는 고객의 사기를 예측하는 패턴을 가지고 있습니까?
A. We need to pass some information about client to model. But we can't say X is a client. We have to say someone with hight 170sm and weight 120kg - model will be forced to search hidden patterns and connections. M/D mean encoding is doing it - describing client for the model in some general way.
클라이언트에 대한 정보를 모델로 전달해야합니다. 그러나 우리는 X가 클라이언트라고 말할 수 없습니다. 우리는 높이 170sm과 무게 120kg을 가진 사람을 말해야합니다-모델은 숨겨진 패턴과 연결을 검색해야합니다. M / D는 인코딩이 수행하고 있음을 의미합니다. 일반적인 방식으로 모델의 클라이언트를 설명합니다.
A. Great questions. Let me share my opinions. Doing group aggregations with standard deviations (specifically of normalized D columns) allows your model to find clients. And doing group aggregation with means (and/or std) allows your model to classify clients. Let me explain.
좋은 질문입니다. 내 의견을 공유하겠습니다. 표준 편차 (특히 정규화 된 D 열)로 그룹 집계를 수행하면 모델이 클라이언트를 찾을 수 있습니다. 그리고 수단 (및 / 또는 표준)을 사용하여 그룹 집계를 수행하면 모델이 클라이언트를 분류 할 수 있습니다. 설명하겠습니다.
Consider a group that all have the same uid = card1_addr1_D1n where D1n = day - D1. This group may contain multiple clients (credit cards). The features D4n, D10n, and D15n are more specific than D1n and better at finding individual clients. Therefore many times a group of card1_addr1_D1n will have more than 1 unique value of D15n inside suggesting multiple clients. But some groups have only 1 unique value of D15n inside suggesting a single client. When you do df.groupby('uid').D15n.agg(['std']) you are will get std=0 if there is only one D15n inside and your model will be more confident that thatuidis a single client (credit card).
모두 동일한 uid = card1_addr1_D1n을 갖는 그룹을 고려하십시오. 여기서 D1n = day-D1입니다. 이 그룹에는 여러 고객 (신용 카드)이 포함될 수 있습니다. D4n, D10n 및 D15n 기능은 D1n보다 더 구체적이며 개별 클라이언트를 찾는 데 더 좋습니다. 따라서 card1_addr1_D1n 그룹은 여러 클라이언트를 제안하는 내부에서 D15n의 고유 값이 두 개 이상인 경우가 많습니다. 그러나 일부 그룹에는 단일 클라이언트를 제안하는 D15n의 고유 한 값이 1 개만 있습니다. df.groupby ( 'uid'). D15n.agg ([ 'std'])를 수행 할 때 내부에 D15n이 하나만 있으면 std = 0이되고 모델은 해당 클라이언트가 단일 클라이언트 (신용 카드).
The M columns are very predictive features. For example if you train a model on the first month of data from train using just M4 it will reach train AUC = 0.7 and it can predict the last month of train with AUC = 0.7. So when you use df.groupby('uid').M4.agg(['mean']) after (mapping M4 categories to integers), it allows your model to use this feature to classify clients. Now all uids with M4_mean = 2 will be split one way in your tree and all with M4_mean = 0 another way.
M 열은 매우 예측적인 기능입니다. 예를 들어 M4 만 사용하여 열차의 첫 달 데이터에서 모델을 훈련하면 AUC = 0.7 열차에 도달하고 AUC = 0.7 인 열차의 마지막 달을 예측할 수 있습니다. 따라서 M4 범주를 정수로 매핑한 후 df.groupby ( 'uid'). M4.agg ([ 'mean'])를 사용합니다. 모델에서 이 기능을 사용하여 클라이언트를 분류 할 수 있습니다. 이제 M4_mean = 2 인 모든 uid는 트리에서 한 방향으로 나눠지고 M4_mean = 0 인 다른 방법으로 나뉩니다.
Q. Congratulation to @cdeotte for the winning the first place. Really appreciate that you are willing to share your concept and solution. I am honored to have the opportunity to learn from the masters & grandmasters in the Kaggle community.
1 위를 차지한 @cdeotte에게 축하를 전합니다. 개념과 솔루션을 기꺼이 공유해 주셔서 감사합니다. Kaggle 커뮤니티의 마스터 및 그랜드 마스터로부터 배울 수있는 기회를 갖게되어 영광입니다.
I have a question (apologize first if it is too fundamental). How do you tell/differentiate the public test and private test? Is it through some form of probing? Thank you very much.
질문이 있습니다 (너무 근본적인 경우 먼저 사과하십시오). 공개 테스트와 개인 테스트를 어떻게 구별 / 차별합니까? 어떤 형태의 조사를 통해서인가? 대단히 감사합니다.
A. The competition says that the public test is 20% of the full test dataset. Since the data is ordered in time, we suspect that the public test is the first 20% of rows. We confirmed this by taking a solution with known public LB score and changing all the predictions in the last 80% rows to zero. When we submitted the modified file, the public LB score did not change. (Furthermore, Kaggle confirmed that the public test is the first 20% here).
경쟁사는 공개 테스트가 전체 테스트 데이터 세트의 20 %라고 말합니다. 데이터가 제 시간에 정렬되므로 공개 테스트가 행의 처음 20 % 인 것으로 의심됩니다. 우리는 알려진 공개 LB 점수를 가진 솔루션을 취하고 마지막 80 % 행의 모든 예측을 0으로 변경하여이를 확인했습니다. 수정 된 파일을 제출해도 공개 LB 점수는 변경되지 않았습니다. 또한 Kaggle은 공개 테스트가 여기에서 처음 20 %임을 확인했습니다.
Validation Strategy
우리는 단일한 검증 전략을 신뢰하지 않았고 여러가지의 검증방법을 사용했다. 첫번쨰 4달로 트레인하고 한달뛰고 마지막달을 예측하는 방법, 2달 학습 2달뛰도 2달 예측하는 방법. 1달 학습하고 4달 뛰고 마지막 예측하는 방법. 우리는 LB를 보며 점수를 확인했다. 우리는 GROUPKFOLD를 달로 사용했다. 우리는 또한 KNOWN UID와 UNKNOWN UID를 잘 분류하는 지 검증하였다.
For example when training on the first 5 months and predicting the last month, we found that our
- XGB model did best predicting known UIDs with AUC = 0.99723
- LGBM model did best predicting unknown UIDs with AUC = 0.92117
- CAT model did best predicting questionable UIDs with AUC = 0.98834
Questionable한 uid는 자신있게 분류하지 못한 거래들이다. 우리는 모델들을 앙상블했고 3가지 경우에 대해 잘 분류하는 것을 확인했다. 알려지고, 알려지지 않은, 의심스러운 3가지 유형의 UID를 정확한 시간 내에 예측할 수 있습니다. 내 로컬 유효성 검사 체계는 처음 75 % 행에서 모델을 학습하고 마지막 25 % 행을 예측합니다. (이것은 대략 4.5 개월 트레인이며 마지막 1.5 개월을 예측합니다). Konstantin은 처음 4 개월 동안 트렌으로 사용하고 1 개월을 건너 뛰고 마지막 달을 예측했습니다.
When I engineer a new feature (or group of features), I evaluate whether it (they) increased this local validation AUC. Other tests like train.csv/test.csv distribution, time consistency, correlation redundancy would indicate possible "bad" features. I would then remove these features and evaluate whether local validation AUC increased or decreased.
When local validation AUC increased, the Group k Fold CV AUC usually increased too. When they did not agree, I trusted local holdout AUC more because it was a forward in time prediction whereas Group K Fold CV includes some backwards in time folds.
새 기능 (또는 기능 그룹)을 엔지니어링 할 때 이 로컬 유효성 검사 AUC가 증가했는지 평가합니다. train.csv / test.csv 분포, 시간 일관성, 상관 중복과 같은 다른 테스트는 가능한 "나쁜"기능을 나타냅니다. 그런 다음 이러한 기능을 제거하고 로컬 유효성 검사 AUC가 증가했는지 감소하는지 평가합니다. 로컬 유효성 검사 AUC가 증가하면 일반적으로 Group k Fold CV AUC도 증가했습니다. 그들이 동의하지 않을 때, 현지 홀드 아웃 AUC는 시간 예측에서 앞선 예측 이었기 때문에 AUC를 더 신뢰할 수 있었지만 그룹 K 폴드 CV는 약간의 시간 역전을 포함했습니다.
Post Processing
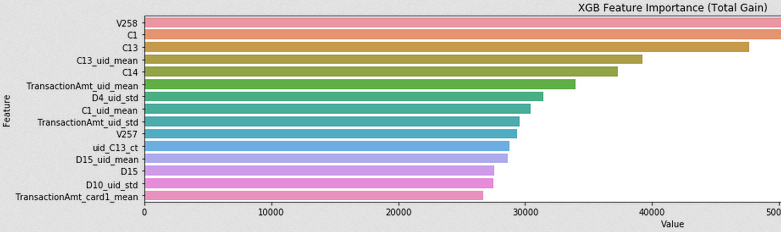
Feature Importance
Both types are useful to review. "split" refers to quantity and "gain" refers to quality. LGBM is lots of trees and trees are lots of nodes with splits. The importance type "split" refers to how often a feature is used to make splits and "gain" refers to how beneficial splits are when they occur. Note that regarding "gain", you can use "average gain" or "total gain" where average is "average per split" and total is "total over all splits". Gain is a measure of the model becoming more accurate. Every time a tree makes a split the model will always increase or stay at the same accuracy. (The bottom plot below is "split" and the image is cropped so we can read the feature names).
두 유형 모두 검토에 유용합니다. "분할"은 수량을 의미하고 "게인"은 품질을 의미합니다. LGBM은 많은 나무이고 나무는 많은 노드로 나뉘어져 있습니다. 중요도 유형 "분할"은 피쳐가 분할을 수행하는 데 사용되는 빈도를 나타내며 "게인"은 분할이 발생할 때 얼마나 유익한지를 나타냅니다. "게인"과 관련하여 "평균 게인"또는 "총 게인"을 사용할 수 있습니다. 여기서 평균은 "스플릿 당 평균"이고 총계는 "모든 스플릿의 총계"입니다. 게인은 모델이 더 정확 해지는 척도입니다. 나무가 분할 될 때마다 모델은 항상 동일한 정확도로 증가하거나 유지됩니다. (아래의 줄거리는 "분할"이고 이미지가 잘려서 피쳐 이름을 읽을 수 있습니다).


'EDA Study > 캐글' 카테고리의 다른 글
| Chris의 Feature Engineering 팁 (0) | 2019.09.12 |
|---|---|
| Winning Tips on Machine Learning Competitions by Kazanova, Current Kaggle #3 (2) | 2019.09.11 |
| Elo Merchant Category Recommendation - Help understand customer loyalty (0) | 2019.03.02 |
