
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 큐
- hackerrank
- pytorch
- Recsys-KR
- 3줄 논문
- 입문
- Segmentation
- 추천시스템
- 코딩테스트
- DFS
- DilatedNet
- 한빛미디어
- 나는리뷰어다
- MySQL
- Python
- Object Detection
- TEAM-EDA
- 스택
- Semantic Segmentation
- Machine Learning Advanced
- eda
- 튜토리얼
- 나는 리뷰어다
- 알고리즘
- Image Segmentation
- TEAM EDA
- 협업필터링
- 프로그래머스
- 엘리스
- 파이썬
- Today
- Total
TEAM EDA
브런치 사용자를 위한 글 추천 대회 - 데이터 탐색(1) 본문
브런치 사용자를 위한 글 추천 대회
brunch 데이터를 활용해 사용자의 취향에 맞는 글을 예측하는 대회
아래의 분석자료는 제가 대회를 진행하면서 어떤 순서대로 분석을 진행하고, 어떤 고민을 했는지 정리해놓은 분석자료입니다. 한달이라는 대회 진행과정의 모든것을 적으려고 노력했기에 카카오측에서 제공한 분석자료의 내용도 들어가 있고, 다른 참고자료의 내용들도 많이 들어있습니다. 분석의 진행 과정은 아래와 같습니다.
-
기존에 카카오측에서 제공한 분석자료 읽으면서 자신만의 관점으로 해석하기.
-
추천시스템과 관련된 참고자료를 정리.
-
도메인 분석.
-
1, 2를 바탕으로 EDA와 베이스라인 잡기.
-
모델 개선.
0. Overview
먼저 대회를 진행하기에 앞서서 Overview부분을 꼼꼼하게 읽으면서 주최측의 목적, 주의해야할 점 등을 살펴봤습니다. 아래의 내용은 주최측에서 작성한 대회개요 부분입니다.
목적. brunch 데이터를 활용해 사용자의 취향에 맞는 글을 예측할 수 있을까?
다양한 미디어 매체를 통해 콘텐츠의 가치가 나날이 높아지고 있습니다. 양질의 콘텐츠가 늘어남에 따라 손쉽고 편하게 나에게 맞는 콘텐츠를 추천받길 원하는 사용자도 늘어나고 있습니다. 그만큼 추천을 통해 글이 가치 있게 읽히는 경험은 창작자에게도, 독자에게도 매우 중요한 일입니다. 브런치 역시 매번 더 나은 해결책을 고민하고 있습니다. 브런치에 담긴 아름다운 글을 원하는 독자가 충분히 감상할 수 있도록 추천을 통해 잘 연결해주세요. 이번 대회는 보다 정밀하게 사용자 개개인이 좋아할 만한 글을 예측하는 것이 목표입니다. 사용자의 과거 활동 정보를 기반으로 취향을 분석하고 모델링하여 미래 소비 결과를 예측해보는 실험입니다. 이 대회를 통해 다루게 될 데이터 구성은 아래와 같습니다.
-
콘텐츠
-
작가/독자 정보
-
행태 정보
대회 참가자는 주어진 데이터로 사용자의 취향 저격 글을 예측하고 그 결과를 제출하여 성능을 확인해볼 수 있습니다. 카카오 아레나에서 세상을 즐겁게 변화시킬 기회에 도전하세요.
평가함수
제출형식
-
User_id(김현우) @wo-motivator133(작품1) @wo-motivator134(작품2) … @wo-motivator*233(작품100)
가장 주의깊게 살펴본 것은 평가함수가 3개로 주어지고 최종 순위는 Borda Count로 매겨지는 점입니다. 각각의 함수가 어떻게 평가되는지 알기 위해, 평가함수의 설명과 evaluate.py를 참고하면서 평가함수에 대한 이해부터 시작했습니다.
1. What is the data ?
저희가 가진 데이터의 구성은 콘텐츠, 작가/독자정보, 행태 정보이고, 각각의 파일들은 어떤 변수를 가지고 있는지 읽어보고 스키마 구조를 만들어서 각각 어떻게 연관이 있는지 살펴봤습니다. 아래는 실제로 대회를 진행하면서 만들었던 스키마파일입니다.

여기서 주의해야 할 점은 이름이 동일한 식별자가 사실 다른 의미라는 점입니다.
read
-
2018년 10월 1일부터 2019년 3월 1일까지 일부 브런치 독자들이 본 글의 정보가 총 3,625개의 파일로 구성되어 있습니다.
-
파일의 이름은
시작일_종료일형태입니다. 예를 들어2018110708_2018110709파일은 2018년 11월 7일 오전 8시부터 2018년 11월 7일 오전 9시 전까지 본 글입니다. -
파일은 여러 줄로 이뤄져 있으며 하나의 줄은 브런치의 독자가 파일의 시간 동안 본 글을 시간 순으로 기록한 것입니다. 한 줄의 정보는 공백으로 구분되어 있으며 첫번 째가 독자의 암호화된 식별자이고 그 뒤로는 해당 독자가 본 글의 정보입니다.
-
예를 들어
read/2019022823_2019030100파일에 기록된 아래 정보는#8a706ac921a11004bab941d22323efab라는 독자가 2019년 2월 28일 23시에서 2019년 3월 1일 0시 사이에@bakchacruz_34 @wo-motivator_133 @wo-motivator_133를 순서대로 보았다는 뜻입니다.@wo-motivator_133글이 두 번 나타난 것은 이 글을 보기 위해 두 번 방문했다는 뜻입니다. -
#8a706ac921a11004bab941d22323efab @bakchacruz_34 @wo-motivator_133 @wo-motivator_133
-
-
글을 보았다는 의미는 특정 글에 모바일, PC, 앱을 통해 접근했다는 뜻입니다. 머문 시간에 대한 정보가 제공되지 않기 때문에 실제로 글을 읽지 않고 이탈하는 등의 가능성도 있습니다.
metadata
-
643,104 줄로 구성된 글의 메타데이터입니다.
-
이 메타데이터에는 2018년 10월 1일부터 2019년 3월 14일까지 독자들이 본 글에 대한 정보입니다.
-
작가가 비공개로 전환하였거나 삭제 등의 이유로 학습 데이터로 제공된 2018년 10월 1일부터 2019년 3월 1일 전까지의 본 글 정보에는 이 메타데이터에 없는 글이 있을 수 있습니다.
-
개발 데이터와 평가 데이터에 포함된 글의 메타데이터도 포함되어 있습니다. 즉, 평가 대상자들이 2019년 3월 1일부터 2019년 3월 14일 사이에 본 모든 글에 대한 정보가 포함되어 있습니다.
-
-
필드 설명
-
magazine_id: 이 글의 브런치 매거진 아이디 (없을 시는 0)
-
reg_ts: 이 글이 등록된 시간(유닉스 시간, 밀리초)
-
user_id: 작가 아이디
-
article_id: 글 번호
-
id: 글 식별자
-
title: 제목
-
sub_title: 부제목
-
display_url: 웹 주소
-
keyword_list: 작가가 부여한 글의 태그 정보
-
-
메타데이터의 모든 정보는 작가의 비공개 여부 전환, 글 삭제, 수정 등으로 유효하지 않거나 변동될 수 있습니다.
contents
-
저작권을 보호하고자 본문에서 형태소 분석을 통해 추출된 정보를 암호화하여 제공합니다. 총 7개의 파일로 나뉘어있습니다.
-
형태소 분석기는 카카오에서 공개한 khaiii 의 기본 옵션을 사용했습니다. 형태소 분석 결과의 어휘 정보는 임의의 숫자로 1:1 변환되었습니다. 동일 어휘의 경우, 품사와 관계없이 같은 숫자로 변환됩니다.
-
형태소 분석에 대한 설명과 품사의 의미에 대해서는 별도 제공하지 않습니다.
-
형태소 추출 전에 텍스트를 제외한 HTML과 같은 내용과 관계없는 정보는 제거 했으나 일부 정보가 남았을 수 있습니다.
-
필드 설명
-
id: 글 식별자
-
morphs: 형태소 분석 결과
-
리스트의 리스트로 구성되며, 리스트의 첫 번째 요소는 첫 어절의 분석 결과입니다.
-
어휘와 품사는 / 구분자로 구분됩니다.
-
예를 들어 "안녕하세요 브런치입니다"라는 문장은 khaiii 형태소분석기에서 "안녕/NNG + 하/XSA + 시/EP + 어요/EF", "브런치/NNP + 이/VCP + ㅂ니다/EC" 라고 분석되는데, 이 결과는 morphs에서 다음처럼 나타날 수 있습니다. [["8/NNG", "13/XSA", "81/EP", "888/EF"], ["0/NNP", "12913/VCP", "29/EC"]]
-
여러 줄에 걸친 결과는 개행 구분 없이 리스트에 연속적으로 등장합니다. 예를 들어 "안녕하세요 브런치입니다\n안녕하세요"의 결과는 다음과 같습니다. [["8/NNG", "13/XSA", "81/EP", "888/EF"], ["0/NNP", "12913/VCP", "29/EC"], ["8/NNG", "13/XSA", "81/EP", "888/EF"]]
-
-
chars: 형태소 분석 결과
-
형태소 분석 결과에서 어휘 부분을 문자 단위로 암호화환 결과입니다.
-
한 어휘의 문자는 + 구분자로 결합합니다. 예를 들어 위 예의 "브런치입니다"는 chars 필드에서 다음처럼 나타날 수 있습니다. "0+1+2/NNP", "4/VCP", "9+29+33/EC"
-
-
-
metadata.json과 마찬가지로 개발 데이터와 평가 데이터의 글 본문도 포함되어 있습니다.
-
contents 정보는 본문이 없는 글의 경우 제공되지 않을 수 있습니다.
users
-
가입한 사용자(작가 혹은 독자)의 정보입니다.
-
필드 설명
-
keyword_list: 최근 며칠간 작가 글로 유입되었던 검색 키워드
-
following_list: 구독 중인 작가 리스트
-
id: 사용자 식별자
-
-
총 310,758명의 정보가 있습니다. 탈퇴 등의 이유로 사용자 정보가 없을 수 있습니다.
magazine
-
총 27,967개의 브런치 매거진 정보입니다.
-
필드 설명
-
id: 매거진 식별자
-
magazine_tag_list: 작가가 부여한 매거진의 태그 정보
-
predict 디렉토리: 예측할 사용자 정보
-
dev.users: 개발 데이터입니다. 대회 기간에 예측한 성능을 평가하기 위해 제공한 사용자 3,000명 리스트입니다.
-
test.users: 평가 데이터입니다. 대회 종료 후 최종 순위를 결정하기 위해 제공한 사용자 5,000명의 리스트입니다.
-
일부 사용자는 2018년 10월 1일부터 2019년 3월 1일까지 본 글이 없을 수도 있습니다.
얻은 인사이트
-
개발 데이터와 평가 데이터에 포함된 글의 메타데이터도 포함되어 있습니다. 즉, 평가 대상자들이 2019년 3월 1일부터 2019년 3월 14일 사이에 본 모든 글에 대한 정보가 포함되어 있습니다.-
대우에 의해 위의 메타데이터에 없는 글은 읽지 않은 글이라는 것을 알 수 있습니다.
-
-
일부 사용자는 2018년 10월 1일부터 2019년 3월 1일까지 본 글이 없을 수도 있습니다.-
얼마나 자주 방문했는지에 따라 다른 모델이 필요하다. (처음 방문하는 사람/ 가끔 방문하는 사람 / 자주 방문하는 사람)
-
2. What is the Reference ?
데이터를 분석하기 앞서서 추천시스템과 관련된 Reference들을 읽어보고 기본적인 방법론을 익혔습니다.
-
관련대회
-
매거진
-
관련 커뮤니티
-
페이스북 : 추천시스템 연구소 (Recommender System Labs)
-
추천시스템 방법론
1) Rule-based Recommendation
2) User-based Recommendation
3) Contents-based Recommendation
4) Others
-
Deep learning for Recommendations
-
Machine learning for Recommendations
-
etc
참고자료 정리
브런치 데이터의 탐색과 시각화
카카오 아레나 2회 대회(Part.1) | 브런치 이용자의 취향을 분석하라 지난해 11월 개최된 카카오 아레나 1회 대회에 이어 카카오 아레나 2회 대회가 개최되었습니다. 첫 번째 대회는 쇼핑몰에 등록된 상품의 텍스트, 이미지 정보 등을 활용해 카테고리 분류의 정확도를 높이는 ‘쇼핑몰 상품 카테고리 분류’를 주제로 진행되었고, 다음(Daum) 쇼핑에 존재하는 수억 개의 상품을 더 정확하게 카테고리
brunch.co.kr
아래의 분석자료는 브런치 데이터의 탐색과 시각화의 분석내용을 토대로 우리가 적용해 볼 아이디어와 유의해야할 사항들을 중심으로 확인해보도록 하겠습니다. 그리고 이를 바탕으로 무엇을 탐색해볼 지 고민하겠습니다.
브런치에 등록된 글 현황

일자별 등록 글 추이를 보면 올라갔다가 내려가는 모습을 보이고, 몇몇 포인트에서는 눈에 띄게 글이 증가하는 모습을 보입니다. 주최측에 따르면 해당 일자는 `브런치북 프로젝트`기간의 참여 종료일이라고 합니다.
브런치북 프로젝트는 10인의 에디터가 10인의 작가를 선정하여 함께 10권의 책을 만드는 프로젝트로, 작가는 평소에 브런치북 태그가 있는 매거진*에 글을 15개 이상 적으면 완료됩니다. 그리고 수상작으로 선정되면 아래와 같이 책이 발간되는 형태입니다.

*매거진 : 매거진이란 브런치의 비슷한 주제로 작성된 글들이 모여 있는 공간으로, 혼자 작성할 수도 있지만 다른 작가들과 함께 채워나갈 수도 있는 공간입니다.
-
매거진을 통해서 소비자의 읽는 성향을 파악할 수도 있습니다.
-
평소에 A작가의 글을 보지 않지만, 내가 구독하는 B작가와 A작가가 매거진을 같이 한다면 매거진을 통해서 A작가의 글을 볼 수도 있습니다.
*브런치북 프로젝트 : 10인의 에디터가 10인의 작가를 선정하여 함께 10권의 책을 만드는 프로젝트
-
수십 ~ 수백명의 작가가 브런치북에 실릴 시리즈의 글을 작성하는 공간입니다.
-
시리즈의 글이기때문에 과거의 글을 읽었다면 3월 이후의 새로 발행되는 글도 읽을 가능성이 높습니다.
-
3월 4일의 경우, 대회 수상작이 발표되어서 수상작들의 소비가 당일에 증가했을 수 있습니다.
-
브런치 글의 소비 데이터 현황


-
개별 글보다는 매거진 글에서 소비수가 높다. (파란색 점이 매거진 글, 초록색 점이 개별 글)
-
추천을 할 때, 매거진 글을 우선적으로 추천하도록 설정.
-
-
18년 7월 30일부터 8월 12일까지 약 2주간 등록된 글들의 소비가 높다.
-
이유가 왜 그럴까? 데이터 탐색에서 살펴봐야 함.
-
-
18년도 8월이후로 전반적인 글의 소비수가 증가한다.
-
읽은 기간을 잡을때 최소한 18년도 8월을 기준으로 삼아야 함.
-

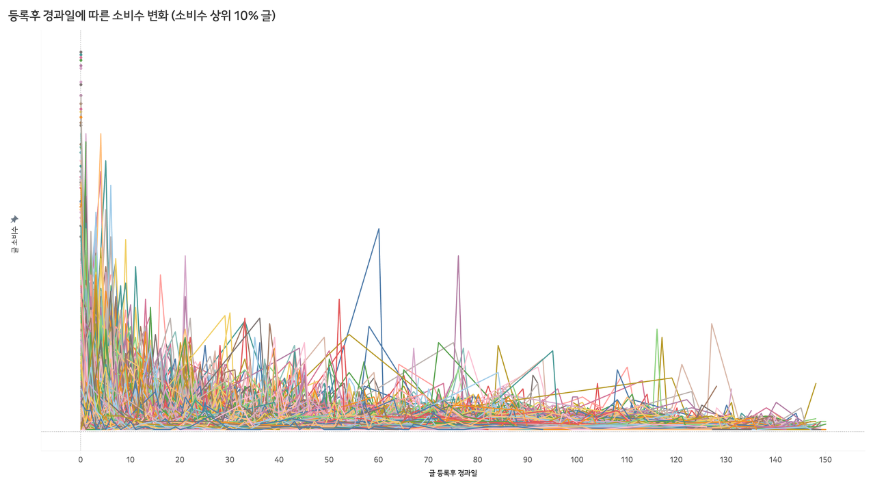


브런치팀에서 작성한 글을 모두 제외하고, 등록된 경과일에 따른 평균 소비수를 보면, 일주일 이내의 대 부분의 소비가 발생하는 편입니다. (58%)
-
브런치팀에서 작성한 글 (공지사항)은 어떤 패턴을 보이는지 데이터탐색에서 살펴봐야 함.
-
최근에 만들수록 또는 발행한지 며칠안되었을 수록 사람들이 읽을 확률이 높음.
-
중간중간 다른 유통채널에 브런치 글이 소개되어서 소비가 급증하기도 함.
-
유통데이터가 없어서 유통여부는 알 수 없지만, 실시간으로 소비가 급증하는 부분을 read데이터에서 뽑아야 함. (ex. 실시간 인기검색어)
-
[그림 6] 그래프를 유심히 살펴보면 10일 이후에서 부터 7일 간격으로 평균 글 소비수가 조금씩 증가하는 모습을 보입니다. 이러한 글은 위클리 매거진이라는 글의 종류때문에 발생합니다. 네이버 웹툰처럼 7일을 주기로 발행되는 글은 브런치팀이 엄선한 작가들에 한해서 매주 같은 요일에 글을 발행하는 매거진이라고 합니다.

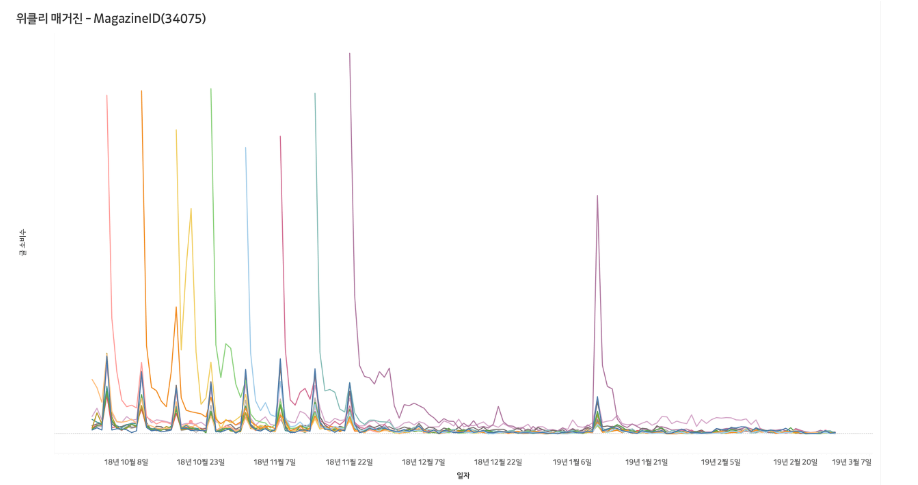

위의 그래프에서도 볼 수 있듯이 발행일에 글 소비가 가장 높게 나타나고, 덩달아 이전 글들의 소비도 함께 증가합니다. 신규 글 발행일에 이전 글들을 소비 수로 나열해보면 1화부터 순차적으로 정렬이 됩니다. 신규로 발행된 글을 읽은 유저가 만약 이전 글들을 읽지 않았다면 되돌아가 1화부터 순차적으로 글을 읽었을 것으로 생각할 수 있습니다.

-
위클리 매거진* : 1주일을 주기로 발행하는 매거진. 매거진과의 차이점은 위클리 매거진은 연재주기가 1주일로 정해져있고 그냥 매거진은 연재주기가 정해져있지 않음.
-
위클리 매거진과 그냥 매거진을 구분할 알고리즘을 생각해야 함
-
위클리 매거진의 소비패턴을 파악해서 추천알고리즘으로 만들어야 함.
-
사람들의 심리상 과거부터 읽어야 최신화가 나오면 최신화를 읽음. 첫화로 돌아가서 읽은 사람은 아마 신규유저이거나 기존의 진성유저일 가능성이 높음.
-
내용이 이어지는 특성상 중간에 빼먹고 읽었을 가능성은 낮을 것 같음. 중간에 빼먹은 내용이 있으면 추천하도록 설정.
-
-
브런치에서 어떻게 글을 추천하는지 방식에 설명한 글입니다. 사실 이번 대회는 추천시스템 대회이지만, 아래의 두가지 이유때문에 정확한 평가를 할 수가 없다고 생각합니다.
-
2월달의 임의의 read정보를 제거했음.
-
브런치에서 추천하는 결과를 통해서 사람들이 평소와 다른 혹은 자주 안본 작가의 글을 읽을 확률이 높음.
그렇기에, 점수를 잘 받으려면 브런치에서 어떻게 추천알고리즘을 만드는지 파악해서 비슷하게 만드는게 중요합니다.

UX 편향 없는 인기글을 수집하라
개인화 추천 서비스의 가장 큰 단점은 신규 유저에게 추천할 글이 없다는 점입니다. 이를 콜드 스타트(cold start)라고 하고 브런치에서는 이러한 문제를 해결하기 위해 UX 편향 없는 인기글 측정을 통해 CTR을 높이고 있습니다.
-
콜드 스타트 : 시스템이 아직 충분한 정보를 수집하지 않은 사용자 또는 항목에 대한 추론을 도출 할 수 없다는 문제
-
CTR : 브런치 글을 추천했을때, 사람들이 그 글을 클릭한 비율.

브런치에서는 개인의 과거 정보가 없는 1. 신규, 장기휴먼, 비로그인 유저나 글에 대해 사람들의 읽은 정보가 없는 2. 신규 글을 추천하기 위해서 차선책으로 인기글과 UX편향없는 인기글을 추천하고 신규글의 경우는 노출을 많이 시키는 방법을 선택합니다.
여기서 인기글이라는 것은 글의 총 소비수가 높은 글을 의미하고, UX편향없는 인기글이라는 것은 노출 횟수 대비 총 소비수가 높은 글을 의미합니다.
신규글의 경우는 브런치 홈, 카테고리에서 최신글 순서대로 나열 시킴으로써 사람들에게 노출을 많이 시키고 있습니다.

위의 [그림5]는 UX편향없는 인기글을 추천했을 때, 사람들의 반응을 본 자료입니다. 실제로 위의 결과만 보면 사람들의 반응이 2배가까이 좋았단 점을 알 수 있습니다. 위의 정보를 종합해서 정리해보면 아래와 같습니다.
-
인기글을 추천할 때, 편향이 없는 인기글을 추천하는게 더 좋음.
-
신규 글의 경우 UX노출이 매우 잘되어 있음.
하지만 위의 정보를 활용해서 모델을 만들려고 하기에는 문제가 있습니다. 편향을 제거할만한 마땅한 방법이 주어지지 않았기 때문입니다. 카카오 측에서는 UX노출이 얼마나 되었는지 정보를 알기때문에 이를 활용해서 편향을 제거했지만 저희는 UX노출 및 외부링크에 대한 자료가 없기 때문에 이를 알기가 힘듭니다. 그렇기에 저희 만의 방법으로 편향을 제거할 방법을 고민해야 합니다.
-
편향이 없다 : 꾸준히 소비가 높다. 재방문률이 높다. 다양한 사람들이 많이 읽는다. 크롤링을 통해서 댓글과 공유수를 긁어야 한다. 발행일 대비 소비수가 높다.
-
브런치에서는 신규글이 많이 노출되는 알고리즘이 설정되어 있음.
-
가중치 조건에서 신규성을 많이 활용해야 함. 다른글과 비교해서 신규글이 얼마나 노출되었는지, 사람들이 많이 읽는 시간대에 노출이 되었는지 등을 이용.
-
하지만 대회목적상 다른사람들이 읽었을 만한 글을 찾아야 하는게 목표인데 무작정으로 신규글이라고 추천하는 것은 정확도 면에서 떨어질 확률이 높음. 그리고 이를 정확히 활용하려면 사람들이 읽은 시간대에 가장 최근글을 찾아서 추천해야 함.
-
이 글과 비슷하고 잘 반응하는 글을 찾아라 (유사글 추천 모델)
추천 시스템에서 연관 추천은 추천 시스템의 대표적인 기능이자, 추천 적용 시 성과가 좋은 기능입니다. 브런치에서도 아래 그림처럼 현재 읽고 현재 글을 본 독자에게 추가적인 소비를 일으킬 수 있는 좋은 글을 추천하여 독자당 평균 소비 글 수와 소비되는 글의 다양성을 크게 개선하였습니다. 그럼 브런치에 적용된 유사글 추천 모델에 대해 자세히 알아보겠습니다.

유사글 추천은 유사한 글을 찾는 "글 특징 추출 모델"과 유사한 글 중에서 유저에게 반응이 좋은 글을 찾기 위한 "실시간 랭킹 최적화 모델"로 구성되어 있습니다.

토로스의 유사글을 찾기 위한 글 특징 추출은 CBF(contents based filtering) 모델과 CF(collaboration filtering)을 모두 사용하여 아래와 같은 다양한 특징 벡터를 추출합니다.


위 결과(그림)처럼 CBF-Text 모델의 경우 "아이. 놀이" 등의 주제어가 잘 맵핑된 글이 유사글로 선택됩니다. 이때 선택한 글의 읽을 수가 0건인 글도 다수 포함되어 있는 것을 확인할 수 있습니다. CF 모델의 대표적인 특징으로, CF모델은 인기가 있으면서도 유사한 글이 잘 선택됨을 볼 수 있습니다.
이렇게 선택된 유사글을 대상으로 실시간 랭킹 최적화(MAB)는 탐색(Exploration) 과정을 통해 CTR을 측정하며, CTR이 가장 높은 글을 선택하는 획득, 활용(Exploitation) 과정을 통해 몇 개의 글이 추천됩니다. 실시간 랭킹 최적화에 대한 자세한 설명은 토로스 추천 시스템에 대한 설명글(https://brunch.co.kr/@kakao-it/72)을 참고하시길 바랍니다.

-
반응이 좋은 글 찾기
-
"아이. 놀이" 등의 주제어가 잘 맵핑된 글
나를 위한 맞춤 추천(개인화 추천 모델)
브런치 앱의 첫 화면에는 최근에 내가 읽은 글을 이용해 나를 위한 맞춤 추천을 제공하고 있습니다. 아래 결과는 "데이터 분석, 개발, 추천기술" 글에 관심을 가지고 있는 사용자의 맞춤 추천 결과입니다.

브런치의 개인화 맞춤 추천은 유사글 추천과 같이 2단계의 과정을 거쳐 이루어집니다. 추천할만한 글을 선정하는 '타겟팅 단계', 내가 본 글을 기반으로 내가 좋아할 만한 글을 찾아내는 랭킹 단계입니다.

추천할만한 글을 찾는 타켓팅 조건은?
-
글의 정보로 예측된 CTR이 높은 글
-
위에서 언급한 UX 편향이 없는 인기글
-
통계분석에 의해 추천할만한 글
이러한 조건에 만족하는 글을 타겟팅 하게됩니다.
타겟팅에 사용되는 CTR 예측은 글의 CBF-CF 특징 값과 메타 정보(읽은 수, 공유수, 댓글 수 등)를 입력값으로 사용하여 CTR예측 모델(XGBoost Regression)을 통해 pCTR(predicted CTR)을 측정하고 pCTR이 높은 상위 글들이(top - K) 맞춤 추천 후보 글이 됩니다. 이 CTR 예측 모델의 학습 데이터는 사용자의 피드백(노출, 클릭)데이터를 사용했습니다.

내가 좋아할 만한 글을 찾는 랭킹 과정
개인화 추천을 위한 전통적인 CF 방식은 유저의 피드백 (User X item) 데이터의 행렬 분해 기법을 통해 개인화 추천을 제공합니다. 실제로 여러 서비스를 통해 행렬 분해 기법이 룰, 통계 기반의 개인화 추천보다 높은 성능을 내는 것이 증명되었습니다.

이런 CF 방식을 서비스에 도입하기 위해서는 수백 유저와 아이템수를 커버할 수 있는 규모성(scaliability)과 유저의 피드백을 즉시 반영하는 최신성이 필요합니다.
토로스 추천시스템에서 주로 사용되는 ALS(Alternative Least Square), Word2Vec 같은 CF모델은 분산처리, 증분 학습 그리고 알고리즘 최적화를 통해 대량의 브런치 피드백 데이터를 수분 이내에 학습하고, 이를 추천 시스템에 즉시 적용합니다. 또한 개인화 추천을 요청하는 쿼리 타임에 행렬 분해 연산을 추가로 수행하여 개인화된 추천 결과를 제공합니다. 이렇게 쿼리 타임에 행렬 분해를 수행함으로써 최신의 유저 피드백(취향)이 개인화 추천에 반영됩니다.
여기서 수행하는 행렬 분해 연산은 아래 그림과 같이 사전에 학습된 글(item)의 특징 벡터 값과 최신의 유저 피드백으로 최소 제곱 법(least square)연산을 하게 되는데 이 연산은 많은 비용이 필요합니다. 그래서 토로스 추천 시스템에서는 추천할 글의 수를 줄이기 위해 타겟팅하고, 알고리즘이 최적화된 분산 추론(inference) 서버를 구현하여 이 기능을 제공하고 있습니다.

브런치의 개인화 추천을 위한 전체 과정은 아래 그림과 같이 이루어집니다.
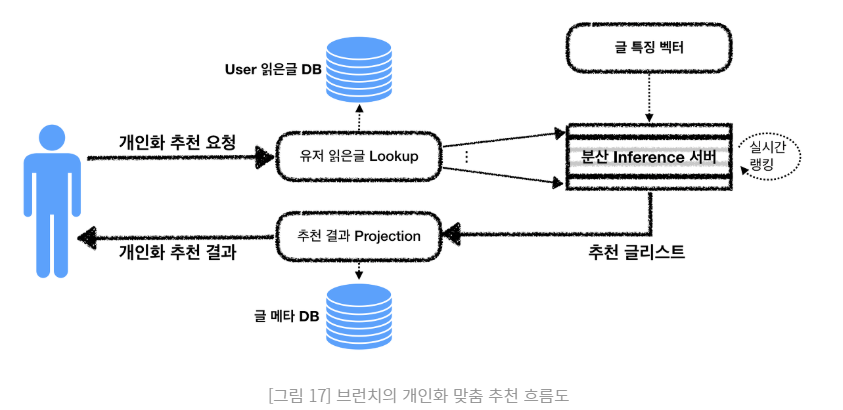
결론 .# 브런치 사용자를 위한 글 추천 대회
'EDA Project > 카카오 아레나' 카테고리의 다른 글
| 브런치 사용자를 위한 글 추천 대회 - 후기 (5) | 2019.09.22 |
|---|---|
| 브런치 사용자를 위한 글 추천 대회 - 모델(2) (0) | 2019.09.22 |
| 브런치 사용자를 위한 글 추천 대회 - 모델(1) (0) | 2019.09.22 |
| 브런치 사용자를 위한 글 추천 대회 - 데이터 탐색(2) (0) | 2019.09.22 |
| 브런치 사용자를 위한 글 추천 대회 (1) | 2019.09.11 |

